
使用scrapy做爬蟲遇到的一些坑:No module named items以及一些解決方案
阿新 • • 發佈:2019-02-06
最近在學習scrapy,因為官方文件看著比較累,所以看著崔慶才老師寫的部落格來做:https://cuiqingcai.com/3472.html
# -*- coding: utf-8 -*-
import re
import scrapy # 匯入scrapy包
from bs4 import BeautifulSoup
from scrapy.http import Request ##一個單獨的request的模組,需要跟進URL的時候,需要用它
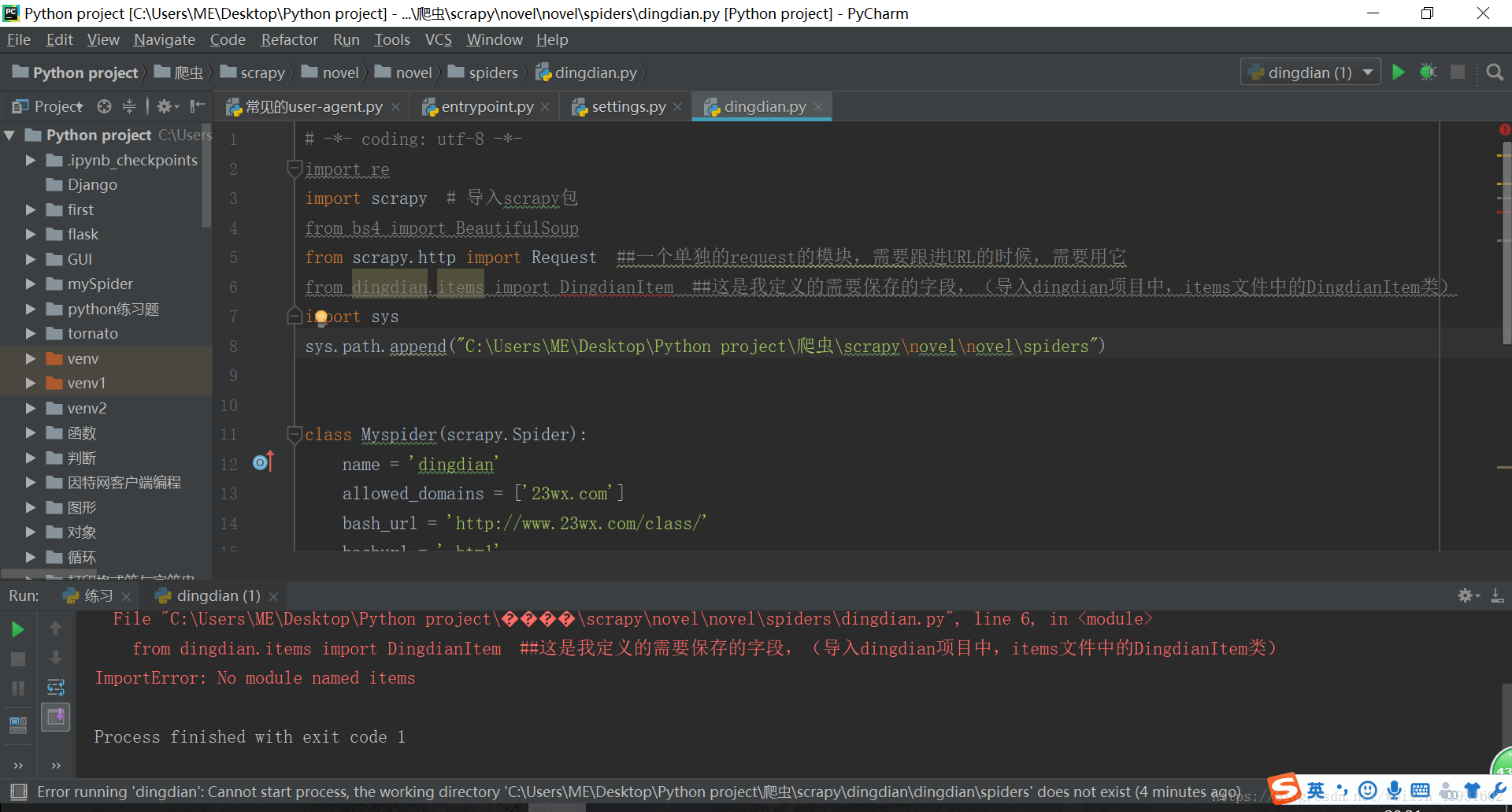
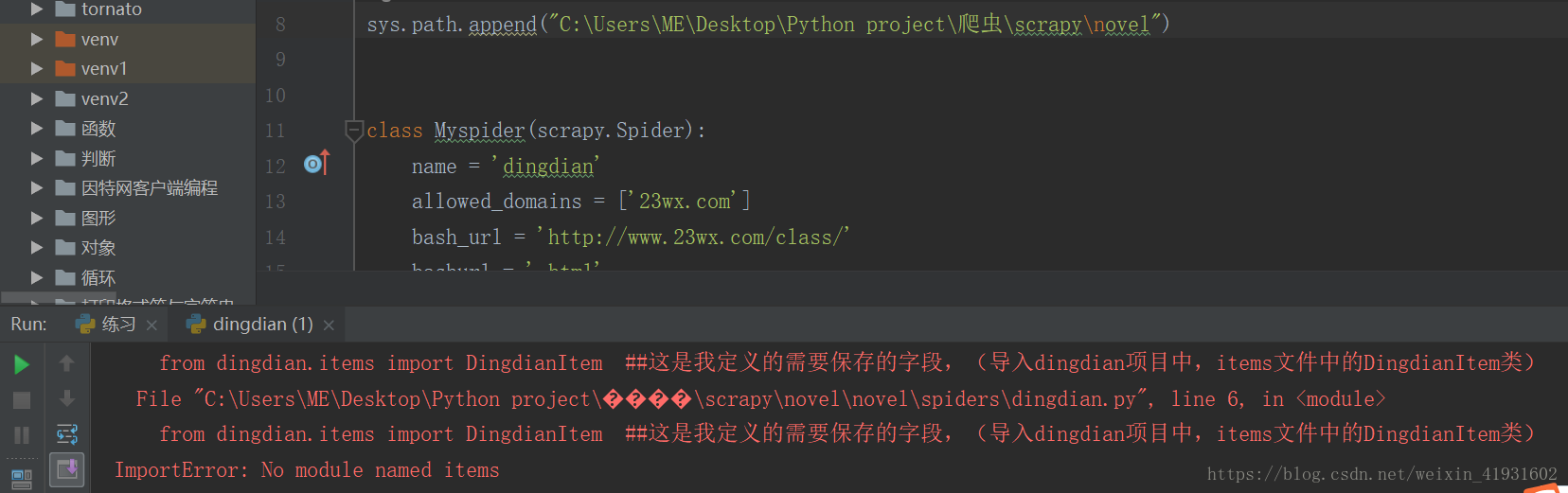
from dingdian.items import DingdianItem ##這是我定義的需要儲存的欄位,(匯入dingdian專案中,items檔案中的DingdianItem類)
class Myspider(scrapy.Spider):
name = 'dingdian'
allowed_domains = ['23wx.com']
bash_url = 'http://www.23wx.com/class/'
bashurl = '.html'
def start_requests(self):
for i in range(1, 11):
url = self.bash_url + str(i) + '_1' + self.bashurl
yield Request(url, self.parse)
yield Request('http://www.23wx.com/quanben/1', self.parse)
def parse(self, response):
print(response.text) 然後在編譯時總會出現No module named items這個問題,找了很久都不知道哪裡出錯。

於是一開始就按照崔老師的做法

還是一樣出錯原因,於是就搜尋了許多可能錯誤的原因,一步步糾正,最後才明白問題所在。在這裡提供一些可能出錯的原因:
1.爬蟲名字和專案名字一樣,導致匯入模組時出錯:改爬蟲或者專案名稱
2.模組不存在:檢查你的專案中的items,看看有沒有出錯
3.模組沒有儲存:在編輯好items模組時,記得執行編譯
4.模組名字和引入的不一樣:自行檢查
5.手動新增自己建立的scrapy資料夾的路徑:例如sys.path.append(r"C:\Users\ME\Desktop\Python project\爬蟲\scrapy\novel")。注意路徑前“”的r
import sys
sys.path.append(檔案路徑)