
為編寫網路爬蟲程式安裝Python3.5

1. 下載Python3.5.1安裝包
1.1 進入python官網,點選menu->downloads,網址:Download Python
1.2 根據系統選擇32位還是64位,這裡下載的可執行exe為64位安裝包
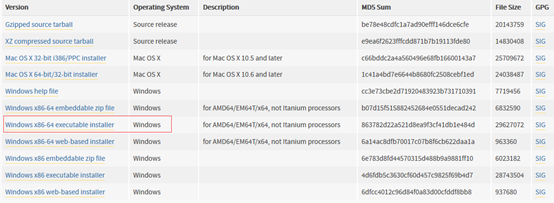
2. 安裝Python3.5
2.1 雙擊開啟安裝包,選擇自定義路徑(注意安裝路徑中儘量不要含有有中文或者空格),然後選中Add Python 3.5 to PATH(將Python安裝路徑新增到系統變數Path中,這樣做以後在任意目錄下都可以執行pyhton命令了)
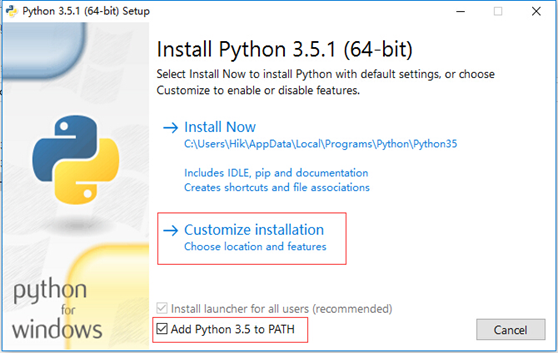
2.2 預設全選,Next
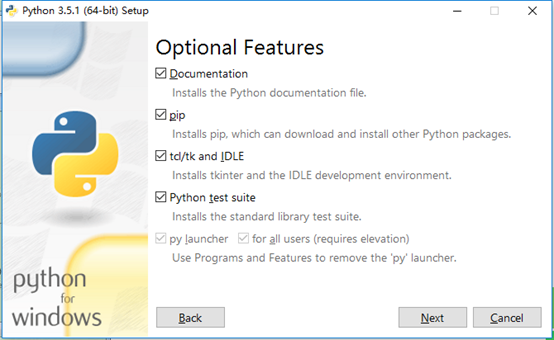
2.3 修改安裝路徑,勾選加上Install for all user為所有使用者安裝和Precompile standard library 預編譯標準庫,然後點選Install
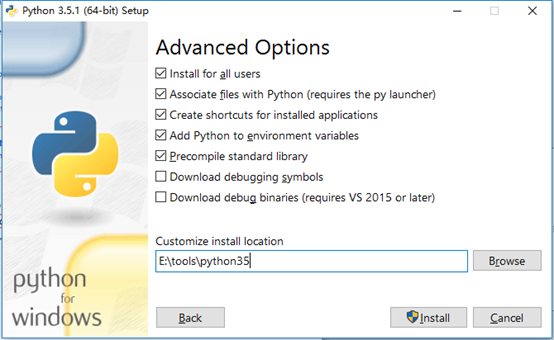
2.4 等待安裝完成
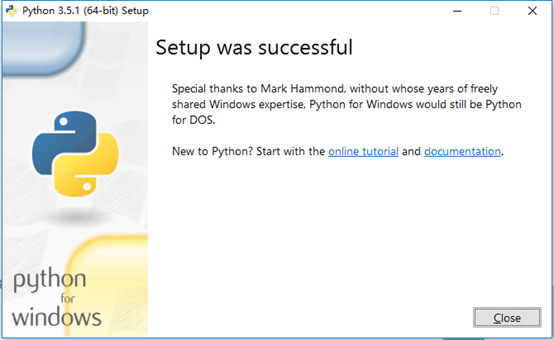
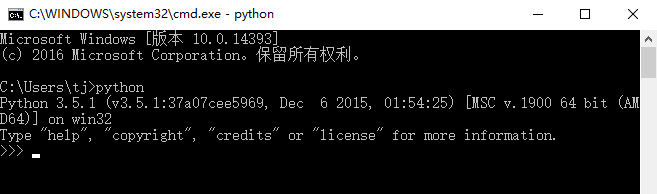
2.5 驗證,使用快捷鍵win + R 或 右鍵開始選擇執行,輸入cmd回車,開啟命令提示符視窗,然後輸入python->回車,若出現python版本資訊則軟體安裝完成
3. 簡單實踐,敲一個簡單小爬蟲程式
3.1 安裝lxml庫,由於直接使用pip lxml 對於3.0x以上的版本來說經常會出現版本不適應而失敗,所以這裡介紹直接使用whl檔案安裝
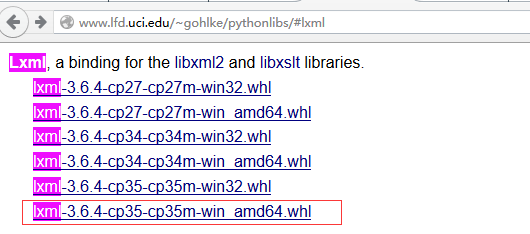
3.1.2 同檢查python是否安裝成功一樣,使用快捷鍵win + R 或 右鍵開始選擇執行,輸入cmd回車,開啟命令提示符視窗,然後
pip install E:\demo\lxml- 可能碰到問題,pip的版本低了,需要更新一下pip的版本。更新pip版本
python -m pip install -U pip更新完成後,再次使用
pippip install E:\demo\lxml-3.6.4-cp35-cp35m-win_amd64.whl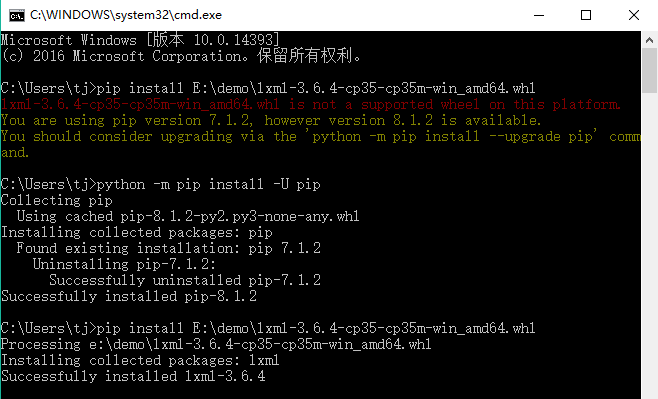
3.2 Lxml庫安裝成功後,環境就準備好了, 可以開始敲程式碼了
3.2.1引入Gooseeker規則提取器模組gooseeker.py(引入該模組的原因和價值),在自定義目錄下建立gooseeker.py檔案,如:這裡為E:\Demo\gooseeker.py,再以記事本開啟,複製下面的程式碼貼上
#!/usr/bin/python
# -*- coding: utf-8 -*-
# 模組名: gooseeker
# 類名: GsExtractor
# Version: 2.0
# 說明: html內容提取器
# 功能: 使用xslt作為模板,快速提取HTML DOM中的內容。
# released by 集搜客(http://www.gooseeker.com) on May 18, 2016
# github: https://github.com/FullerHua/jisou/core/gooseeker.py
from urllib import request
from urllib.parse import quote
from lxml import etree
import time
class GsExtractor(object):
def _init_(self):
self.xslt = ""
# 從檔案讀取xslt
def setXsltFromFile(self , xsltFilePath):
file = open(xsltFilePath , 'r' , encoding='UTF-8')
try:
self.xslt = file.read()
finally:
file.close()
# 從字串獲得xslt
def setXsltFromMem(self , xsltStr):
self.xslt = xsltStr
# 通過GooSeeker API介面獲得xslt
def setXsltFromAPI(self , APIKey , theme, middle=None, bname=None):
apiurl = "http://www.gooseeker.com/api/getextractor?key="+ APIKey +"&theme="+quote(theme)
if (middle):
apiurl = apiurl + "&middle="+quote(middle)
if (bname):
apiurl = apiurl + "&bname="+quote(bname)
apiconn = request.urlopen(apiurl)
self.xslt = apiconn.read()
# 返回當前xslt
def getXslt(self):
return self.xslt
# 提取方法,入參是一個HTML DOM物件,返回是提取結果
def extract(self , html):
xslt_root = etree.XML(self.xslt)
transform = etree.XSLT(xslt_root)
result_tree = transform(html)
return result_tree
# 提取方法,入參是html原始碼,返回是提取結果
def extractHTML(self , html):
doc = etree.HTML(html)
return self.extract(doc)3.2.2 在提取器模組gooseeker.py同級目錄下建立一個.py字尾檔案,如這裡為E:\Demo\first.py,再以記事本開啟,敲入程式碼:
# -*- coding: utf-8 -*-
# 使用gsExtractor類的示例程式
# 訪問集搜客論壇,以xslt為模板提取論壇內容
# xslt儲存在xslt_bbs.xml中
# 採集結果儲存在result.xml中
import os
from urllib import request
from lxml import etree
from gooseeker import GsExtractor
# 訪問並讀取網頁內容
url = "http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
bbsExtra = GsExtractor()
bbsExtra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e" , "gooseeker_bbs_xslt") # 設定xslt抓取規則
result = bbsExtra.extract(doc) # 呼叫extract方法提取所需內容
# 當前目錄
current_path = os.getcwd()
file_path = current_path + "/result.xml"
# 儲存結果
open(file_path,"wb").write(result)
# 打印出結果
print(str(result).encode('gbk','ignore').decode('gbk'))3.2.3 執行first.py,使用快捷鍵win + R 或 右鍵開始選擇執行,輸入cmd回車,開啟命令提示視窗,進入first.py檔案所在目錄,輸入命令 :python first.py 回車
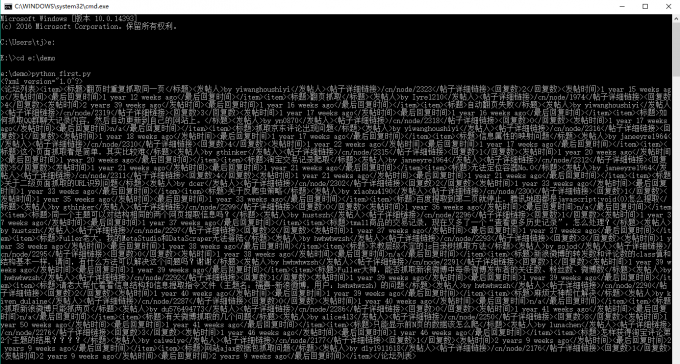
3.2.4 檢視儲存結果檔案,進入first.py檔案所在目錄,檢視名稱為result的xml檔案(即採集結果)
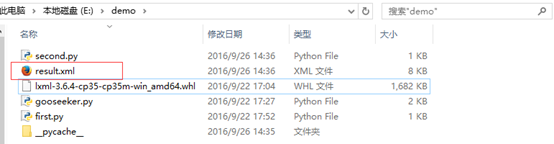
4. 總結
安裝步驟還是很簡單,主要需要注意的是:
1. 對應系統版本安裝;
2. 將安裝路徑加入系統環境變數Path。
後面將會講到如何結合Scrapy快速開發Python爬蟲。
5. 集搜客GooSeeker開原始碼下載源
6.相關文章
7. 文章修改歷史
2016-10-20:V1.0
2016-10-25:補充3.2.1程式碼