
Hyperleger原始碼分析--共識演算法
共識演算法(consensus)
peer節點啟動的時候根據配置檔案core.yaml檔案配置項peer.validator.consensus.plugin選擇採用哪種共識演算法。目前Fabric實現了兩種共識演算法NOOPS和PBFT,預設是NOOPS:
- NOOPS:是一個供開發和測試使用的外掛,會處理所有收到的訊息。
- PBFT:PBFT演算法實現。
0x01 外掛介面
- Consenter
// ExecutionConsumer allows callbacks from asycnhronous execution and statetransfer type ExecutionConsumer interface { Executed(tag interface{}) // Called whenever Execute completes Committed(tag interface{}, target *pb.BlockchainInfo) // Called whenever Commit completes RolledBack(tag interface{}) // Called whenever a Rollback completes StateUpdated(tag interface{}, target *pb.BlockchainInfo) // Called when state transfer completes, if target is nil, this indicates a failure and a new target should be supplied } // Consenter is used to receive messages from the network // Every consensus plugin needs to implement this interface type Consenter interface { RecvMsg(msg *pb.Message, senderHandle *pb.PeerID) error // Called serially with incoming messages from gRPC ExecutionConsumer }
每個共識外掛都需要實現Consenter介面,包括RecvMsg函式和ExecutionConsumer接口裡的函式(可以直接返回)。
Consenter是EngineImpl的一個成員,EngineImpl是介面Engine的一個例項,是在peer啟動的時候建立的,連同Impl的其他成員一起註冊到gRPC服務中。當通過gRPC收到ProcessTransaction訊息時,最終會呼叫Consenter的RecvMsg處理交易資訊。
ExecutionConsumer介面是專門處理事件訊息的,它是Stack的成員Executor的一個介面。coordinatorImpl是Executor的一個例項,在例項化coordinatorImpl的時候同時設定自身為成員變數Manager的事件訊息接收者,然後啟動一個協程迴圈處理接收到的事件,根據不同的事件型別,呼叫ExecutionConsumer的不同函式。特別說明一下,事件在內部是channel實現的生產者/消費者模型,只有一個緩衝區,如果處理不及時會出現訊息等待的情況,在實際產品化過程中需要進行優化。
- Stack
// Stack is the set of stack-facing methods available to the consensus plugin type Stack interface { NetworkStack // 網路訊息傳送和接收介面 SecurityUtils // Sign和Verify介面 Executor // 事件訊息處理介面 LegacyExecutor // 交易處理介面 LedgerManager // 控制ledger的狀態 ReadOnlyLedger // 操作blockchain StatePersistor // 操作共識狀態 }
這個介面的實現都是在helper中實現的,這裡只是統一的抽象出來便於實現共識演算法外掛的時候呼叫。
- newTimerImpl
// timerStart is used to deliver the start request to the eventTimer thread
type timerStart struct {
hard bool // Whether to reset the timer if it is running
event Event // What event to push onto the event queue
duration time.Duration // How long to wait before sending the event
}
// timerImpl is an implementation of Timer
type timerImpl struct {
threaded // Gives us the exit chan
timerChan <-chan time.Time // When non-nil, counts down to preparing to do the event
startChan chan *timerStart // Channel to deliver the timer start events to the service go routine
stopChan chan struct{} // Channel to deliver the timer stop events to the service go routine
manager Manager // The event manager to deliver the event to after timer expiration
}
timerStart指定了幾個引數:timer還未到時間前是否可以重置、訊息佇列、超時時間。timerImpl在初始化的時候,啟動一個協程,迴圈檢測startChan、stopChan、timerChan、event、exit等是否訊息,對timer進行操作,比如停止、重啟等。
- MessageFan
// Message encapsulates an OpenchainMessage with sender information
type Message struct {
Msg *pb.Message
Sender *pb.PeerID
}
// MessageFan contains the reference to the peer's MessageHandlerCoordinator
type MessageFan struct {
ins map[*pb.PeerID]<-chan *Message
out chan *Message
lock sync.Mutex
}
MessageFan類似風扇,把不同PeerID的訊息匯聚到一個通道統一輸出。
0x02 NOOPS
NOOPS是為了演示共識演算法的,要實現一個共識演算法的外掛,可以看看它都實現了哪些功能:
-
GetNoops返回一個外掛物件 NOOPS和PBFT都是單例模式,輸入引數是Stack介面:
// GetNoops returns a singleton of NOOPS func GetNoops(c consensus.Stack) consensus.Consenter { if iNoops != nil { iNoops = newNoops(c) } return iNoops } -
實現Consenter介面 包括RecvMsg、Executed、Committed、RolledBack、StateUpdated等。
NOOPS只實現了RecvMsg介面,處理了Message_CHAIN_TRANSACTION和Message_CONSENSUS訊息。對Message_CHAIN_TRANSACTION訊息的處理就是把訊息型別修改成Message_CONSENSUS再廣播出去,對Message_CONSENSUS訊息的處理就是儲存下來。
0x03 PBFT
PBFT協議
#### 前提假設 #### * 分散式節點通過網路是連線在一起的 * 網路節點發送的訊息可能會丟,可能會延遲到達,也可能會重複,到達順序也可能是亂的
為什麼至少要3f+1個節點
- 最壞的情況是:f個節點是有問題的,由於到達順序的問題,有可能f個有問題的節點比正常的f個節點先返回訊息,又要保證收到的正常的節點比有問題的節點多,所以需要滿足N-f-f>f => N>3f,所以至少3f+1個節點
術語
- client:發出呼叫請求的實體
- view:連續的編號
- replica:網路節點
- primary:主節點,負責生成訊息序列號
- backup:支撐節點
- state:節點狀態
3階段協議
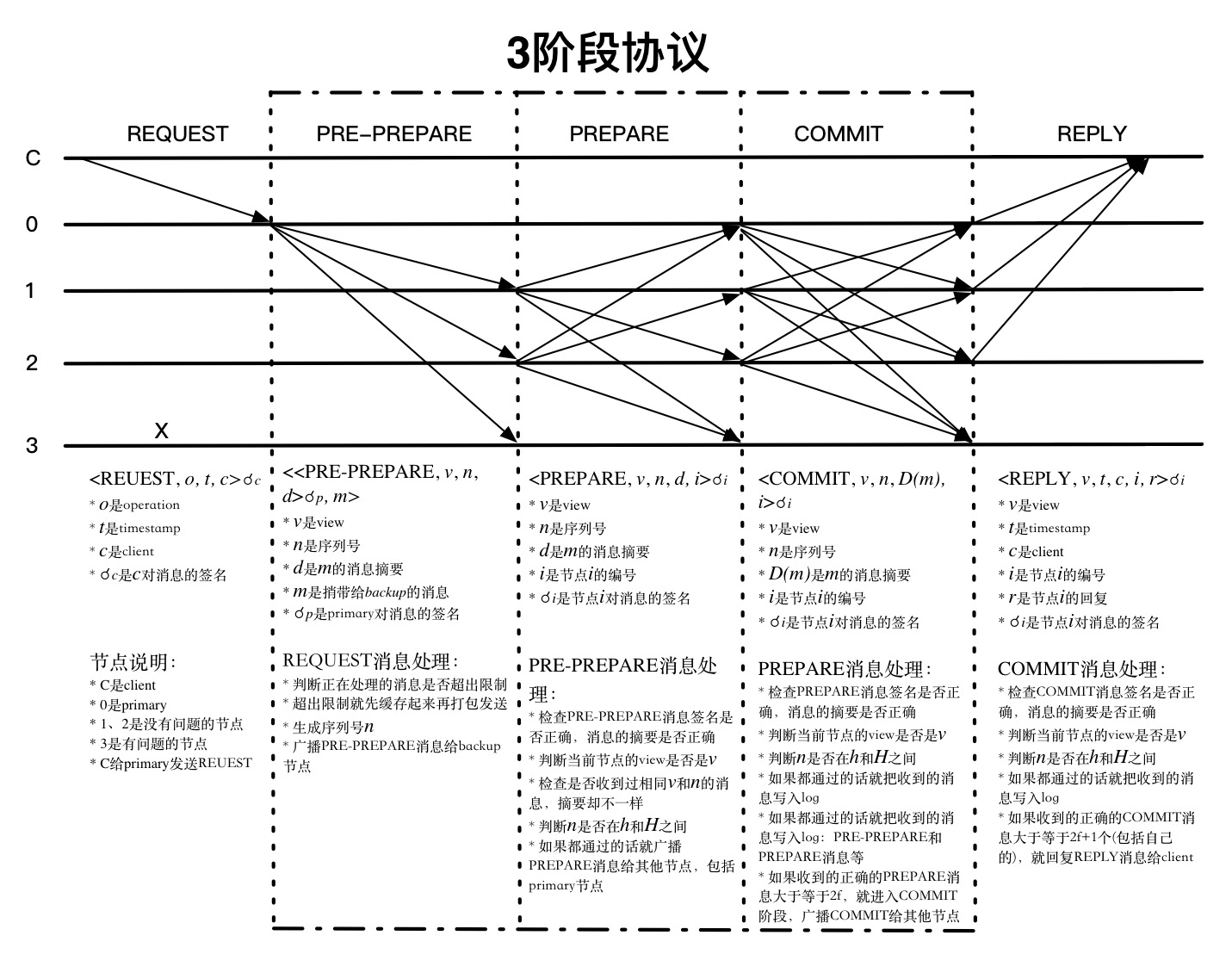
從primary收到訊息開始,每個訊息都會有view的編號,每個節點都會檢查是否和自己的view是相同的,代表是哪個節點發送出來的訊息,源頭在哪裡,client收到訊息也會檢查該請求返回的所有訊息是否是相同的view。如果過程中發現view不相同,訊息就不會被處理。除了檢查view之外,每個節點收到訊息的時候都會檢查對應的序列號n是否匹配,還會檢查相同view和n的PRE-PREPARE、PREPARE訊息是否匹配,從協議的連續性上提供了一定程度的安全。
每個節點收到其他節點發送的訊息,能夠驗證其簽名確認傳送來源,但並不能確認傳送節點是否偽造了訊息,PBFT採用的辦法就是數數,看有多少節點發送了相同的訊息,在有問題的節點數有限的情況下,就能判斷哪些節點發送的訊息是真實的。REQUEST和PRE-PREPARE階段還不涉及到訊息的真實性,只是獨立的生成或者確認view和序列號n,所以收到訊息判斷來源後就廣播出去了。PREPARE階段開始會彙總訊息,通過數數判斷訊息的真實性。PREPARE訊息是收到PRE-PREPARE訊息的節點發送出來的,primary收到REQUEST訊息後不會給自己傳送PRE-PREPARE訊息,也不會發送PRE-PREPARE訊息,所以一個節點收到的訊息數滿足2f+1-1=2f個就能滿足沒問題的節點數比有問題節點多了(包括自身節點)。COMMIT階段primary節點也會在收到PREPARE訊息後傳送COMMIT訊息,所以收到的訊息數滿足2f+1個就能滿足沒問題的節點數比有問題節點多了(包括自身節點)。
PRE-PREPARE和PREPARE階段保證了所有正常的節點對請求的處理順序達成一致,它能夠保證如果PREPARE(m, v, n, i) 是真的話,PREPARE(m’, v, n, j) 就一定是假的,其中j是任意一個正常節點的編號,只要D(m) != D(m’)。因為如果有3f+1個節點,至少有f+1個正常的節點發送了PRE-PREPARE和PREPARE訊息,所以如果PREPARE(m’, v, n, j) 是真的話,這些節點中就至少有一個節點發了不同的PRE-PREPARE或者PREPARE訊息,這和它是正常的節點不一致。當然,還有一個假設是安全強度是足夠的,能夠保證m != m’時,D(m) != D(m’),D(m) 是訊息m的摘要。
確定好了每個請求的處理順序,怎麼能保證按照順序執行呢?網路訊息都是無序到達的,每個節點達成一致的順序也是不一樣的,有可能在某個節點上n比n-1先達成一致。其實每個節點都會把PRE-PREPARE、PREPARE和COMMIT訊息快取起來,它們都會有一個狀態來標識現在處理的情況,然後再按順序處理。而且序列號n在不同view中也是連續的,所以n-1處理完了,處理n就好了。
VIEW-CHANGE
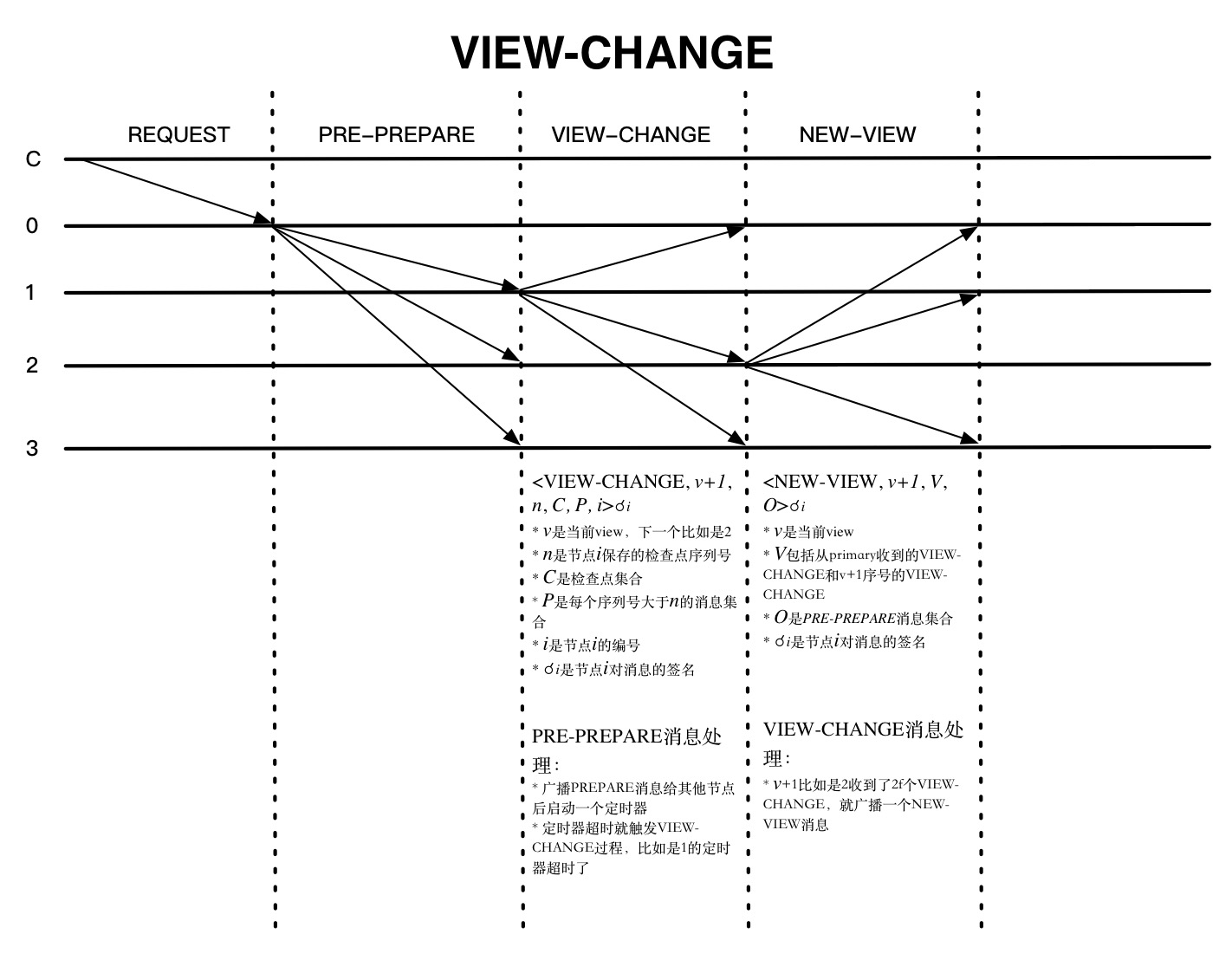
上圖是發生VIEW-CHANGE的一種情況,就是節點正常收到PRE-PREPARE訊息以後都會啟動一個定時器,如果在設定的時間內都沒有收到回覆,就會觸發VIEW-CHANGE,該節點就不會再接收除CHECKPOINT 、VIEW-CHANGE和NEW-VIEW等訊息外的其他訊息了。NEW-VIEW是由新一輪的primary節點發送的,O是不包含捎帶的REQUEST的PRE-PREPARE訊息集合,計算方法如下: * primary節點確定V中最新的穩定檢查點序列號min-s和PRE-PREPARE訊息中最大的序列號max-s * 對min-s和max-s之間每個序列號n都生成一個PRE-PREPARE訊息。這可能有兩種情況: - P的VIEW-CHANGE訊息中至少存在一個集合,序列號是n - 不存在上面的集合
第一種情況,會生成新的PRE-PREPARE訊息<PRE-PREPARE, v+1, n, d>