
分散式快取服務Tair的熱點資料雜湊機制
作者:劉歡(淺奕)

1 問題背景
分散式快取一般被定義為一個數據集合,它將資料分佈(或分割槽)於任意數目的叢集節點上。叢集中的一個具體節點負責快取中的一部分資料,整體對外提供統一的訪問介面[1]。分散式快取一般基於冗餘備份機制實現資料高可用,又被稱為記憶體資料網格(IMDG, in-memory data grid)。在雲平臺飛速發展的今天,作為提升應用效能的重要手段,分散式快取技術在工業界得到了越來越廣泛的關注和研發投入[2]。彈性快取平臺[3]是分散式快取叢集在雲端計算場景下的新形態,其強調叢集的動態擴充套件性與高可用性。動態擴充套件性表達了快取平臺可提供透明的服務擴充套件的能力,高可用性則表達了快取平臺可以容忍節點失效。
Tair是阿里巴巴集團自研的彈性快取/儲存平臺,在內部有著大量的部署和使用。Tair的核心元件是一個高效能、可擴充套件、高可靠的NoSQL儲存系統。目前支援MDB、LDB、RDB等儲存引擎。其中MDB是類似Memcached的記憶體儲存引擎,LDB是使用LSM Tree的持久化磁碟KV儲存引擎,RDB是支援Queue、Set、Maps等資料結構的記憶體及持久化儲存引擎。
Tair的資料分片和路由演算法採用了Amazon於2007年提出的一種改進的一致性雜湊演算法[4]。該演算法將整個雜湊空間分為若干等大小的Q份資料分割槽(也稱為虛擬節點,Q>>N,N為快取節點數),每個快取節點依據其處理能力分配不同數量的資料分割槽。客戶端請求的資料Key值經雜湊函式對映至雜湊環上的位置記為token,token值再次被雜湊對映為某一分割槽標識。得到分割槽標識後,客戶端從分割槽伺服器對映表中查詢存放該資料分割槽的快取節點後進行資料訪問。使用該演算法對相同資料Key進行計算,其必然會被對映到固定的DataServer上,如圖:
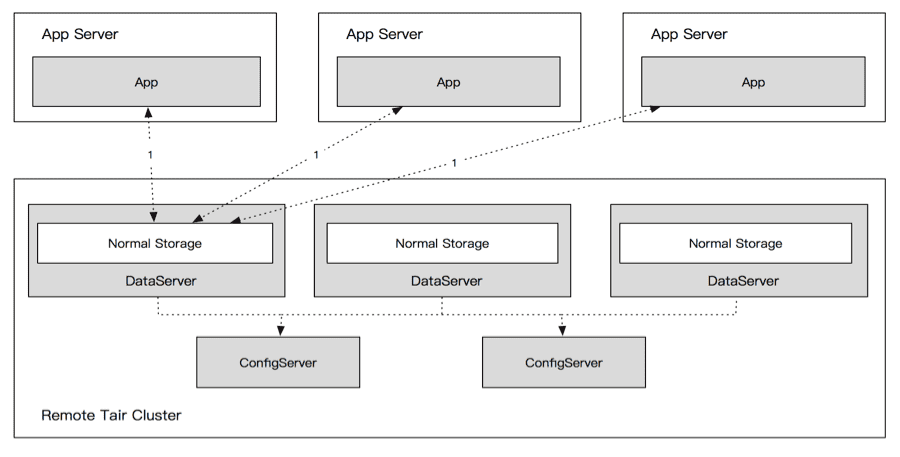
此時DataServer單節點的讀寫效能便成了單資料Key的讀寫效能瓶頸,且無法通過水平擴充套件節點的方式來解決。由於阿里巴巴集團內部電商系的促銷活動天然的存在熱點資料,所以要增強整個彈性快取/儲存平臺的穩定性和服務能力,就必須提升熱點資料的讀寫能力,使其能做到水平擴充套件。
2 解決方案
解決方案分為三部分:熱點識別、讀熱點方案和寫熱點方案。
其中讀寫熱點方案都是以服務端能對熱點訪問進行精準的識別為前提的。另外對於可以提前預知熱點Key的情況,也提供相應的客戶端API以支援特定資料Key或者特定Namespace的所有資料Key預先標記為熱點Key的能力。
2.1 DataServer上的熱點統計過程
DataServer收到客戶端的請求後,由每個具體處理請求的工作執行緒(Worker Thread)進行請求的統計。工作執行緒用來統計熱點的資料結構均為ThreadLocal模式的資料結構,完全無鎖化設計。熱點識別演算法使用精心設計的多級加權LRU鏈和HashMap組合的資料結構,在保證服務端請求處理效率的前提下進行請求的全統計,支援QPS熱點和流量熱點(即請求的QPS不大但是資料本身過大而造成的大流量所形成的熱點)的精準識別。每個取樣週期結束時,工作執行緒會將統計的資料結構轉交到後臺的統計執行緒池進行分析處理。統計工作非同步在後臺進行,不搶佔正常的資料請求的處理資源。
2.2 讀熱點方案
2.2.1 服務端設計
原始Tair的資料訪問方式是先進行Hash(Key)%BucketCount的計算,得出具體的資料儲存Bucket,再檢索資料路由表找到該Bucket所在的DataServer後對其進行讀寫請求的。所以相同Key的讀寫請求必然落在固定的DataServer上,且無法通過水平擴充套件DataServer數量來解決。
本方案通過在DataServer上劃分一塊HotZone儲存區域的方式來解決熱點資料的訪問。該區域儲存當前產生的所有讀熱點的資料,由客戶端配置的快取訪問邏輯來處理各級快取的訪問。多級快取架構如下:
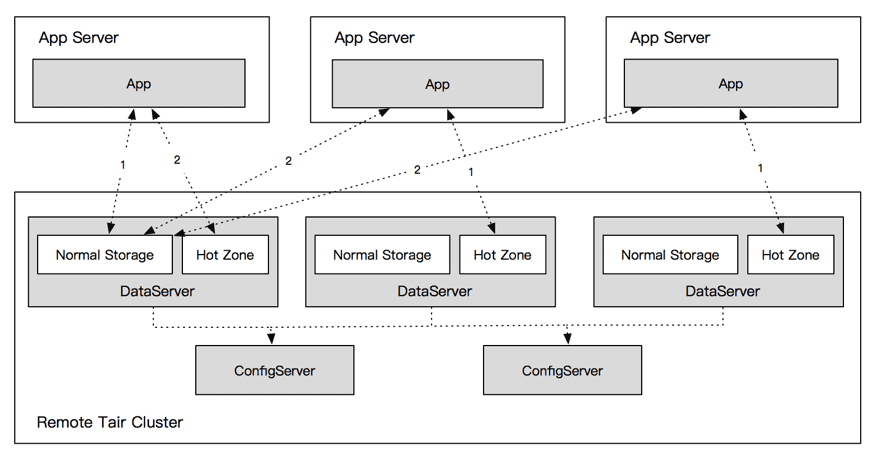
所有DataServer的HotZone儲存區域之間沒有權重關係,每個HotZone都儲存相同的讀熱點資料。客戶端對熱點資料Key的請求會隨機到任意一臺DataServer的HotZone區域,這樣單點的熱點請求就被雜湊到多個節點乃至整個叢集。
2.2.2客戶端設計
2.2.2.1 客戶端邏輯
當客戶端在第一次請求前初始化時,會獲取整個Tair叢集的節點資訊以及完整的資料路由表,同時也會獲取配置的熱點雜湊機器數(即客戶端訪問的HotZone的節點範圍)。隨後客戶端隨機選擇一個HotZone區域作為自身固定的讀寫HotZone區域。在DataServer數量和雜湊機器數配置未發生變化的情況下,不會改變選擇。即每個客戶端只訪問唯一的HotZone區域。
客戶端收到服務端反饋的熱點Key資訊後,至少在客戶端生效N秒。在熱點Key生效期間,當客戶端訪問到該Key時,熱點的資料會首先嚐試從HotZone節點進行訪問,此時HotZone節點和源資料DataServer節點形成一個二級的Cache模型。客戶端內部包含了兩級Cache的處理邏輯,即對於熱點資料,客戶端首先請求HotZone節點,如果資料不存在,則繼續請求源資料節點,獲取資料後非同步將資料儲存到HotZone節點裡。使用Tair客戶端的應用常規呼叫獲取資料的介面即可,整個熱點的反饋、識別以及對多級快取的訪問對外部完全透明。HotZone快取資料的一致性由客戶端初始化時設定的過期時間來保證,具體的時間由具體業務對快取資料不一致的最大容忍時間來決定。
客戶端儲存於本地的熱點反饋過期後,資料Key會到源DataServer節點讀取。如果該Key依舊在服務端處於熱點狀態,客戶端會再次收到熱點反饋包。因為所有客戶端儲存於本地的熱點反饋資訊的失效節奏不同,所以不會出現同一瞬間所有的請求都回源的情況。即使所有請求回源,也僅需要回源讀取一次即可,最大的讀取次數僅為應用機器數。若回源後發現該Key已不是熱點,客戶端便回到常規的訪問模式。
2.2.2.2 雜湊比和QPS偏差的關係
設叢集普通QPS為 C,熱點QPS為 H,機器數為 N,則每臺機器QPS為:
A=(C+H)/N
則普通機器QPS偏差比為:
P_c=(C/N)/A=(C/N)/((C+H)/N)=C/(C+H) ,當 H=0 時,P_c=1
則熱點機器偏差比為:
P_h=(C/N+H)/A=(C/N+H)/((C+H)/N)=(C+HN)/(C+H) ,當 H=0 時,P_h=1
進行雜湊後,設雜湊機器數為 M,則熱點機器偏差比為:
P_(h')=(C/N+H/M)/A=(C/N+H/M)/((C+H)/N)=(CM+HN)/(M(C+H))
設雜湊比為 K,即 M=KN,則有:
P_(h')=(CM+HN)/(M(C+H))=(CKN+HN)/(KN(C+H))=(CK+H)/(K(C+H)),當 K=1 時, P_(h')=1
2.3 寫熱點方案
2.3.1 服務端設計
2.3.1.1 處理方式
對於寫熱點,因為一致性的問題,難以使用多級快取的方式來解決。如果採用寫本地Cache,再非同步更新源DataServer的方案。那麼在Cache寫入但尚未更新的時候,如果業務機器宕機,就會有已寫資料丟失的問題。同時,本地 Cache會導致進行資料更新的某應用機器當前更新週期內的修改對其他應用機器不可見,從而延長資料不一致的時間。故多級Cache的方案無法支援寫熱點。最終寫熱點採用在服務端進行請求合併的方式進行處理。
熱點Key的寫請求在IO執行緒被分發到專門的熱點合併執行緒處理,該執行緒根據Key對寫請求進行一定時間內的合併,隨後由定時執行緒按照預設的合併週期將合併後的請求提交到引擎層。合併過程中請求結果暫時不返回給客戶端,等請求合併寫入引擎成功後統一返回。這樣做不會有一致性的問題,不會出現寫成功後卻讀到舊資料,也避免了LDB叢集返回成功,資料並未落盤的情況(假寫)。具體的合併週期在服務端可配置,並支援動態修改生效。
2.3.2 客戶端設計
寫熱點的方案對客戶端完全透明,不需要客戶端做任何修改。
2.3.3 效能指標
LDB叢集實際壓測效果為單Key合併能做到單Key百萬的QPS(1ms合併,不限制合併次數),線上實際叢集為了儘可能保證實時性,均採用了最大0.1ms以及單次最大合併次數為100次的限制。這樣單Key在引擎層的最大落盤QPS就能控制在10000以下(而合併的QPS則取決於應用的訪問頻率)。Tair服務端的包處理是完全非同步化的,進行熱點請求的合併操作並不阻塞對其他請求的處理。唯一的影響就是增大客戶端對熱點key的寫請求的RT. 按照現在的配置,最壞情況下,客戶端的熱點key的寫操作會增大0.1ms,這個影響是微乎其微的。
【招聘傳送門】歡迎感興趣的同學加入我們,詳情請點選:
參考文獻
[1] Oracle Coherence,http://www.oracle.com/technetwork/cn/middleware/coherence/distributed-caching-089211-zhs.html
[2] Qin XL, Zhang WB, Wei J, Wang W, Zhong H, Huang T. Progress and challenges of distributed caching techniques in cloud computing. Ruanjian Xuebao/Journal of Software, 2013,24(1):50−66 (in Chinese). http://www.jos.org.cn/1000-9825/4276.htm
[3] Gualtieri M, Rymer JR. The forrester wave: Elastic caching platforms.Q2, 2010. ftp://ftp.software.ibm.com/software/solutions/soa/pdfs/wave_elastic_caching_platforms_q2_2010.pdf
[4] Hastorun D, Jampani M, Kakulapati G, Pilchin A, Sivasubramanian S, Vosshall P, Vogels W. Dynamo: Amazon’s highly available key-value store.In: Proc. of the ACM Symp. on Operating Systems Principles (SOSP 2007). 2007. 205−220. [doi: 10.1145/1323293.1294281]
原文:http://click.aliyun.com/m/38414/