
《深入理解Spark》之Spark與Kafka整合原理
spark和kafka整合有2中方式
1、receiver
顧名思義:就是有一個執行緒負責獲取資料,這個執行緒叫receiver執行緒
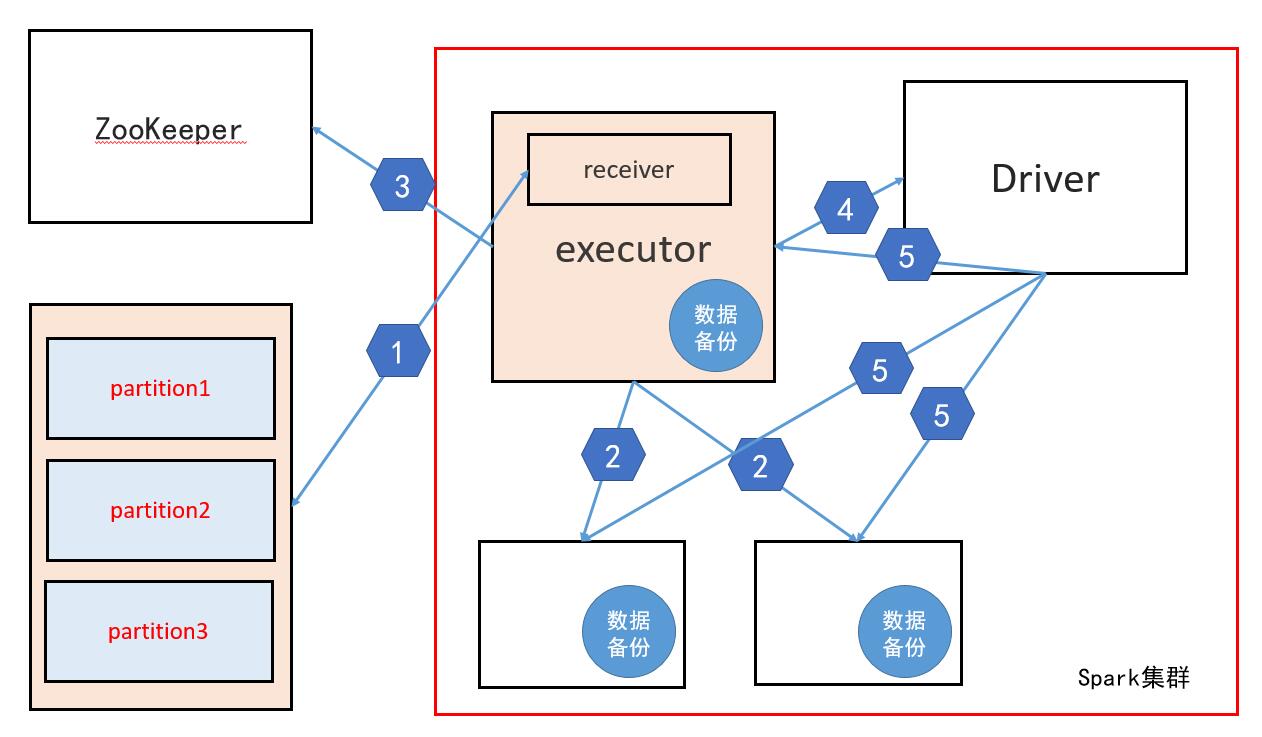
解釋:
1、Spark叢集中的某個executor中有一個receiver執行緒,這個執行緒負責從kafka中獲取資料
注意:這裡的獲取資料並不是從kafka中拉(pull) 而是接收資料,具體原理是該receiver執行緒傳送請求到kafka,這個請求包含對kafka中每個partition的消費偏移量(offset),然後由kafka主動的推送資料到spark中,再有該receiver執行緒負責接收資料
2、當receiver執行緒接收到資料後會做備份處理,即把資料備份到其他的executor中,也可能會備份到這個receiver執行緒所在節點的executor中
3、當備份完畢後該執行緒會把每個partition的消費偏移量在zookeeper中修改,(新版本的kafka的offset 儲存在kafka叢集中)
4、修改完offset後,該receiver執行緒會把"消費"的資料告訴Driver
5、Driver分發任務時會根據每個executor上的資料,根據資料本地性發送
問題:
當第三步執行完後,對於kafka來說這一批資料已經消費完成,那麼如果此時Driver掛掉,那麼這一批資料就會丟失,為了解決這個問題,有一個叫WAL逾寫日誌的概念,即把一部分資料儲存在HDFS上,當Driver回覆後可以從HDFS上獲取這部分資料,但是開啟WAL效能會受到很大的影響
2、dirct
直接連線:即每個executor直接取kafka獲取資料
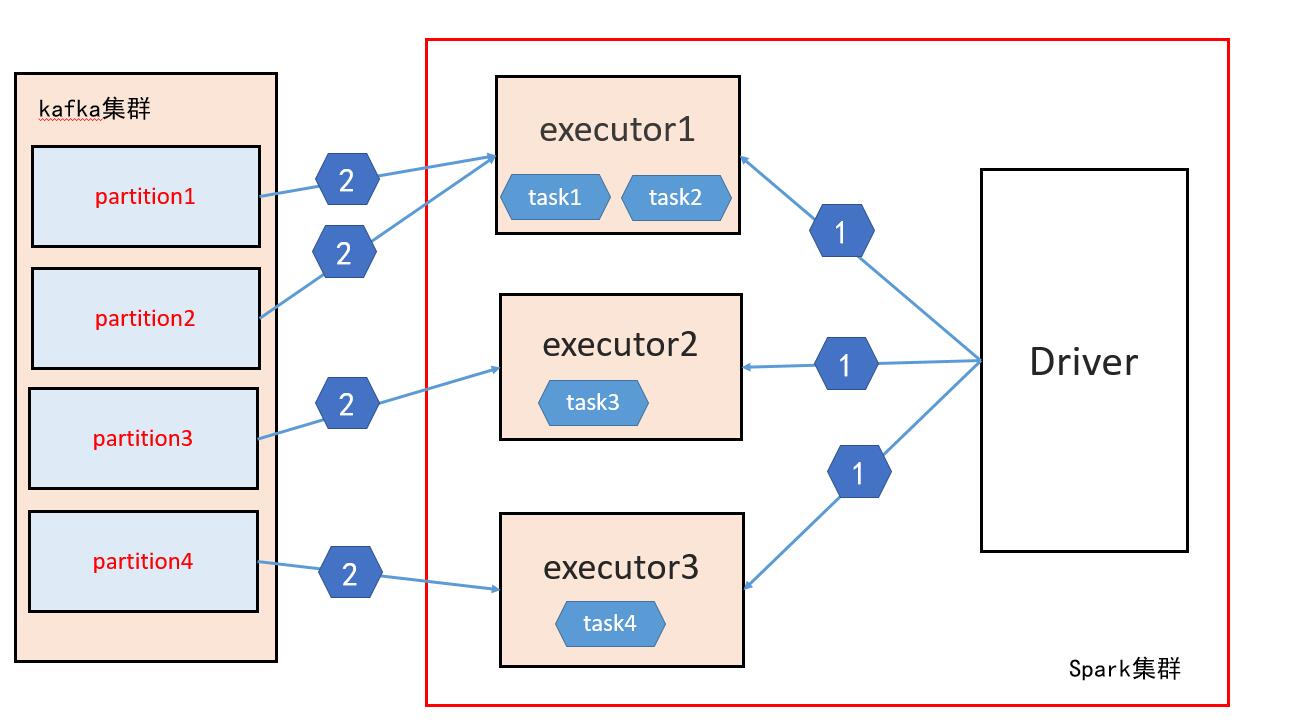
1、首先Driver程式會定時(batchInterval)的向executor中傳送任務(4個)
>> 問題1:Driver怎麼知道要把任務傳送到哪個executor中呢?
>> Driver會呼叫Kafka的介面獲取某個partition位於哪個節點上,根據這個來獲取這些資訊併發送任務到指定的節點,這就類似於Spark叢集處理HDFS上的檔案資料,Spark是可以知道某些檔案的block在那些節點上,就是spark呼叫了HDFS的相關介面
>> 問題2:為什麼是4個任務?
>> 這個個數由消費的topic的partition的個數決定,因為spark會對每個partition開啟一個任務,所以任務數是kafka的某個topic的partition數
2、當每個任務確定了處理那個partition中的資料,則就有任務本身去kafka獲取資料
總結:目前公司中第二種方式使用比較多,這樣也有一個問題就是說當kafka中某個topic加了ACL驗證,那麼這種方式是不能消費加了ACL的topic中的資料,因為kafka客戶端的ACL驗證需要客戶端配置一個環境變數在System的Properties中,在local模式下可以實現,因為local模式下啟動一個虛擬機器例項,即只對應一個System,而在叢集模式下,要啟動多個程序,即啟動多個虛擬機器例項,所以System的全域性屬性沒有辦法配置