
Kafka常用操作命令及生產者與消費者的程式碼實現
檢視當前伺服器中的所有topic
cd /usr/local/kafka/bin
./kafka-topics.sh –list –zookeeper minimaster:2181
建立topic
./kafka-topics.sh –create –zookeeper minimaster:2181 –replication-factor 1 –partitions 1 –topic test2
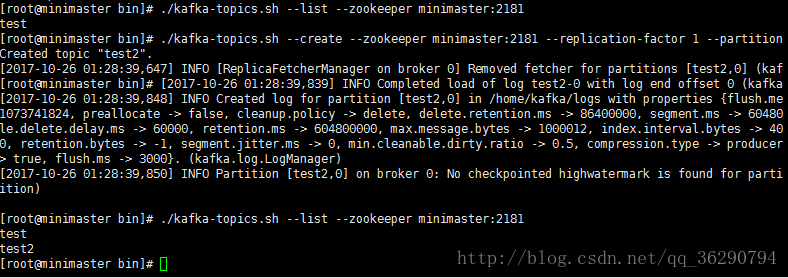
刪除topic
./kafka-topics.sh –delete –zookeeper minimaster:2181 –topic test2
需要server.properties中設定delete.topic.enable=true否則只是標記刪除或者直接重啟。
通過shell命令傳送訊息
./kafka-console-producer.sh –broker-list minimaster:9092 –topic test
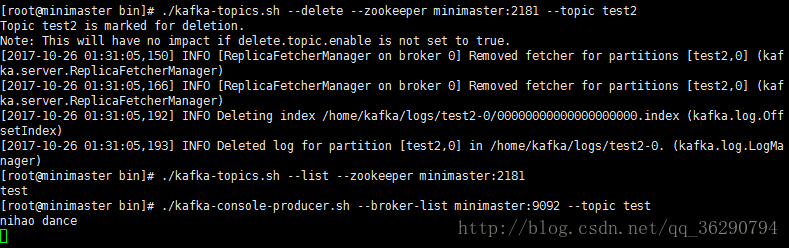
通過shell消費訊息
./kafka-console-consumer.sh –zookeeper minimaster:2181 –from-beginning –topic test
檢視消費位置
./kafka-run-class.sh kafka.tools.ConsumerOffsetChecker –zookeeper minimaster:2181 –group testGroup
檢視某個Topic的詳情
./kafka-topics.sh –topic test –describe –zookeeper minimaster:2181

對分割槽數進行修改
bin/kafka-topics.sh –zookeeper minimaster –alter –partitions 15 –topic utopic
在IDEA上的程式碼實現
kafka生產者
package myRPC.qf.itcast.spark
import java.util.Properties
import kafka.producer.{KeyedMessage, Producer, ProducerConfig}
/**
* 實現一個Producer
* 1.能夠傳送資料到kafka叢集指定的Topic
* 2.實現自定義分割槽器
*/ kafka消費者
package myRPC.qf.itcast.spark
import java.util.Properties
import kafka.consumer._
import kafka.message.MessageAndMetadata
import scala.actors.threadpool.{ExecutorService, Executors}
import scala.collection.mutable
class KafkaConsumerTest(val consumer: String,val stream: KafkaStream[Array[Byte],Array[Byte]]) extends Runnable{
override def run() = {
val it: ConsumerIterator[Array[Byte],Array[Byte]] = stream.iterator()
while(it.hasNext()){
val data: MessageAndMetadata[Array[Byte], Array[Byte]] = it.next()
val topic: String = data.topic
val partition: Int = data.partition
val offset: Long = data.offset
val msg: String = new String(data.message())
println(s"Consumer: $consumer,Topic: $topic,Partition: $partition,Offset: $offset,msg: $msg")
}
}
}
object KafkaConsumerTest{
def main(args: Array[String]): Unit = {
val topic = "test2"
//用來儲存多個Topic
val topics = new mutable.HashMap[String,Int]()
topics.put(topic,2)
//配置檔案資訊
val props = new Properties()
//consumer組id
props.put("group.id","group1")
//指定zookeeper的地址,注意在value裡逗號後面不能有空格
props.put("zookeeper.connect","minimaster:2181,miniSlave1:2181,miniSlave2:2181")
//如果zookeeper沒有offset值或offset值超出範圍,那麼就給個初始的offset
props.put("auto.offset.reset","smallest")
//把配置資訊封裝到ConsumerConfig物件裡
val config: ConsumerConfig = new ConsumerConfig(props)
//建立Consumer,如果沒有資料,會一直執行緒等待
val consumer: ConsumerConnector = Consumer.create(config)
//獲取所有Topic的資料流
val streams: collection.Map[String, List[KafkaStream[Array[Byte], Array[Byte]]]] =
consumer.createMessageStreams(topics)
//獲取Topic為KafkaSimple的資料流
val stream: Option[List[KafkaStream[Array[Byte], Array[Byte]]]] = streams.get(topic)
//建立一個固定大小的執行緒池
val pool: ExecutorService = Executors.newFixedThreadPool(3)
for(i <- 0 until stream.size){
pool.execute(new KafkaConsumerTest(s"Consumer: $i",stream.get(i)))
}
}
}在IDEA上先執行
KafkaProducer.scala,(開啟生產者)顯示結果
執行KafkaConsumer.scala,(開啟消費者)顯示結果:
在Linux上檢視結果:
之後,每執行一次producer,在Linux顯示上會重複新增相對應的內容