
計算機字元編碼詳解——從理論到實踐
前言
最近在看《深入理解計算機系統》,讀到“字元編碼”時不禁想起了初學時那段痛苦的歲月,同時又沒找到一篇將理論和實踐結合在一起的文章,為此決定自己寫一份。希望能把我走過的彎路總結出來,能幫助一些還在路上的朋友。
關於計算機如何儲存資訊,請參考《深入理解計算機系統》的第 02 章內容,此文只講解與字元編碼有關的內容。
另外,關於常用編輯器對於字元編碼的區別,請參考我的另一篇文件——《Win記事本、Sublime、Notepad++等編輯器對常見字元編碼的處理和區別:GB2312、GBK、ANSI、Unicode、UTF-8》,此處也不再贅述。
字元的表示原理
簡單說,計算機內所有資訊都是使用0和1進行表示的二進位制數字,我們對這些數字進行編碼和解碼,我們就能用它來表示我們想要表示的東西了。比如:文字、影象、視訊等等,就是一組0和1的二進位制序列。
二進位制數的每一個位表示一個計算機位(bit,簡稱位),8個位組成一個位元組(byte)。那麼一個位元組可以表示256種含義(2*2*2*2*2*2*2*2=256)。
雖然機器是基於二進位制的,但對人類來說,因為二進位制數太長了,需要做精簡。因此需要將其轉換成十六進位制(hexadecimal,簡稱hex)。轉換方式很簡單,使用“8421法”將四位二進位制數轉換成十六進位制數的一位,比如:1010(binary)會轉為A(hex)。在 C 語言中,十六進位制數以”0x”或“0X”開頭,A表示10,F表示16。
此後,00000000~11111111就可以用0x00~0xFF來表示了。
常見的字元編碼
ANSI是美國國標的英文字元編碼,佔用一個位元組,收錄了127個字元。
原理很簡單,用一個位元組的不同的值表示一個字元、字母或數字。
文字開頭有不可見的標誌碼,用於告知下文應該以什麼方式解碼。
文中所有字元編碼都是這種方式。
英文字元編碼佔用一個位元組就夠了,但對於像中文、日文這種象形文字國家一個位元組就肯定不夠了。為此,中國的國標字元編碼需要佔用 2 個位元組,中國標準局依次釋出了GB2312、GBK、GB18030等。
雖然每個國家或地區的字元編碼自行搞定了,但是多個國家間還是不能相容。為此Unicode編碼應運而生,它整合全世界的幾乎所有語言文字。
下面我們依次講解下ANSI、GB2312、GBK、GB18030、Unicode、UTF-8等編碼。
ANSI編碼
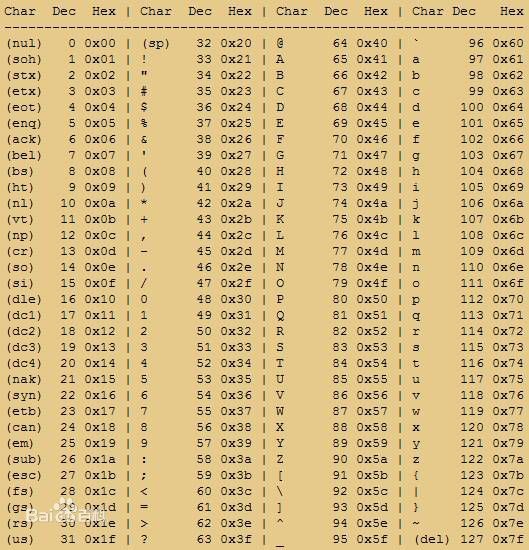
ANSI碼佔用1個位元組,收錄127個字元,取值範圍0x00~0x7F。
ANSI編碼表:
GB2312、GBK、GB18030
釋出順序依次為:GB2312、GBK、GB18030。都以ANSI格式儲存。
彼此區別:
- GB2312是常用簡體漢字;
- GBK基於GB2312,包含更多生僻字,支援簡繁雙體;
- GB18030基於GBK,包含更多生僻字,支援少數民族文字,支援
CJK(中日韓)統一字元。 - GB2312和GBK都是雙位元組,GB18030分單、雙、四位元組三個部分。
比如:在GB2312上沒有“喆”,在GBK上才被收錄。
因這三種編碼規則差不多,下面我們重點講解下GB2312。
GB2312
考慮到以下因素:
- ANSI範圍是:0x00~0x7F。
- 國際通用精確數字計算使用的BCD編碼範圍是:0x00~0x99。
為避免衝突,要預留一定空間,GB2312的範圍:0xA0~0xFF。
GB2312:
- 又稱GB0,國標局釋出,1981年5月1日實施。
- 收錄6763個漢字:一級漢字3755個,常用字,排在前面;二級漢字3008個,生僻字,排在後面。
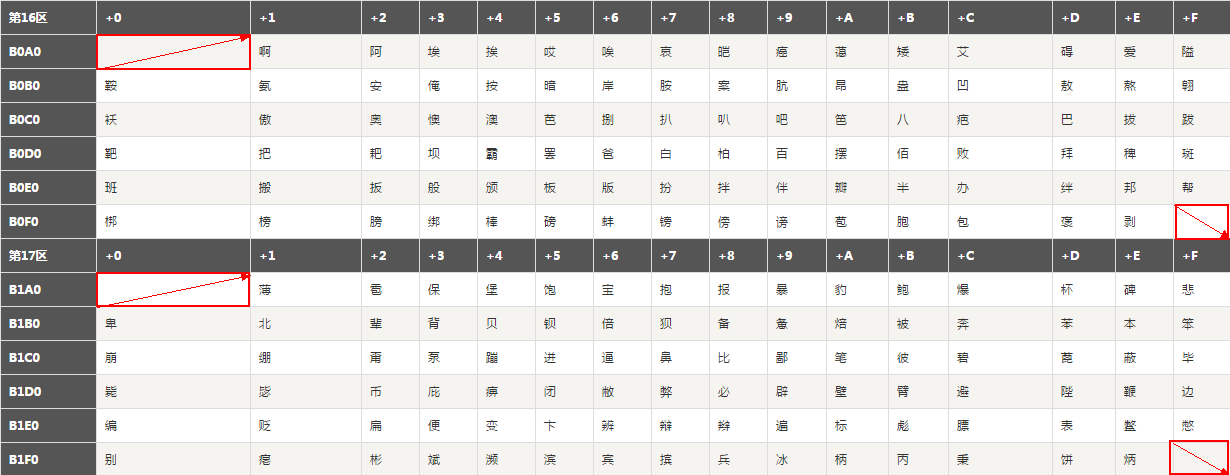
- GB2312是一種區位碼。分為94個區(01-94),每區94個字元(01-94)。
- 01-09區為特殊符號;
- 10-15區沒有編碼;
- 16-55區為一級漢字,按拼音排序,共3755個;
- 56-87區為二級漢字,按部首/筆畫排序,共3008個;
- 88-94區沒有編碼;
- GB2312只是編碼表,在計算機中通常都是用”
EUC-CN“表示法,即在每個區位加上0xA0來表示。區和位分別佔用一個位元組。
EUC-CN表示法:
- EUC-CN是GB2312最常用的表示方法。
- GB2312字元使用兩個位元組來表示, 每個位元組=0xA0+區位碼。
- “第一位位元組”取值範圍:0xB0~0xF7。
- “第二位位元組”取值範圍:0xA1~0xFE。
舉例來說,“啊”字是GB 2312之中的第一個漢字,它的區位碼是1601。
在EUC-CN之中,它把0xA0+16=0xB0;0xA0+1=0xA1;得出0xB0A1。
GB2312的中文區位的首末兩位是特意空出來的。原因是:
- 首位(0x00):在ANSI中表示空,中國人更習慣從1開始計數,而不是從0開始計數。
- 末位(0xFF):代表結束,因為有些程式設計師會將其定義為空,因此空出以避免衝突。
GB2312中文編碼頁的排列方式:
《關於Windows記事本與Sublime Text對中文字元編碼轉換的問題》:
先對Windows記事本做個小實驗:
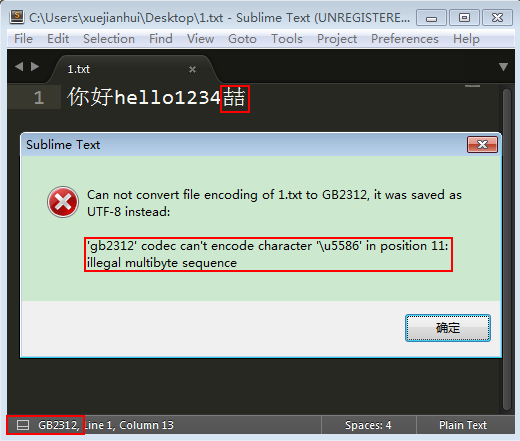
- 在Windows記事本中,新建檔案,輸入“你好hello1234”,以ANSI格式儲存後;
在Sublime Text中開啟此檔案,檔案格式為GB2312,輸入GB2312內不支援的漢字“喆”,提示儲存失敗,原因是’\u5586’是非法的多位元組序列;
’gb2312’ codec can’t encode character ‘\u5586’ in position 11: illegal multibyte sequence
第 11 個字元就是“喆”。
注意:如果不刪除這個欄位,Sublime Text會以UTF-8格式重新儲存這個檔案。在Windows記事本中,輸入GB2312內不支援的漢字“喆”,按ANSI格式儲存成功;
- 再次用Sublime Text開啟此檔案,檔案格式已變為GBK。
綜上,在Windows記事本中,GB2312和GBK是統一以ANSI方式管理的。我猜測,Windows記事本預設使用GB2312儲存漢字,如遇到GB2312不能識別的生僻字才會使用GBK格式儲存。
Sublime Text並不支援這種功能,如果你強行輸入“喆”字以後,會有錯誤框彈出。然後,它會把這個檔案轉換為UTF-8格式並儲存。
因為Sublime Text預設是支援UTF-8編碼,不支援GB2312、GBK等中文編碼,需要安裝ConvertToUTF-8外掛才能實現。顯然,ConvertToUTF-8並沒考慮這種情況。在Sublime Text中以GB2312格式無法儲存沒被收錄的字元:
Unicode簡介:
- 統一碼、萬國碼、單一碼,包括字符集、編碼方案等。
- 它為每種語言中的每個字元設定了統一併且唯一的二進位制編碼,以滿足跨語言、跨平臺進行文字轉換、處理的要求。
- 1990年開始研發,1994年正式公佈。
- 統一碼為每個字元而非字形定義唯一的編碼(即一個整數),字型視覺展示由其他軟體來處理。由此,可解決漢字一字多形的認定爭議(如“ɑ/a”、“戶/戶/戸”等)。
Unicode與UCS:
統一編碼聯盟都試圖獨立建立一套國際通用的字元編碼,此後雙方都意識到沒必要建立兩套編碼,於是兩者融合並承諾彼此相容。從Unicode 2.0開始,Unicode採用了與ISO 10646-1相同的字型檔和字碼。
通用字符集(Universal Character Set, UCS):由ISO制定的ISO 10646(或稱ISO/IEC 10646)標準所定義的標準字符集。UCS-2用兩個位元組編碼,UCS-4用4個位元組編碼。簡單說,Unicode與UCS-2相同。
Unicode編碼原理:
UCS-4有4個位元組:
- 第一個位元組:表示組(group),最高位為0,則有128個。
- 第二個位元組:表示平面(plane),256個。
- 第三個位元組:表示行(row),256個。
- 第四個位元組:表示碼位(cell),256個。
group 0的是最底層的平面0被稱作BMP(Basic Multilingual Plane),即0x0000XXXX(大寫X表示任何一個十六進位制數字)。
| 平面 | 字元範圍 | 備註 |
|---|---|---|
| 基本多語言平面 | 0~0xFFFF | BMP, or Plane 0 |
| 增補多語言平面 | 0x10000~0x1FFFF | SMP, or Plane 1 |
| 增補表意字元平面 | 0x20000~0x2FFFF | SIP, or Plane 2 |
| 增補專用平面 | SSP, or Plane 14 |
注意:
- BMP:Basic Multilingual Plan
- SMP:Supplementary Multilingual Plane
- SIP:Supplementary Ideographic Plane
- SSP:Supplementary Special-purpose Plane
當UCS-4的前兩個位元組為全零(BMP)時,那麼去掉UCS-4的前兩個零位元組就得到了UCS-2。
在Unicode中,有幾種方式唯一編碼數字的轉換格式:UTF-8、UTF-16、UTF-32。
UTF(Unicode Transformation Format),可以翻譯成Unicode字符集轉換格式,即怎樣將Unicode定義的數字轉換成程式資料。
例如,“漢字”對應的數字是0x6c49和0x5b57,而編碼的程式資料是:
char data_utf8[]={0xE6,0xB1,0x89,0xE5,0xAD,0x97}; //UTF-8編碼
char16_t data_utf16[]={0x6C49,0x5B57}; //UTF-16編碼
char32_t data_utf32[]={0x00006C49,0x00005B57}; //UTF-32編碼注: char16_t 和 char32_t 是 C++ 11 標準新增的關鍵字。如果你的編譯器不支援 C++ 11 標準,請改用 unsigned short 和 unsigned long。
“漢字”的UTF-8編碼需要6個位元組。
“漢字”的UTF-16編碼需要兩個char16_t,大小是4個位元組。
“漢字”的UTF-32編碼需要兩個char32_t,大小是8個位元組。
UTF-8
| Unicode編碼(十六進位制) | UTF-8 位元組流(二進位制) |
|---|---|
| 00000000 - 0000007F | 0xxxxxxx |
| 00000080 - 000007FF | 110xxxxx 10xxxxxx |
| 00000800 - 0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 00010000 - 001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 00200000 - 03FFFFFF | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 04000000 - 7FFFFFFF | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
UTF-8的特點是對不同範圍的字元使用不同長度的編碼,相容ASCII編碼。
- 對於0x00-0x7F之間的字元,UTF-8編碼與ASCII編碼完全相同。
- UTF-8編碼的最大長度是6個位元組。
- 從上表可以看出,6位元組模板有31個x,即可以容納31位二進位制數字。Unicode的最大碼位0x7FFFFFFF也只有31位。
例1:
“漢”的Unicode編碼是0x6C49,在0x0800-0xFFFF之間,使用3位元組模板:1110xxxx 10xxxxxx
10xxxxxx。 0x6C49的二進位制表示為:0110 1100 0100 1001,
用這個位元流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
例2:Unicode編碼0x20C30在0x010000-0x10FFFF之間,使用4位元組模板:11110xxx 10xxxxxx
10xxxxxx 10xxxxxx。將0x20C30寫成21位二進位制數字(不足21位就在前面補0):0 0010 0000 1100
0011 0000,用這個位元流依次代替模板中的x,得到:11110000 10100000 10110000 10110000,即F0
A0 B0 B0。
UTF-16
根據位元組序的不同,UTF-16可以被實現為UTF-16BE或UTF-16LE(Windows系統預設)。
Win32的API提供兩種呼叫方式:
- 以W結尾的函式:使用UTF-16LE編碼模式;
- 以A結尾的函式:使用多位元組編碼模式(中文編碼是以ANSI格式儲存的),但是Windows會在底層將其轉換為UTF-16LE編碼來處理。
因此對於Windows程式設計來說,最好預設使用Unicode(UTF-16LE)模式開發,避免系統底層多餘的字元轉換。
| Unicode字元編碼範圍 | UTF-16 單個字元長度 | 備註 |
|---|---|---|
| U+0000~U+FFFF | 1個16位編碼單元 | 16位無符號整數,固定寬度,BMP中的字元 |
| U+10000~U+10FFFF | 2個16位編碼單元 | 稱作代理對(surrogate pair),變寬 |
UTF-16是早期Unicode遺留下的歷史產物,原本被設計成具有固定寬度的16位編碼格式。為支援超過U+FFFF的增補字元,設立了代理機制。
編碼轉化規則
UTF-16編碼以16位無符號整數為單位。我們把Unicode編碼記作U。編碼規則如下:
- 如果U<0x10000,U的UTF-16編碼就是U對應的16位無符號整數。
- 如果U≥0x10000,
- 我們先計算U’=U-0x10000,
- 然後將U’寫成二進位制形式:yyyy yyyy yyxx xxxx xxxx,
- U的UTF-16編碼(二進位制)就是:110110yyyyyyyyyy 110111xxxxxxxxxx。
為什麼U’可以被寫成20個二進位制位?
Unicode的最大碼位是0x10FFFF,減去0x10000後,U’的最大值是0xFFFFF,2的5次冪是32,所以肯定可以用20個二進位制位表示。
例如:Unicode編碼0x20C30,減去0x10000後,得到0x10C30,寫成二進位制是:0001 0000 1100 0011
0000。用前10位依次替代模板中的y,用後10位依次替代模板中的x,就得到:1101100001000011
1101110000110000,即0xD843 0xDC30。
UTF-32
根據位元組序的不同,UTF-32可以被實現為UTF-32LE或UTF-32BE。
UTF-32是一種最簡單的Unicode編碼格式。每個Unicode碼點被直接表示為一個32位的編碼單元。UTF-32是一種固定寬度的字元編碼格式。
每個UTF-32編碼單元的值與Unicode碼點的值完全相同。
因為對於多數情況下,非常浪費空間,因此應用場景很少。