
關於Hive優化總結
阿新 • • 發佈:2019-02-07
問題導讀:
1、Hive整體架構優化點有哪些?
2、如何在MR階段進行優化?
3、Hive在SQL中如何優化?
4、Hive框架平臺中如何優化?

一、整體架構優化
現在hive的整體框架如下,計算引擎不僅僅支援Map/Reduce,並且還支援Tez、Spark等。根據不同的計算引擎又可以使用不同的資源排程和儲存系統。
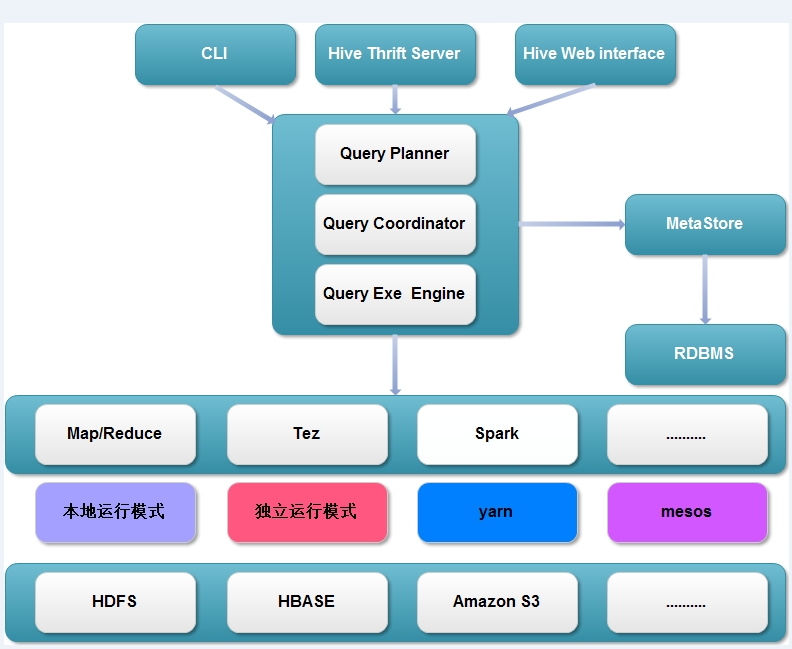
整體架構優化點:
1、根據不同業務需求進行日期分割槽,並執行型別動態分割槽。
相關引數設定:
0.14中預設hive.exec.dynamic.partition=ture
2、為了減少磁碟儲存空間以及I/O次數,對資料進行壓縮
相關引數設定:
job輸出檔案按照BLOCK以Gzip方式進行壓縮。
[AppleScript] 純文字檢視
map輸出結果也以Gzip進行壓縮。
[AppleScript] 純文字檢視 複製程式碼?
對hive輸出結果和中間結果進行壓縮。
[AppleScript] 純文字檢視 複製程式碼?
3、hive中間表以SequenceFile儲存,可以節約序列化和反序列化的時間
相關引數設定:
hive.query.result.fileformat=SequenceFile
4、yarn優化,在此不再展開,後面專門介紹。
二、MR階段優化
hive操作符有:

執行流程為:
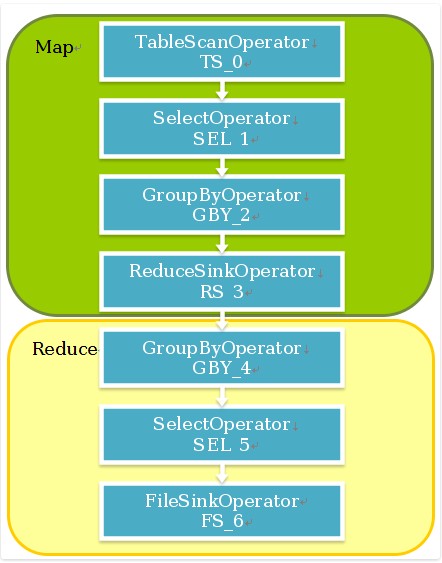
reduce切割演算法:
相關引數設定,預設為:
hive.exec.reducers.max=999
hive.exec.reducers.bytes.per.reducer=1G
reduce task num=min{reducers.max,input.size/bytes.per.reducer},可以根據實際需求來調整reduce的個數。
三、JOB優化
1、本地執行
預設關閉了本地執行模式,小資料可以使用本地執行模式,加快執行速度。
相關引數設定:
hive.exec.mode.local.auto=true
預設本地執行的條件是,hive.exec.mode.local.auto.inputbytes.max=128MB, hive.exec.mode.local.auto.tasks.max=4,reduce task最多1個。 效能測試:
資料量(萬) 操作 正常執行時間(秒) 本地執行時間(秒)
170 group by 36 16
80 count 34 6
2、mapjoin
預設mapjoin是開啟的, hive.auto.convert.join.noconditionaltask.size=10MB
裝載到記憶體的表必須是通過scan的表(不包括group by等操作),如果join的兩個表都滿足上面的條件,/*mapjoin*/指定表格不起作用,只會裝載小表到記憶體,否則就會選那個滿足條件的scan表。
四、SQL優化
整體的優化策略如下:
五、平臺優化
1、hive on tez

2、spark SQL大趨勢
總結
上面主要介紹一些優化思想,有些優化點沒有詳細展開,後面分別介紹yarn的優化細節、SQL詳細的優化例項以及我們在Tez、spark等框架優化結果。最後用一句話共勉:邊coding,邊優化,優化無止境。
1、Hive整體架構優化點有哪些?
2、如何在MR階段進行優化?
3、Hive在SQL中如何優化?
4、Hive框架平臺中如何優化?
一、整體架構優化
現在hive的整體框架如下,計算引擎不僅僅支援Map/Reduce,並且還支援Tez、Spark等。根據不同的計算引擎又可以使用不同的資源排程和儲存系統。
整體架構優化點:
1、根據不同業務需求進行日期分割槽,並執行型別動態分割槽。
相關引數設定:
0.14中預設hive.exec.dynamic.partition=ture
2、為了減少磁碟儲存空間以及I/O次數,對資料進行壓縮
相關引數設定:
job輸出檔案按照BLOCK以Gzip方式進行壓縮。
[AppleScript] 純文字檢視
| 123 | mapreduce.output.fileoutputformat.compress=truemapreduce.output.fileoutputformat.compress.type=BLOCKmapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.GzipCodec |
map輸出結果也以Gzip進行壓縮。
[AppleScript] 純文字檢視 複製程式碼?
| 12 | mapreduce.map.output.compress=truemapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.GzipCodec |
對hive輸出結果和中間結果進行壓縮。
[AppleScript] 純文字檢視 複製程式碼?
| 12 | hive.exec.compress.output=truehive.exec.compress.intermediate=true |
3、hive中間表以SequenceFile儲存,可以節約序列化和反序列化的時間
相關引數設定:
hive.query.result.fileformat=SequenceFile
4、yarn優化,在此不再展開,後面專門介紹。
二、MR階段優化
hive操作符有:
執行流程為:
reduce切割演算法:
相關引數設定,預設為:
hive.exec.reducers.max=999
hive.exec.reducers.bytes.per.reducer=1G
reduce task num=min{reducers.max,input.size/bytes.per.reducer},可以根據實際需求來調整reduce的個數。
三、JOB優化
1、本地執行
預設關閉了本地執行模式,小資料可以使用本地執行模式,加快執行速度。
相關引數設定:
hive.exec.mode.local.auto=true
預設本地執行的條件是,hive.exec.mode.local.auto.inputbytes.max=128MB, hive.exec.mode.local.auto.tasks.max=4,reduce task最多1個。 效能測試:
資料量(萬) 操作 正常執行時間(秒) 本地執行時間(秒)
170 group by 36 16
80 count 34 6
2、mapjoin
預設mapjoin是開啟的, hive.auto.convert.join.noconditionaltask.size=10MB
裝載到記憶體的表必須是通過scan的表(不包括group by等操作),如果join的兩個表都滿足上面的條件,/*mapjoin*/指定表格不起作用,只會裝載小表到記憶體,否則就會選那個滿足條件的scan表。
四、SQL優化
整體的優化策略如下:
- 去除查詢中不需要的column
- Where條件判斷等在TableScan階段就進行過濾
- 利用Partition資訊,只讀取符合條件的Partition
- Map端join,以大表作驅動,小表載入所有mapper記憶體中
- 調整Join順序,確保以大表作為驅動表
- 對於資料分佈不均衡的表Group by時,為避免資料集中到少數的reducer上,分成兩個map-reduce階段。第一個階段先用Distinct列進行shuffle,然後在reduce端部分聚合,減小資料規模,第二個map-reduce階段再按group-by列聚合。
- 在map端用hash進行部分聚合,減小reduce端資料處理規模。
五、平臺優化
1、hive on tez
2、spark SQL大趨勢
總結
上面主要介紹一些優化思想,有些優化點沒有詳細展開,後面分別介紹yarn的優化細節、SQL詳細的優化例項以及我們在Tez、spark等框架優化結果。最後用一句話共勉:邊coding,邊優化,優化無止境。