
使用Phoenix將SQL程式碼移植至HBase
1.前言
HBase是雲端計算環境下最重要的NOSQL資料庫,提供了基於Hadoop的資料儲存、索引、查詢,其最大的優點就是可以通過硬體的擴充套件從而幾乎無限的擴充套件其儲存和檢索能力。但是HBase與傳統的基於SQL語言的關係資料庫無論從理念還是使用方式上都相去甚遠,以至於要將基於SQL的專案移植到HBase時往往需要重寫整個專案。
為了解決這個問題,很多開源專案提供了HBase的類SQL中介軟體,意即提供一種在HBase上使用的類SQL語言,使得程式設計師能夠像使用關係資料庫一樣使用HBase,Apache Phoenix就是其中的一個優秀專案。
本文介紹瞭如何將基於傳統關係資料庫的程式通過Apache Phoenix移植到基於HBase的雲端計算平臺上的方法,並詳細講述了該過程中碰到的種種困難。主要內容包括:
- HBase及雲端計算環境的安裝配置;
- HBase的Java API程式設計;
- Phoenix的安裝配置與使用;
- Squirrel的安裝配置與使用;
- 使用Phoenix移植SQL程式碼至HBase;
- Phoenix效能調優;
本文的讀者應該是資料庫系統專案的開發人員和維護人員,雲端計算專案開發人員,最好具有以下基本知識:
- linux系統使用常識;
- Hadoop、Hbase、Zookeeper等雲端計算環境使用常識;
- Java程式設計開發基礎;
- SQL語言基礎;
- Oracle、SQLServer或Mysql等關係資料庫使用管理基礎
2. HBase及雲端計算環境的安裝配置
2.1 環境配置
雲端計算環境通常安裝在linux或者CentOS等類UNIX作業系統中,本文涉及的軟體至少需要三個,即Hadoop、Hbase和Zookeeper,其版本號如下:
- hadoop-2.3.0-cdh5.1.0
- zookeeper-3.4.5-cdh5.1.0
- hbase-0.98.1-cdh5.1.0
注意:本文使用了雲時代的版本5.1.0,由於此類軟體版本眾多,互相之間的相容性複雜,因此最好統一採用cdh的版本。系統配置如下圖所示:
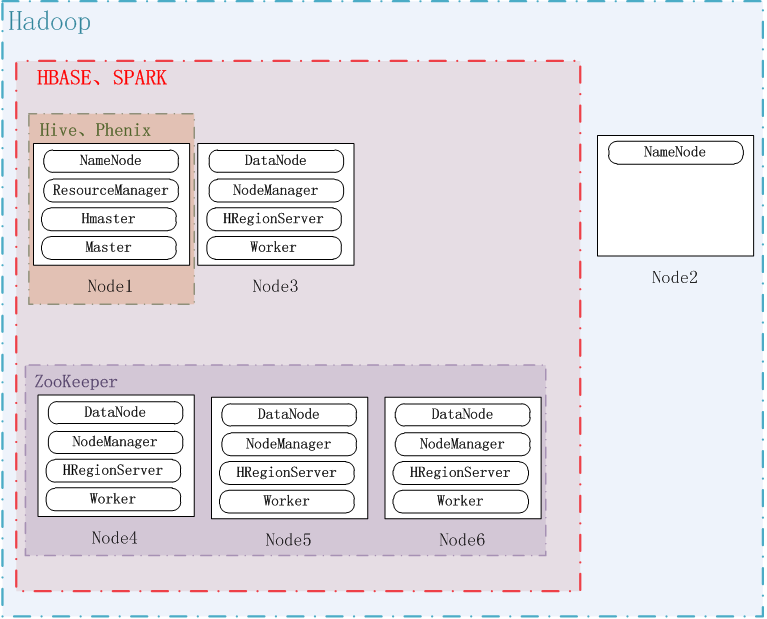
系統一共六個節點,即Node1~Node6,hadoop安裝在全部六個節點上,其中Node1和Node2是NameNode,其他是DataNode;ZooKeeper安裝在Node4、Node5和Node6上,其埠使用預設的2181;Hbase安裝在Node1、Node3~Node6上,其中Node1是HMaster,其他是HRegionServer。
具體引數配置可以參考其他文件,此處不做詳細描述。
注意:客戶端必須通過ZooKeeper找到Hbase的入口。對於客戶來說,只需要知道ZooKeeper在哪兒;需要訪問hbase時,客戶端去找ZooKeeper,ZooKeeper再去查詢HBase的HMaster和HRegionServer等資訊,具體情況見《HBase實戰》63頁。
2.2 HBase Shell使用
環境配置成功後,即可使用HBase Shell對HBase資料庫進行操作,類似於Oracle提供的sqlplus。
登陸任意一個安裝了HBase的伺服器,輸入:
hbase shell
list即可列出該hbase中儲存的所有表格。
建立一個名為test的表格,它帶有一個名為cf的列族,並使用list來查看錶格是否被建立,然後插入一些資料:
hbase(main):003:0> create 'test', 'cf'
0 row(s) in 1.2200 seconds
hbase(main):003:0> list
test
1 row(s) in 0.0550 seconds
hbase(main):004:0> put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.0560 seconds
hbase(main):005:0> put 'test', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0370 seconds
hbase(main):006:0> put 'test', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0450 seconds使用scan來檢視test表格中的內容:
hbase(main):007:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1288380727188, value=value1
row2 column=cf:b, timestamp=1288380738440, value=value2
row3 column=cf:c, timestamp=1288380747365, value=value3
3 row(s) in 0.0590 seconds得到表中的一行資料:
hbase(main):008:0> get 'test', 'row1'
COLUMN CELL
cf:a timestamp=1288380727188, value=value1
1 row(s) in 0.0400 seconds
disable和drop一個表格:
hbase(main):012:0> disable 'test'
0 row(s) in 1.0930 seconds
hbase(main):013:0> drop 'test'
0 row(s) in 0.0770 seconds 退出shell:
hbase(main):014:0> exit其他更多具體的命令請參看HBase的手冊或者線上幫助。
3. HBase Java API 程式設計
使用HBase的Java API進行開發需要掌握HBase的基本理念,推薦閱讀《HBase實戰》一書。
在進行開發的作業系統(例如Windows、Linux或者CentOS)中解壓hbase-0.98.1-cdh5.1.0.tar.gz,得到開發所依賴的所有jar包,位於hbase-0.98.1-cdh5.1.0/lib目錄中。
在開發環境(例如Eclipse、NetBean或者Intellij)中建立工程,匯入hbase-0.98.1-cdh5.1.0\lib中的所有jar包。
3.1 關於遠端連線HBase
在給出原始碼之前,先介紹一下遠端連線HBase的問題。從Oracle時代過來的程式設計師,顯然期望得到資料庫伺服器的ip、port和Service Name之類的資訊。但是在連線HBase時,你需要的卻是一個或多個ZooKeeper伺服器的ip(或者hostname)和port,因為只有它才知曉整個HBase叢集的元資料。
顯然,使用hostname比使用ip要顯得習慣更好,因為它帶來了更大的可移植性,因此費一點筆墨講講linux和windows的hostname設定。
在linux下,hostname通過修改/etc/hosts檔案來完成,在叢集的每臺伺服器上加入如下內容:
192.168.1.101 Node1
192.168.1.102 Node2
192.168.1.103 Node3
192.168.1.104 Node4
192.168.1.105 Node5
192.168.1.106 Node6在各自的/etc/sysconfig/network檔案中,將“HOSTNAME=”修改為“HOSTNAME=Node?”(將Node?替換為本伺服器的hostname)。
在Windows下(僅測試過Win7 64),修改Windows/System32/drivers/etc/hosts檔案,加入:
192.168.1.101 Node1
192.168.1.102 Node2
192.168.1.103 Node3
192.168.1.104 Node4
192.168.1.105 Node5
192.168.1.106 Node6(不同的windows平臺hosts檔案的位置可能不一樣,建議裝一個everything,桌面搜尋速度極快)。
其實多種方法都可以連線到ZooKeeper,例如ip加埠:
public static String hbase_svr_ip = "192.168.1.104, 192.168.1.105, 192.168.1.106";
public static String hbase_svr_port = "2181";或者hostname加埠:
public static String hbase_svr_hostname = "Node4,Node5,Node6";
public static String hbase_svr_port = "2181";或者將埠直接寫在ip後:
public static String hbase_svr_ip = "192.168.1.104:2181, 192.168.1.105:2181, 192.168.1.106:2181";或者將埠直接寫在hostname後:
public static String hbase_svr_hostname = "Node4:2181,Node5:2181,Node6:2181";或者僅使用一個ZooKeeper伺服器:
public static String hbase_svr_hostname = "Node4:2181";具體使用哪種方法就看程式設計師自己的偏好,也存在某種方法在某些版本中可能無法連線的問題,本文中沒有窮盡測試,但個人認為hostname加埠的方法可能比較穩妥。
3.2 原始碼
本篇給出了使用Java API操作HBase的原始碼,注意要將這幾行替換為實際的ZooKeeper伺服器地址、hostname和埠號:
public static String hbase_svr_ip = "192.168.1.104, 192.168.1.105, 192.168.1.106";
public static String hbase_svr_port = "2181";
public static String hbase_svr_hostname = "Node4,Node5,Node6";程式碼功能包括:
- 遠端連線Hbase資料庫;
- 建立表;
- 掃描所有表;
- 插入資料;
- 掃描資料;
- 刪除資料;
- 刪除表。
package com.wxb;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HConnection;
import org.apache.hadoop.hbase.client.HConnectionManager;
import org.apache.hadoop.hbase.client.HTableInterface;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
/**
* @author wxb hbase的基本操作方法
*/
public class HBaseSample {
public static String hbase_svr_ip = "192.168.1.104, 192.168.1.105, 192.168.1.106";
public static String hbase_svr_port = "2181";
public static String hbase_svr_hostname = "Node4,Node5,Node6";
private HConnection connection = null;
Configuration config = null;
/**
* 建構函式,構造一個HBaseSample物件,必須在最後呼叫close方法來關閉所有的連線,釋放所有的資源
*/
public HBaseSample() {
config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", hbase_svr_hostname);
config.set("hbase.zookeeper.property.clientPort", hbase_svr_port);
// System.out.println(config.get("hbase.zookeeper.quorum"));
// System.out.println(config.get("hbase.zookeeper.property.clientPort"));
try {
connection = HConnectionManager.createConnection(config);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 釋放資源
*/
public void close() {
try {
if (null != connection) {
connection.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 建立表格
*
* @param tableName
* @param columnFarily
*/
public void createTable(final String tableName, String columnFarily) {
if (null != config) {
System.out.println("begin create table...");
HBaseAdmin admin = null;
try {
admin = new HBaseAdmin(config);
if (admin.tableExists(tableName)) {
System.out.println(tableName + " is already exist!");
} else {
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
tableDesc.addFamily(new HColumnDescriptor(columnFarily));
admin.createTable(tableDesc);
System.out.println(tableDesc.toString()
+ " has been created.");
}
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
} else {
System.out.println("hbase could not connected!");
}
}
/**
* 向指定表格中新增一行資料
*
* @param table
* @param key
* @param family
* @param col
* @param dataIn
* @return
*/
public boolean addOneRecord(String table, String key, String family,
String col, byte[] dataIn) {
if (null != connection) {
try {
HTableInterface tb = connection.getTable(table);
Put put = new Put(key.getBytes());
put.add(family.getBytes(), col.getBytes(), dataIn);
tb.put(put);
System.out.println("put data key = " + key);
return true;
} catch (IOException e) {
System.out.println("put data failed.");
return false;
}
} else {
System.out.println("hbase could not connected!");
return false;
}
}
/**
* 得到hbase中所有的表
*
* @return
*/
public List<String> getAllTables() {
List<String> tables = null;
if (connection != null) {
try {
HTableDescriptor[] allTable = connection.listTables();
if (allTable.length > 0)
tables = new ArrayList<String>();
for (HTableDescriptor hTableDescriptor : allTable) {
tables.add(hTableDescriptor.getNameAsString());
System.out.println(hTableDescriptor.getNameAsString());
}
} catch (IOException e) {
e.printStackTrace();
}
} else {
System.out.println("hbase could not connected!");
}
return tables;
}
public byte[] getValueWithKey(String tableName, String rowKey,
String family, String qualifier) {
byte[] rel = null;
if (null != connection) {
try {
HTableInterface table = connection.getTable(tableName);
Get get = new Get(rowKey.getBytes());
get.addColumn(Bytes.toBytes(family), Bytes.toBytes(qualifier));
Result result = table.get(get);
if (!result.isEmpty()) {
rel = result.getValue(Bytes.toBytes(family),
Bytes.toBytes(qualifier));
}
} catch (IOException e) {
e.printStackTrace();
}
} else {
System.out.println("hbase could not connected!");
}
return rel;
}
/**
* 從表中刪除一行
*
* @param tableName
* @param rowKey
*/
public void deleteWithKey(String tableName, String rowKey) {
if (null != connection) {
try {
HTableInterface table = connection.getTable(tableName);
Delete delete = new Delete(rowKey.getBytes());
table.delete(delete);
} catch (IOException e) {
e.printStackTrace();
}
} else {
System.out.println("hbase could not connected!");
}
}
/**
* 得到一個表中的所有元素
*
* @param tableName
*/
public void getAllData(String tableName) {
if (null != connection) {
try {
HTableInterface table = connection.getTable(tableName);
Scan scan = new Scan();
ResultScanner rs = table.getScanner(scan);
for (Result r : rs) {
Cell[] cells = r.rawCells();
System.out.println("This row have " + cells.length
+ " cells:");
for (Cell cell : cells) {
String row = Bytes.toString(CellUtil.cloneRow(cell));
String family = Bytes.toString(CellUtil
.cloneFamily(cell));
String qualifier = Bytes.toString(CellUtil
.cloneQualifier(cell));
String value = Bytes
.toString(CellUtil.cloneValue(cell));
System.out.println(String.format("%s:%s:%s:%s", row,
family, qualifier, value));
}
}
} catch (IOException e) {
e.printStackTrace();
}
} else {
System.out.println("hbase could not connected!");
}
}
public void deleteTable(String tableName) {
if (null != config) {
System.out.println("begin delete table...");
HBaseAdmin admin = null;
try {
admin = new HBaseAdmin(config);
if (!admin.tableExists(tableName)) {
System.out.println(tableName + " is not exist!");
} else {
admin.disableTable(tableName);
admin.deleteTable(tableName);
System.out.println(tableName + " has been deleted.");
}
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
} else {
System.out.println("hbase could not connected!");
}
}
/**
* @param args
*/
public static void main(String[] args) {
HBaseSample sample = new HBaseSample();
// 1.create table and insert data
sample.createTable("student", "fam1");
sample.addOneRecord("student", "id1", "fam1", "name", "Jack".getBytes());
sample.addOneRecord("student", "id1", "fam1", "address",
"HZ".getBytes());
// 2.list table
sample.getAllTables();
// 3.getValue
byte[] value = sample.getValueWithKey("student", "id1", "fam1",
"address");
System.out.println("value = " + Bytes.toString(value));
// 4.addOneRecord and delete
// sample.addOneRecord("student", "id2", "fam1", "name", "wxb".getBytes());
// sample.addOneRecord("student", "id2", "fam1", "address",
// "here".getBytes());
// sample.deleteWithKey("student", "id2");
// 5.scan table
sample.getAllData("student");
// 6.delete table
// sample.deleteTable("student");
sample.close();
}
}4. Phoenix的安裝配置與使用
從上一章可以看出,HBase的基本理念和傳統的關係資料庫是截然不同的,為了使得熟悉SQL的程式設計師能夠快速使用HBase,使用Apache Phoenix是比較好的辦法。它提供了一組類似於SQL的語法,以及序列、索引、函式等工具,使得將SQL程式碼移植至HBase成為可能。
4.1 Phoenix安裝
同其他分散式軟體一樣,Phoenix的安裝也是較為複雜的,且要密切關注其版本相容性,否則很可能無法正常執行。例如Phoenix4.x版本都有相容HBase0.98的版本,但是經過兩天的測試才發現不同的Phoenix版本對HBase0.98的小版本號的要求不同。
由於本文使用的是HBase0.98.1,因此只能使用Phoenix4.1.0版本。如果使用的Phoenix版本和HBase版本不相容,會出現第一次能夠連線HBase,但以後都連線失敗的現象。
Phoenix的具體安裝步驟如下:
第一步:將phoenix-4.1.0-bin.tar.gz拷貝到Node1(HBase的HMaster)的某路徑下,解壓縮,拷貝hadoop2/phoenix-4.1.0-server-hadoop2.jar到HBase的lib目錄下。
第二步:然後用scp(關於scp和ssh的設定請參考網上的其他文章,假設使用者名稱為hadoop)拷貝到各個regionserver的HBase的lib目錄下:
scp phoenix-4.1.0-server-hadoop2.jar hadoop@Node3:/home/hadoop/hbase-0.98.1-cdh5.1.0/lib/
phoenix-core-4.6.0-HBase-0.98.jar
scp phoenix-4.1.0-server-hadoop2.jar hadoop@Node4:/home/hadoop/hbase-0.98.1-cdh5.1.0/lib/
phoenix-core-4.6.0-HBase-0.98.jar
scp phoenix-4.1.0-server-hadoop2.jar hadoop@Node5:/home/hadoop/hbase-0.98.1-cdh5.1.0/lib/
phoenix-core-4.6.0-HBase-0.98.jar
scp phoenix-4.1.0-server-hadoop2.jar hadoop@Node6:/home/hadoop/hbase-0.98.1-cdh5.1.0/lib/
phoenix-core-4.6.0-HBase-0.98.jar 第三步:在HMaster上重啟hbase(即Node1);
第四步:將phoenix-4.1.0-client-hadoop2.jar加入客戶端的CLASSPATH變數路徑中,修改使用者的.bash_profile檔案,同時將此檔案拷貝到hbase的lib目錄下。
第五步:測試使用phoenix,輸入命令:
sqlline.py Node4:2181注意:後面的引數是ZooKeeper的伺服器和埠。
出現以下顯示則說明連線成功。
[[email protected] hadoop2]$bin/sqlline.py Node1:2181
Setting property: [isolation, TRANSACTION_READ_COMMITTED]
issuing: !connect jdbc:phoenix:Node4 none none org.apache.phoenix.jdbc.PhoenixDriver
Connecting to jdbc:phoenix:Node4
16/06/21 08:04:24 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-phoenix.properties,hadoop-metrics2.properties
Connected to: Phoenix (version 4.1)
Driver: org.apache.phoenix.jdbc.PhoenixDriver (version 4.1)
Autocommit status: true
Transaction isolation: TRANSACTION_READ_COMMITTED
Building list of tables and columns for tab-completion (set fastconnect to true to skip)...
59/59 (100%) Done
Done
sqlline version 1.1.2
0: jdbc:phoenix:Node4>檢視資料庫表:(注意,phoenix只能看到自己建立的表,不能看到HBase建立的表)
0: jdbc:phoenix:Node4> !tables
+------------+-------------+------------+------------+------------+------------+---------------------------+----------------+-------------+----------------+--------+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_NAME | SELF_REFERENCING_COL_NAME | REF_GENERATION | INDEX_STATE | IMMUTABLE_ROWS | SALT_B |
+------------+-------------+------------+------------+------------+------------+---------------------------+----------------+-------------+----------------+--------+
| null | SYSTEM | CATALOG | SYSTEM TABLE | null | null | null | null | null | false | null |
| null | SYSTEM | SEQUENCE | SYSTEM TABLE | null | null | null | null | null | false | null |
+------------+-------------+------------+------------+------------+------------+---------------------------+----------------+-------------+----------------+--------+
0: jdbc:phoenix:Node4>建立表,並插入資料:
0: jdbc:phoenix:Node4> create table abc(a integer primary key, b integer) ;
No rows affected (1.133 seconds)
0: jdbc:phoenix:Node4> UPSERT INTO abc VALUES (1, 1);
1 row affected (0.064 seconds)
0: jdbc:phoenix:Node4> UPSERT INTO abc VALUES (2, 2);
1 row affected (0.009 seconds)
0: jdbc:phoenix:Node4> UPSERT INTO abc VALUES (3, 12);
1 row affected (0.009 seconds)
0: jdbc:phoenix:Node4> select * from abc;
+------------+------------+
| A | B |
+------------+------------+
| 1 | 1 |
| 2 | 2 |
| 3 | 12 |
+------------+------------+
3 rows selected (0.082 seconds)
0: jdbc:phoenix:Node4>建立包含中文的表(注意中文要使用VARCHAR):
create table user ( id integer primary key, name VARCHAR);
upsert into user values ( 2, '測試員2');
upsert into user values ( 1, '測試員1');
select * from user;
+------------+------------+
| ID | NAME |
+------------+------------+
| 1 | 測試員1 |
| 2 | 測試員2 |4.2 phoenix配置
在hbase叢集每個伺服器的hbase-site.xml配置檔案中,加入:
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>這是在phoenix中建立索引的先決條件。如果不新增此設定,Phoenix依然可以正常使用,但不能建立索引。
4.3 phoenix語法簡介
phoenix的語法可參考其官方網站,也可下載其“Grammar _ Apache Phoenix.html”網頁。
訪問Phoenix時,可以使用其提供的sqlline.py命令,也可以使用下一章介紹的資料庫圖形介面工具Squirrel,當然也可以通過Phoenix提供的Java API。
4.3.1. 建立表
注意:Phoenix中的表必須有主鍵,這一點和許多關係資料庫不同。因為主鍵是後續很多表操作的必備因素。
CREATE TABLE IF NOT EXISTS MYTABLE (ID INTEGER PRIMARY KEY, NAME VARCHAR, SEX VARCHAR, ADDRESS VARCHAR);4.3.2. 刪除表
DROP TABLE IF EXISTS MYTABLE;4.3.3. 插入資料
UPSERT INTO MYTABLE VALUES (1, 'WXB', 'MALE', '010-22222222');注意phoenix使用UPSERT而不是INSERT。
4.3.4. 刪除資料
DELETE FROM MYTABLE WHERE ID = 1;4.3.5. 查詢資料
SELECT * FROM MYTABLE WHERE ID=1;4.3.6. 修改資料
UPSERT INTO MYTABLE VALUES (1, 'WXB', 'MALE', '010-22222222');可以看到,修改資料與插入資料一樣,都是使用UPSERT語句,若此主鍵對應的行不存在,就插入,否則就修改。這也是為什麼Phoenix的表必須有主鍵的原因之一。
4.3.7. 建立序列
Phoenix的序列與Oracle很像,也是先建立,然後呼叫next得到下一個值。也可以繼續呼叫current value得到當前序列值,沒有呼叫next時,不能使用current value。
建立一個序列:
CREATE SEQUENCE IF NOT EXISTS WXB_SEQ START WITH 1000 INCREMENT BY 1 MINVALUE 1000 MAXVALUE 999999999 CYCLE CACHE 30;其含義基本上與Oracle類似。
4.3.8. 使用序列
序列只能在Select或者Upsert語句中使用,例如在Upsert中使用:
UPSERT INTO MYTABLE VALUES (NEXT VALUE FOR WXB_SEQ, 'WXB', 'MALE', '010-22222222');讀取序列的當前值時,採用這個語句:
SELECT CURRENT VALUE FOR WXB_SEQ DUALID FROM WXB_DUAL;然後讀取DUALID就可得到序列的當前值。
這裡的WXB_DUAL是我自己建立的一個特殊表,用來模擬Oracle中的Dual表。
CREATE TABLE IF NOT EXISTS WXB_DUAL (DUALID INTEGER PRIMARY KEY );
UPSERT INTO WXB_DUAL VALUES (1);4.3.9. 刪除序列
DROP SEQUENCE IF EXISTS WXB_SEQ;本章至此為止,詳細的操作留待後續再講。
5. 安裝SQuirrel
Squirrel是一個圖形化的資料庫工具,它可以將Phoenix以圖形化的方式展示出來,它可以安裝在windows或linux系統中。
5.1 安裝步驟
第一步:
設定好JDK,JAVA_HOME,CLASSPATH等一系列的環境變數,注意無論是在windows還是在linux下,都需要上面安裝的hbase和phoenix的存放jar包的目錄,並將其設定到CLASSPATH中。windows下的CLASSPATH如下:
%JAVA_HOME%\lib;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;D:\hbase-0.98.1-cdh5.1.0\lib;D:\phoenix-4.1.0-bin\hadoop2linux的CLASSPATH如下:
export PHOENIX_HOME=/home/hadoop/phoenix-4.1.0-bin
export CLASSPATH=$PHOENIX_HOME/hadoop2/phoenix-4.1.0-client-hadoop2.jar:$HBASE_HOME/lib/:$CLASSPATH
export PATH=$PHOENIX_HOME/bin:$PATH第二步:
下載解壓squirrel-sql-snapshot-20160613_2107-standard.jar(最新版本的squirrel安裝包),在命令列中執行java -jar squirrel-sql-snapshot-20160613_2107-standard.jar開始安裝。
第三步:執行如下安裝
1. Remove prior phoenix-[oldversion]-client.jar from the lib directory of SQuirrel, copy phoenix-[newversion]-client.jar to the lib directory (newversion should be compatible with the version of the phoenix server jar used with your HBase installation)
2. Start SQuirrel and add new driver to SQuirrel (Drivers -> New Driver)
3. In Add Driver dialog box, set Name to Phoenix, and set the Example URL to jdbc:phoenix:localhost.
4. Type “org.apache.phoenix.jdbc.PhoenixDriver” into the Class Name textbox and click OK to close this dialog.
5. Switch to Alias tab and create the new Alias (Aliases -> New Aliases)
6. In the dialog box, Name:Any name, Driver: Phoenix, User Name:Anything, Password:Anything
7. Construct URL as follows: jdbc:phoenix:zookeeper quorum server. For example, to connect to a local HBase use: jdbc:phoenix:localhost
8. Press Test (which should succeed if everything is setup correctly) and press OK to close.
9. Now double click on your newly created Phoenix alias and click Connect. Now you are ready to run SQL queries against Phoenix.
注意,我們連線的URL是jdbc:phoenix:Node4,使用者名稱和密碼隨意即可。連線成功後,如下:
5.2 使用
安裝完畢後,就可以在Squirrel中執行各種phoenix支援的類SQL語句和觀察資料了,例如在SQL欄中輸入如下語句:
CREATE TABLE IF NOT EXISTS MYTABLE (ID INTEGER PRIMARY KEY, NAME VARCHAR, SEX VARCHAR, ADDRESS VARCHAR);
UPSERT INTO MYTABLE VALUES (1, 'WXB', 'MALE', '010-22222222');
UPSERT INTO MYTABLE VALUES (2, ‘LL’, 'MALE', '010-11111111');
SELECT * FROM MYTABLE;結果如下:
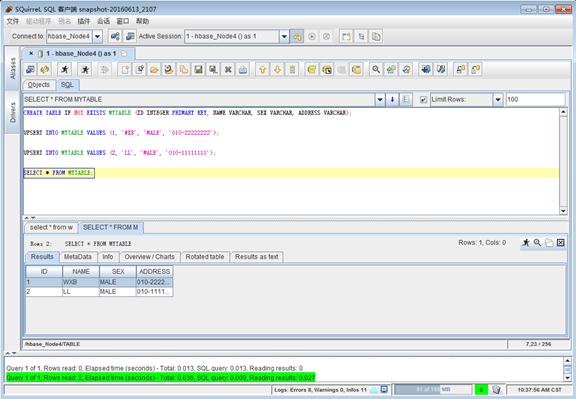
使用Squirrel的好處在於可以方便的檢視資料庫中的各種物件,以及編輯和執行復雜的phoenix類sql指令碼。
6. 使用Phoenix移植SQL程式碼至HBase
Phoenix提供了完全適配JDBC的API,程式設計師可以像操作關係資料庫(例如Oracle)一樣來使用JDBC來操作Phoenix,這也是Phoenix的最大的優勢所在。唯一需要注意的是,提交的SQL語句必須符合Phoenix語法,雖然此語法很類似於SQL,但還是有許多不同之處。
6.1 Phoenix Java Coding
本章給出了一個最基本的Phoenix JDBC原始碼例項,注意其中所引用的所有類幾乎都來自於java.sql.*包,與Oracle唯一的不同是其driver的字串,該字串等於前面連線Squirrel的連線字串,你可以在Squirrel上測試driver字串是否能夠正確連線。driver字串一般為jdbc:phoenix:ZooKeeper_hostname:port,例如jdbc:phoenix:Node4,Node5,Node6:2181。但是在埠為預設2181埠時,也可以省略埠號。
編碼之前將phoenix-4.1.0-client-hadoop2.jar加入java專案的依賴Libraries,例子程式碼如下:
package com.wxb;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
/**
* @author wxb Phoenix的基本操作方法
*
*/
public class PhoenixSample {
public static String hbase_svr_ip = "192.168.1.104, 192.168.1.105, 192.168.1.106";
public static String hbase_svr_port = "2181";
public static String hbase_svr_hostname = "Node4,Node5,Node6";
/*
* 所有幾種方式的driver都能夠通過測試: 1.Node4 2.Node4,Node5,Node6 3.Node4:2181
* 4.Node4,Node5,Node6:2181 5.Node4:2181,Node5:2181,Node6:2181
* 6.101.60.27.114
*/
public static String driver = "jdbc:phoenix:" + hbase_svr_hostname;
public static void createTable(String tableName) {
System.out.println("create table " + tableName);
Statement stmt = null;
try {
Connection con = DriverManager.getConnection(driver);
stmt = con.createStatement();
stmt.executeUpdate("create table if not exists " + tableName
+ " (mykey integer not null primary key, mycolumn varchar)");
con.commit();
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void addRecord(String tableName, String values) {
Statement stmt = null;
try {
Connection con = DriverManager.getConnection(driver);
stmt = con.createStatement();
stmt.executeUpdate("upsert into " + tableName + " values ("
+ values + ")");
con.commit();
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void deleteRecord(String tableName, String whereClause) {
Statement stmt = null;
try {
Connection con = DriverManager.getConnection(driver);
stmt = con.createStatement();
stmt.executeUpdate("delete from " + tableName + " where "
+ whereClause);
con.commit();
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void createSequence(String seqName) {
System.out.println("Create Sequence :" + seqName);
Statement stmt = null;
try {
Connection con = DriverManager.getConnection(driver);
stmt = con.createStatement();
stmt.executeUpdate("CREATE SEQUENCE IF NOT EXISTS "
+ seqName
+ " START WITH 1000 INCREMENT BY 1 MINVALUE 1000 MAXVALUE 999999999 CYCLE CACHE 30");
con.commit();
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void dropSequence(String seqName) {
System.out.println("drop Sequence :" + seqName);
Statement stmt = null;
try {
Connection con = DriverManager.getConnection(driver);
stmt = con.createStatement();
stmt.executeUpdate("DROP SEQUENCE IF EXISTS " + seqName);
con.commit();
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void getAllData(String tableName) {
System.out.println("Get all data from :" + tableName);
ResultSet rset = null;
try {
Connection con = DriverManager.getConnection(driver);
PreparedStatement statement = con.prepareStatement("select * from "
+ tableName);
rset = statement.executeQuery();
while (rset.next()) {
System.out.print(rset.getInt("mykey"));
System.out.println(" " + rset.getString("mycolumn"));
}
statement.close();
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void dropTable(String tableName) {
Statement stmt = null;
try {
Connection con = DriverManager.getConnection(driver);
stmt = con.createStatement();
stmt.executeUpdate("drop table if exists " + tableName);
con.commit();
con.close();
System.out.println("drop table " + tableName);
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
createTable("wxb_test");
createSequence("WXB_SEQ_ID");
// 使用了Sequence
addRecord("wxb_test", "NEXT VALUE FOR WXB_SEQ_ID,'wxb'");
addRecord("wxb_test", "NEXT VALUE FOR WXB_SEQ_ID,'wjw'");
addRecord("wxb_test", "NEXT VALUE FOR WXB_SEQ_ID,'wjl'");
// deleteRecord("wxb_test", " mykey = 1 ");
getAllData("wxb_test");
// dropTable("wxb_test");
// dropSequence("WXB_SEQ_ID");
}
}6.2 每個表必須包含一個主鍵
在使用Phoenix時,建立的每個表都必須包含一個主鍵,這與關係資料庫不同。而且每個表的主鍵會自動被索引,這意味著在select語句的where子句中使用主鍵作為條件,會得到最快的查詢速度。關於索引,在後續章節中再詳細介紹。
我的建議是,為每個表建立一個序列,並在插入資料時以序列的值作為主鍵的值。
6.3 JDBC連線池
Phoenix支援使用者自己建立JDBC連線池,可以將基於JDBC連線池的程式碼複製過來,把Driver部分修改一番即可。
6.4 中文支援
涉及中文的欄位可設定為VARCHAR型別,經測試沒有問題。
6.5 CLOB和BLOB
CLOB和BLOB欄位我都設定為VARCHAR型別,經測試儲存400k位元組的資料沒有問題,更多的沒有測試。
6.6 複雜的SQL語句
因為本文使用的Phoenix版本不是最新版,因此官網上給出的SQL語法不是完全都能夠支援,例如下面的語句就不能支援:
delete from wxb_senword where swid in (select swid from wxb_rela_sw_group where groupid=1)因此對於一些複雜的SQL語句,需要先到官網上查詢語法,然後在phoenix中進行測試,測試通過後才能夠在程式中使用。
兩個表的關聯查詢是可行的,語句如下:
SELECT d.swid,d.swname, d.userid, e.groupid FROM wxb_senword d JOIN wxb_rela_sw_group e ON e.swid = d.swid where e.groupid=1;7. Phoenix效能調優
7.1 程式碼移植流程
將基於SQL的java程式碼移植到Phoenix其實不難,以Oracle為例,基本流程如下:
- 將Oracle中的所有表在Phoenix中重新建立一次,沒有主鍵的自己加一個主鍵(並建立對應的序列);
- 將Oracle中所有的序列、檢視都在Phoenix中重新建立一次;
- 將程式中的每條SQL語句都翻譯為Phoenix的SQL語句,並測試該語句是否能夠正確執行,若不能,總能找到幾條簡單的語句進行替代。
7.2 Oracle和HBase的效能差異
移植完成後,經過一系列debug,程式總算能夠正常運行了。但是效能問題會變得非常嚴重,這是關係資料庫和HBase之間的設計思路和應用問題域之間的差異造成的。
Oracle的設計思路是儘可能的快速對資料進行操作,但是隨著表中記錄數的不斷增加,查詢效能持續下降。要對Oracle進行硬體擴充會比較困難,而且會在單表一億條左右時(沒有經過本人驗證)碰到效能瓶頸。Oracle的優勢是在表中記錄數不多(幾百萬以內,具體看伺服器效能)時擁有極高的查詢速度。
而HBase的優勢是讓單表可以儲存幾乎無限的記錄,並且可以方便的擴充硬體,使得查詢速度可以達到一個穩定的標準。但是其缺點在於表中資料不多時,查詢速度相對較慢。經測試,Phoenix的表在記錄數很少時(數十條),查詢單條資料也需要0.2秒左右(伺服器叢集配置見前面的章節),而同時單伺服器的Oracle查詢這樣的資料僅