
jersey實現restful API提供http服務,實現資源跨程式碼共享
最近產品提了一個新需求,希望做出像淘寶一樣的搜尋框(就是那種輸入一個字,就有一個下拉框給你推薦以這個字開頭的商品名稱,然後隨著你的輸入,變化出不同的提示的那種關聯搜尋框)。至於效果圖的話,嗯,我去扒一張淘寶的圖貼上: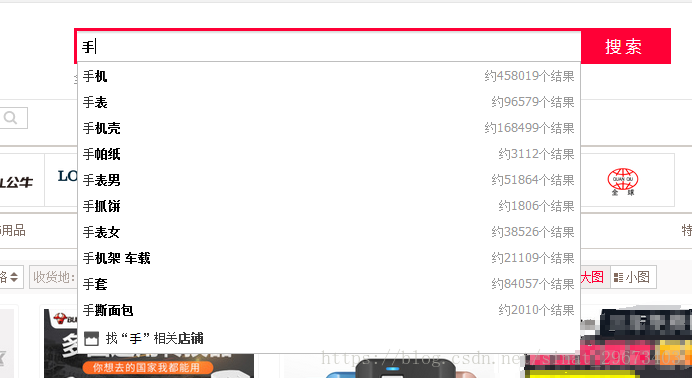
效果就類似這種,當然要想實現這樣的效果,首先你得有個資料庫,裡邊放著這些可以被檢索到的名稱用來備選。在頁面與後端語言進行ajax互動的時候,將符合使用者輸入格式的資料傳輸到前臺顯示,大致就完成了。看起來思路是不是很簡單。但是,有一個不可忽視的問題就是當你需要檢索的資料表過於龐大的時候,前後臺互動所需要的等待時間會變的比較長,影響使用者的使用體驗。那麼怎麼提升資料檢索的效率,縮短檢索時間,讓使用者很順暢的使用搜索框搜尋而感覺不到有資料互動等待的卡頓感。在處理這個問題的時候我選用的是之前已經使用過的lucene來建立關聯資料的索引,根據傳入的使用者搜尋詞獲取不同的匹配資料返回顯示,用來縮短檢索的時間。那麼就會涉及到頁面使用語言php與建立索引所使用的java之間的互動。下面介紹兩種互動的方式供大家參考使用:
1.在php中使用exec()命令執行java jar 將引數以java命令列引數的形式傳入java程式中執行,將輸出存入某個特定的txt檔案中,然後php程式從檔案中將資料讀取出來使用。php執行java命令程式碼如下:
if(!file_exists($file_path)){//如果不存在java輸出的資料檔案,則執行java命令生成資料檔案
$command="java -jar /data/article.jar search ".$this->user_id." ".$time_start." ".$time." ".$file_path;
exec($command);
}這樣就實現了php與java的資料互動。但我覺得有一點點的費勁,非得讀檔案,這多佔硬碟空間啊。就想著是不是還有其他更簡單的方法,於是我就想到實現restful API讓java提供一個http服務,讓php訪問java提供的http介面獲取特定格式的資料。這就是接下來要說的第二種互動方式了
2.使用java的jersey框架實現restful API提供http服務,php程式通過http請求獲取約定格式的資料。jersey框架使用程式碼如下(PS:我沒有使用maven管理依賴包,所以在eclipse中我先從maven伺服器上將jersey的示例程式碼下載下來然後轉成java專案使用的):
首先是啟動http服務監聽特定埠請求的程式碼:
package jersey;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
import java.util.Properties;
import org.glassfish.grizzly.http.server.HttpServer;
import org.glassfish.jersey.grizzly2.httpserver.GrizzlyHttpServerFactory;
import 下面是註冊的根資源類程式碼(因為想要讓裡面的變數在服務執行週期裡被所有使用者共用,而不是每一個連結都生成一個新的物件,將根資源類宣告為單例類即可滿足要求。):
package jersey;
import java.util.List;
import javax.inject.Singleton;
import javax.ws.rs.DefaultValue;
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.QueryParam;
import javax.ws.rs.core.MediaType;
import org.json.simple.JSONArray;
/**
* Root resource (exposed at "myresource" path)
*/
@Singleton//宣告為單例類
@Path("myresource")
public class MyResource {
private Dealer d = null;
private final static String CHARSET_UTF_8 = "charset=utf-8";
public MyResource(){
d = new Dealer();
}
/**
* Method handling HTTP GET requests. The returned object will be sent
* to the client as "APPLICATION_JSON" media type.
*
* @return List that will be returned as a APPLICATION_JSON response.
*/
@GET
@Path("getrelative")
@Produces(MediaType.TEXT_PLAIN + ";" + CHARSET_UTF_8)
public String getRelativeReq(
@QueryParam("keyword") String keywordname,
@DefaultValue("1") @QueryParam("type") int type) {
List<String> result = d.getRelativeTitle(keywordname,type,5);
return JSONArray.toJSONString(result);
}
@GET
@Path("getsearch")
@Produces(MediaType.TEXT_PLAIN + ";" + CHARSET_UTF_8)
public String getSearchReq(
@QueryParam("keyword") String keywordname,
@DefaultValue("1") @QueryParam("type") int type) {
// Dealer d = new Dealer();
List<String> result = d.getRelativeId(keywordname, type, 1000000);
return JSONArray.toJSONString(result);
}
@GET
@Path("dealinfo")
@Produces(MediaType.TEXT_PLAIN + ";" + CHARSET_UTF_8)
public boolean dealInfoReq(@QueryParam("path") String pathname) {
// Dealer d = new Dealer();
boolean result = d.dealIndexInfo(pathname);
return result;
}
@GET
@Path("getUserList")
@Produces(MediaType.TEXT_PLAIN + ";" + CHARSET_UTF_8)
public String getUserList(@DefaultValue("1") @QueryParam("pageIndex") int pageIndex,@DefaultValue("20") @QueryParam("pageSize") int pageSize,@QueryParam("name") String name,@DefaultValue("-1") @QueryParam("type") int type,@QueryParam("business") String business,@DefaultValue("-1") @QueryParam("area_id") int area_id) {
// Dealer d = new Dealer();
LuceneResult result = d.getUserList(pageIndex,pageSize,name,type,business,area_id);
return String.format("{\"total\":%d,\"result\":%s}", result.total, JSONArray.toJSONString(result.result));
}
@GET
@Path("indexInfo")
@Produces(MediaType.TEXT_PLAIN + ";" + CHARSET_UTF_8)
public boolean indexInfo(@QueryParam("path") String path) {
// Dealer d = new Dealer();
boolean result = d.indexInfo(path);
return result;
}
@GET
@Produces(MediaType.TEXT_PLAIN + ";" + CHARSET_UTF_8)
public String sayHello(){
return "Welcome to use Search Optimization!";
}
}
後面就是通過Dealer類進行具體的操作,然後將符合要求的資料返回即可。因為這個關聯搜尋使用lucene作為資料索引,所以對於索引的更新頻率一定要掌握好,而且要採用讀寫分離的方式更新索引,保證索引能夠實時更新但不會影響資料的讀取操作。在這裡我採用的讀寫分離的方法是:索引更新時直接更新的索引存放目錄下的索引檔案,但是在讀取索引中的資料時使用的是記憶體讀取方式,通過記憶體儲存要讀取的索引資料,這樣就算檔案被更改也不會導致資料出錯。在這裡要用到的lucene的兩種Directory:FSDirectory(檔案模式)和RAMDirectory(記憶體模式),在這裡給出這兩種directory的使用場景程式碼:
package jersey;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
/** Index all article.
* <p>生成索引
* This is a command-line application demonstrating simple Lucene indexing.
* Run it with no command-line arguments for usage information.
*/
public class IndexInfo {
private IndexWriter writer = null;
public IndexInfo(boolean create,String path) {
this.initWriter(create,path);
}
/** Index all text files under a directory. */
private void initWriter(boolean create,String path){
String indexPath = path;
Directory dir = null;
try {
dir = FSDirectory.open(Paths.get(indexPath));
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig iwc = new IndexWriterConfig(analyzer);
if (create) {
iwc.setOpenMode(OpenMode.CREATE);
} else {
iwc.setOpenMode(OpenMode.CREATE_OR_APPEND);
}
iwc.setMaxBufferedDocs(1000);
this.writer = new IndexWriter(dir, iwc);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* type
* @param id
* @param type
* @param business
* @param name
* @return
*/
public boolean createUserIndex(String id, int type,String business, String name,String area_id){
//Date start = new Date();
try {
Document doc = new Document();
doc.add(new StringField("all", "1", Field.Store.YES));
doc.add(new StringField("id", id, Field.Store.YES));
doc.add(new StringField("type", Integer.toString(type), Field.Store.YES));
doc.add(new TextField("name", name.toLowerCase(), Field.Store.YES));
doc.add(new TextField("business", business, Field.Store.YES));
doc.add(new StringField("area_id", area_id, Field.Store.YES));
this.writer.addDocument(doc);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// writer.close();
//Date end = new Date();
//System.out.println(end.getTime() - start.getTime() + " total milliseconds");
return true;
}
public boolean createIndex(String id, String title, int type, int time) {
//Date start = new Date();
try {
Document doc = new Document();
Field pathField = new StringField("path", id, Field.Store.YES);
doc.add(pathField);
doc.add(new StringField("type", Integer.toString(type), Field.Store.YES));
doc.add(new StringField("time", Integer.toString(time), Field.Store.YES));
doc.add(new StringField("titleLen", Integer.toString(title.length()), Field.Store.YES));
doc.add(new TextField("title", title.toLowerCase(), Field.Store.YES));
doc.add(new StringField("titleOld", title, Field.Store.YES));
this.writer.addDocument(doc);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// writer.close();
//Date end = new Date();
//System.out.println(end.getTime() - start.getTime() + " total milliseconds");
return true;
}
public void closeWriter(){
try {
this.writer.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
注意:如果需要對索引中儲存的某一欄位進行模糊匹配(切詞匹配)的話,該欄位儲存到索引檔案中需用TextField而非StringField
package jersey;
import java.io.IOException;
import java.nio.file.Paths;
import java.sql.Date;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.IOContext;
import org.apache.lucene.store.RAMDirectory;
public class SearchKeyword {//搜尋索引
private IndexSearcher searcher = null;
private Analyzer analyzer = null;
public SearchKeyword(String path) {
IndexReader reader = null;
try {
//reader = DirectoryReader.open(FSDirectory.open(Paths.get(index)));
FSDirectory fsDirectory = FSDirectory.open(Paths.get(path));
RAMDirectory ramDirectory = new RAMDirectory(fsDirectory, IOContext.READONCE);//使用記憶體讀取資料
fsDirectory.close();
reader = DirectoryReader.open(ramDirectory);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
this.searcher = new IndexSearcher(reader);
this.analyzer = new StandardAnalyzer();
}
public SearchKeyword(Directory dir) {
try {
this.searcher = new IndexSearcher(DirectoryReader.open(dir));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
this.analyzer = new StandardAnalyzer();
}
public TopDocs findKeyword(String field, String keyword) {
try {
QueryParser parser = new QueryParser(field, analyzer);
Query query = parser.parse(keyword);
return searcher.search(query, 100000000);
} catch(Exception e){
e.printStackTrace();
}
return null;
}
public List<Element> getInfo(String keyword,int type){
return this.getInfo(keyword, type,-1, -1);
}
public List<Element> getInfoAll(int timestamp_start, int timestamp_end){
String timeQuery = "";
if(timestamp_start!=-1 && timestamp_end != -1){
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMdd");
timeQuery = String.format("time:[%s TO %s]", sdf.format(new Date(timestamp_start * 1000L)),sdf.format(new Date((timestamp_end - 60*60*12) * 1000L)));
}else
return null;
TopDocs tdocs = findKeyword("title",timeQuery);
List<Element> map = new ArrayList<Element>();
if(tdocs!=null){
for(ScoreDoc hit: tdocs.scoreDocs){
Element element = new Element();
Document doc = null;
try {
doc = searcher.doc(hit.doc);
} catch (IOException e) {
continue;
}
element.setId(doc.get("path"));
element.setTitleLen(Integer.valueOf(doc.get("titleLen")));
element.setType(Integer.valueOf(doc.get("type")));
element.setTime(Integer.valueOf(doc.get("time")));
element.setTitle(doc.get("title"));
map.add(element);
}
}
return map;
}
public List<Element> getInfo(String keyword,int type, int timestamp_start, int timestamp_end){
keyword = keyword.toLowerCase();
String timeQuery = "";
if(timestamp_start!=-1 && timestamp_end != -1){
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMdd");
timeQuery = String.format(" AND time:[%s TO %s]", sdf.format(new Date(timestamp_start * 1000L)),sdf.format(new Date((timestamp_end - 60*60*12) * 1000L)));
}
TopDocs tdocs = findKeyword("title","title:\""+keyword+"\"" + timeQuery+" AND type:\""+type+"\"");
List<Element> map = new ArrayList<Element>();
if(tdocs!=null){
for(ScoreDoc hit: tdocs.scoreDocs){
Element element = new Element();
Document doc = null;
try {
doc = searcher.doc(hit.doc);
} catch (IOException e) {
continue;
}
element.setId(doc.get("path"));
element.setTitleLen(Integer.valueOf(doc.get("titleLen")));
element.setType(Integer.valueOf(doc.get("type")));
element.setTime(Integer.valueOf(doc.get("time")));
element.setTitle(doc.get("titleOld"));
map.add(element);
}
}
return map;
}
public LuceneResult getUserInfo(int pageIndex,int pageSize,String name, int type, String business, int area_id){
StringBuilder sb = new StringBuilder();
sb.append("all:1");
if(name!=null &&name.length()>0){
sb.append(" AND name:\""+name+"\"");
}
if(type!=-1){
if(type==0){
sb.append(" AND (type:0 OR type:3)");
}else
sb.append(" AND type:"+type);
}
if(business!=null &&business.length()>0){
sb.append(" AND business:\""+business+"\"");
}
if(area_id!=-1){
sb.append(" AND area_id:"+area_id);
}
TopDocs tdocs = findKeyword("all",sb.toString());
List<Element> map = new ArrayList<Element>();
if(tdocs!=null){
for(int i = (pageIndex-1)*pageSize; i < pageIndex*pageSize; i++){
if(i==tdocs.scoreDocs.length)
break;
ScoreDoc hit=tdocs.scoreDocs[i];
Element element = new Element();
Document doc = null;
try {
doc = searcher.doc(hit.doc);
} catch (IOException e) {
continue;
}
element.setId(doc.get("id"));
element.setType(Integer.valueOf(doc.get("type")));
map.add(element);
}
}
LuceneResult result = new LuceneResult();
result.total = tdocs.scoreDocs.length;
result.result = map;
return result;
}
}到此,java端的程式碼操作流程就完結了。現在,我們來看看php端如何請求和獲取資料了(java程式碼打的jar包一定放在伺服器上執行然後讓php程式傳送http請求(不要直接在頁面上直接用ajax訪問)啊,不然的話訪問不了的哦~)
public function actionRelative(){
//搜尋關聯詞語
if(!empty($_REQUEST["keyword"])){
$base_url = "http://".SEARCH_SERVER."/searchOp/myresource/getrelative?keyword=".urlencode($_REQUEST['keyword'])."&type=".$_REQUEST['type'];
$this->dies(CurlGet($base_url));//CurlGet()用來發送http請求的
}
}
function CurlGet($url){
//初始化
$ch=curl_init();
//設定選項,包括URL
curl_setopt($ch,CURLOPT_URL,$url);
// 設定header
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
// 設定cURL 引數,要求結果儲存到字串中還是輸出到螢幕上
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
//執行並獲取HTML文件內容
$output=curl_exec($ch);
//釋放curl控制代碼
curl_close($ch);
//列印獲得的資料
//print_r($output);
return $output;
}到這裡就完成了全部功能。使用http服務互動還是蠻方便的~mark一下,與君共勉。