
JavaSpark-RDD程式設計-常見操作、持久化、函式傳遞、reduce求平均
RDD是Spark的核心抽象,全稱彈性分散式資料集(就是分散式的元素集合)。Spark中對資料的所有操作無外乎建立RDD、轉化已有RDD和呼叫RDD的操作進行求值。Spark 會自動將
RDD 中的資料分發到叢集上,並將操作並行化執行
RDD在抽象上來說是一種不可變的分散式資料集合(外部文字檔案是在建立RDD時自動被分為多個分割槽)。它是被分為多個分割槽,每個分割槽分佈在叢集的不同節點(自動分發)
RDD通常由檔案(HDFS或Hive表)來建立應用程式中的集合
RDD的資料通常是存放在記憶體中的,記憶體資源不足時,spark會自動將資料寫入磁碟,自動進行記憶體和磁碟之間的權衡和切換機制
RDD的特性提供了容錯性,即可自動從節點失敗中恢復過來。如因節點故障,資料丟失,RDD會自動通過自己的資料來源重新計算該分割槽partition(這是對使用者透明的)
RDD基礎
spark中的RDD是一個不可變的分散式物件集合,可以包含Java、python、scala中的任意型別的物件,甚至可以包含使用者自定義的物件
建立RDD:讀取外部資料,驅動器程式裡分發驅動器程式中的物件集合(list和set)
//建立Spark配置檔案物件
//用配置檔案建立JavasparkContext物件
//外部資料讀取
JavaRDD<String> testFile = js.textFile("G:/sparkRS/readtest.txt" 這些建立的RDD支援兩種操作:轉化操作(由一個RDD生成新的RDD)和行動操作(對一個RDD計算出結果)
它們區別在於spark計算方式不同,轉化是惰性計算,這在大資料領域很有道理(如在建立RDD時就將資料讀取並儲存,但是馬上又進行資料篩選。相反在瞭解整個轉化鏈過後只計算求結果時需要的資料,這會很高效。不需要的資料直接不處理)
如果需要重用一個RDD,可使用RDD.persist方法讓spark把它快取下來(可快取到磁碟而不是記憶體)資料可以持久化到許多地方,在進行一次RDD持久化操作過後,spark把RDD的內容存在記憶體中,之後的行動操作可重用這些RDD。預設不進行持久化(對大資料集很有作用),如果不重用該RDD,就沒有必要浪費空間直接遍歷結果
在任何時候都能進行重算是我們把RDD描述為‘彈性’的原因
節點故障重算出丟掉的分割槽也是利用這個特性。cache與使用persist是一樣的
建立RDD
把程式中一個已有的集合傳給 SparkContext 的 parallelize() 方法(主要用於測試)
JavaRDD<String> lines = sc.parallelize(Arrays.asList("pandas", "i like pandas"));
更常用的方式是從外部讀取資料來建立RDD
JavaRDD<String> testFile = js.textFile("G:/sparkRS/readtest.txt");RDD操作
轉化操作:惰性求值,返回一 個新的 RDD 的操作,比如 map() 和 filter(),
行動操作:向驅動器程式返回結果或把結果寫入外部系統的操作,會觸發實際的計算,比如 count() 和 first()。
轉化操作
只有在行動操作中用到這些 RDD 時才會被計算。許多轉化操作都是針對各個元素的,這些轉化操作每次只會操作 RDD 中的一個元素。不過並不是所有的轉化操作都是這樣的
//filter
SparkConf conf = new SparkConf().setMaster("local").setAppName("My App");
JavaSparkContext js = new JavaSparkContext(conf);
JavaRDD<String> lines = js.parallelize(Arrays.asList("coffe","coffe","panda","monkey","tea"));
long result = lines.filter(x-> x.contains("coffe")).count();
System.out.println(result);
js.close();
//union將兩個RDD合併
SparkConf conf = new SparkConf().setMaster("local").setAppName("My App");
JavaSparkContext js = new JavaSparkContext(conf);
JavaRDD<String> lines = js.parallelize(Arrays.asList("coffe","coffe","panda","monkey","tea"));
JavaRDD<String> lines1 = js.parallelize(Arrays.asList("coffe","coffe","panda","monkey","tea"));
JavaRDD<String> result = lines.filter(x-> x.contains("coffe"));
JavaRDD<String> result1 = lines1.filter(x-> x.contains("tea"));
JavaRDD<String> outcome = result.union(result1);
System.out.println(outcome.collect());
js.close();通過轉化操作,從已有的 RDD 中派生出新的 RDD,Spark 會使用譜系圖(lineage graph)來記錄這些不同 RDD 之間的依賴關係。Spark 需要用這些資訊來按需計算每個 RDD,也可以依靠譜系圖在持久化的 RDD 丟失部分資料時恢復所丟失的資料
行動操作
對資料進行實際的計算,行動操作需要生成實際的輸出,它們會強制執行那些求值必須用到的RDD轉化操作
System.out.println(outcome.collect()); //collect將RDD中的所有資料進行收集,需要大記憶體
System.out.println(outcome.count());
RDD.take(10)使用 take() 獲取了RDD 中的少量元素集。然後在本地遍歷這些元素,並在驅動器端打印出來。RDD還有一個 collect() 函式,可以用來獲取整 個 RDD中的資料。只有當你的整個資料集能在單臺機器的記憶體中放得下時,才能使用collect,因此,collect()不能用在大規模資料集上。在大多數情況下,RDD 不能通過 collect() 收集到驅動器程序中,因為它們一般都很大。每當我們呼叫一個新的行動操作時,整個 RDD 都會從頭開始計算。要避免這種低效的行為,使用者可以將中間結果持久化
惰性操作
惰性求值意味著當我們對 RDD 呼叫轉化操作,操作不會立即執行。 Spark 會在內部記錄下所要求執行的操作的相關資訊。我們不應該把 RDD 看作存放著特定資料的資料集,而最好把每個 RDD 當作我們通過轉化操作構建出來的、記錄如何計算資料的指令列表。把資料讀取到 RDD 的操作也同樣是惰性的。和轉化操作一樣的是, 讀取資料的操作也有可能會多次執行。雖然轉化操作是惰性求值的,但還是可以隨時通過執行一個行動操作來強制 Spark 執行 RDD 的轉化操作,比如使用 count()。
Spark 使用惰性求值,這樣就可以把一些操作合併到一起來減少計算資料的步驟。( Hadoop MapReduce 的系統中,開發者常常花費大量時間考慮如何把操作組合到一起,以減少 MapReduce 的週期數)
傳遞函式
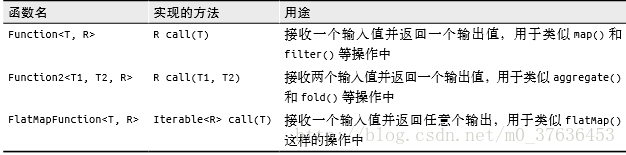
Spark 的大部分轉化操作和一部分行動操作,都需要依賴使用者傳遞的函式來計算。支援的三種主要語言中都略有不同(函式介面)
Java
在 Java 中,函式需要作為實現了 Spark 的 org.apache.spark.api.java.function 包中的任 一函式介面的物件來傳遞,不同返回型別有不同介面
//匿名類進行函式傳遞
RDD<String> errors = lines.filter(new Function<String, Boolean>() {
public Boolean call(String x) {
return x.contains("error");
} });
//使用具名類進行函式傳遞,繼承xx介面,在例項化時就可自動向上轉型當做介面型別
class ContainsError implements Function<String, Boolean> {
public Boolean call(String x) {
return x.contains("error");
} }
RDD<String> errors = lines.filter(new ContainsError());常見的轉化操作和行動操作
包含特定資料型別的 RDD 還支援一些附加操作,例如,數字型別的 RDD 支援統計型函式操作,而鍵值對形式的 RDD 則支援諸如根據鍵聚合資料的鍵值對操作。
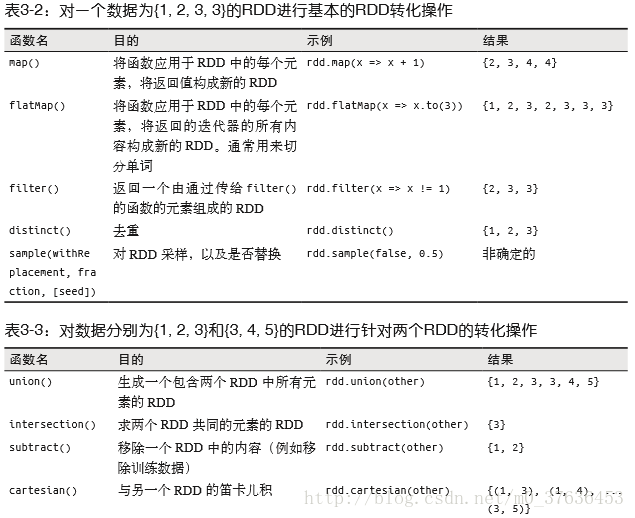
針對各個元素的轉化操作
map() 接收一個函式,把這個函式用於 RDD 中的每個元素,將函式的返回結果作為結果RDD 中對應元素的值
filter() 則接收一個函式,並將 RDD 中滿足該函式的 元素放入新的 RDD 中返回
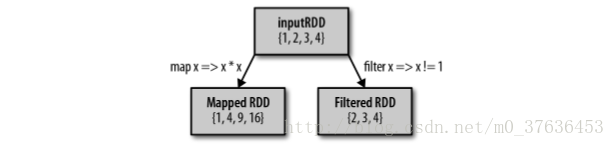
map() 的返回值型別不需要和輸入型別一樣
對每個輸入元素生成多個輸出元素。 flatMap() 返回值序列的迭代器。輸出的 RDD 倒不是由迭代器得到的是一個包含各個迭代器可訪問的所有元素的 RDD。flatMap() 的一個簡 單用途是把輸入的字串切分為單詞
//陣列中的iterator方法可以將陣列轉換為迭代器
JavaRDD<String> words = word.flatMap(x->Arrays.asList(x.split(",")).iterator() );偽集合操作
RDD 本身不是嚴格意義上的集合,但它也支援許多數學上的集合操作
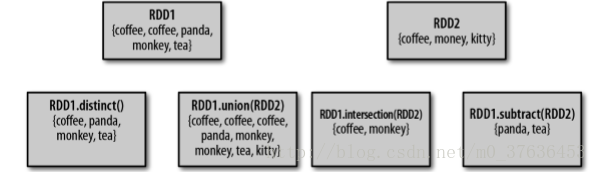
RDD 中最常缺失的集合屬性是元素的唯一性,因為常常有重複的元素。RDD.distinct() 轉化操作來生成一個只包含不同元素的新RDD。distinct() 操作的開銷很大,因為它需要將所有資料通過網路進行混洗(shuffle),以確保每個元素都只有一份
集合操作 union(other),返回一個包含兩個 RDD 中所有元素的 RDD。Spark 的 union() 操作也會包含這些重複資料 (可通過 distinct() 實現相同的效果)。
Spark 還提供了交集 intersection(other) 方法,與union方法相似,只返回兩個 RDD 中都有的元素。但是intersection() 的效能卻要差很多,它需要網路混洗資料發現共有資料
subtract(other) 函式接收另一個 RDD 作為引數,返回 一個由只存在於第一個 RDD 中而不存在於第二個 RDD 中的所有元素組成的 RDD。需要資料混洗。
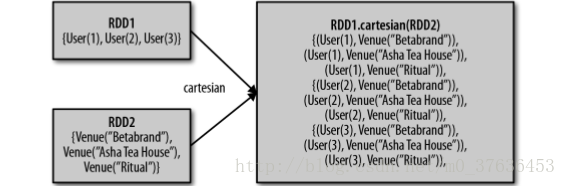
計算兩個 RDD 的笛卡兒積,cartesian(other) 轉化操作會返回所有可能的 (a, b) 對。笛卡兒積在我們希望考慮所有可能的組合的相似度時比較有用(產品的預期興趣程度),開銷巨大。
行動操作
對RDD資料進行實際計算
基本 RDD 上最常見的行動操作 reduce()。接收一個函式作為引數,這個函式要操作兩個 RDD 的元素型別的資料並返回一個同樣型別的新元素
Integer results = counts.reduce((x,y)->{ return x+y; }); 摺疊方法fold() 和 reduce() 類似,接收一個與 reduce() 接收的函式簽名相同的函式,再加上一個 “初始值”來作為每個分割槽第一次呼叫時的結果。使用你的函式對這個初始值進行多次計算不會改變結果,通過原地修改並返回兩個引數中的前一個的值來節約在 fold() 中建立物件的開銷fold() 和 reduce() 都要求函式的返回值型別需要和我們所操作的 RDD 中的元素型別相同。在計算平均值時,需要記錄遍歷過程中的計數以及元素的數量,這就需要我們返回一 個二元組。對資料使用 map() 操作,來把元素轉為該元素和 1 的二元組
//reduce求平均
JavaPairRDD<String,Integer> counts = words.mapToPair(s -> new Tuple2<String, Integer>(s,1));
//reduce求總數和總次數,Tuple2的欄位_1和_2是final型不能
//改變,必須有一個可以操作的變數才能對Tuple2中的數進行計算
//所以,先將第一個RDD的Tuple2賦值給a、b
//然後和y(第二個數)進行計算,返回第一次呼叫的計算結果
//然後第一次的計算結果再和第三個Tuple2進行計算返回第二次的呼叫結果。。。
Tuple2<Integer, Integer> results1 = counts.reduce((x,y)->{
Integer a = x._1();
Integer b = x._2();
a+=y._1();
b+=y._2();
return new Tuple2(a,b);
});
//fold求平均,過程與上大致一樣
Integer reduce = line.fold(0, (x,y) -> x+y);aggregate 函式則把我們從返回值型別必須與所操作的RDD型別相同的限制中解放出來。使用 aggregate() 時,需要提供我們期待返回的型別(自定義)的初始值。然後通過一個函式把 RDD 中的元素合併起來放入累加器。考慮到每個節點是在本地進行累加的,最終,還需要提供第二個函式來將累加器兩兩合併。
//用aggregate()來計算RDD的平均值
public class Operation {
public static void main(String[] args) throws InterruptedException {
// TODO 自動生成的方法存根
SparkConf conf = new SparkConf().setMaster("local").setAppName("My App");
JavaSparkContext jsc = new JavaSparkContext(conf);
JavaRDD<Integer> lines = jsc.parallelize(Arrays.asList(1,2,3,4));
JavaRDD<Integer> line = jsc.parallelize(Arrays.asList(4,5,6));
AvgCount a =new AvgCount(0,0);
Function2<AvgCount,Integer,AvgCount> addAndCount = new Function2<AvgCount,Integer,AvgCount>(){
private static final long serialVersionUID = 1L; @Override
public AvgCount call(AvgCount arg0, Integer arg1) throws Exception {
// TODO 自動生成的方法存根
arg0.total += arg1;
arg0.num += 1;
return arg0;
}
};
Function2<AvgCount,AvgCount,AvgCount> conbine = new Function2<AvgCount,AvgCount,AvgCount>(){
private static final long serialVersionUID = 1L;
@Override
public AvgCount call(AvgCount arg0, AvgCount arg1) throws Exception {
// TODO 自動生成的方法存根
arg0.total += arg1.total;
arg0.num += arg1.num;
return arg0;
}
};
line.aggregate(a,(x,y)->{
x.total += y;
x.num += 1;
return x;
},
(x,y)->{
x.total +=y.total;
x.num +=y.num;
return x;}
);
AvgCount sum = line.aggregate(a, addAndCount, conbine);
System.out.println( sum.total+":"+sum.num+"--------avg:"+(sum.total/sum.num));
jsc.close();
}
}
class AvgCount implements Serializable{
public int total;
public int num;
private static final long serialVersionUID = 3325529460700487293L;
public AvgCount(int total,int num){
this.total = total;
this.num = num;
}
}
RDD 的一些行動操作會以普通集合或者值的形式將 RDD 的部分或全部資料返回驅動器程式中。
collect() 通常在單元測試中使用,因為此時 RDD 的整個內容不會很大,可以放在記憶體中take(n) 返回 RDD 中的 n 個元素集合,並且嘗試只訪問儘量少的分割槽,因此該操作會得到一個不均衡的集合。這些操作返回元素的順序與你預期的可能不一樣。這些操作對於單元測試和快速除錯都很有用,但是在處理大規模資料時會遇到瓶頸。可以用 JSON 格式把資料傳送到一個網路伺服器上,或者把數 據存到資料庫中。都可以使用 foreach() 行動操作來對 RDD 中的每個元 素進行操作,而不需要把 RDD 發回本地。

在不同RDD型別間轉換
有些函式只能用於特定型別的 RDD,比如 mean() 和 variance() 只能用在數值 RDD 上, 而 join() 只能用在鍵值對 RDD 上
Java
要從 T 型別的 RDD 創建出一個 DoubleRDD,我們就應當在對映操作中使用 DoubleFunction<T> 來替代 Function<T, Double>

生成JavaDoubleRDD、計算 RDD 中每個元素的平方值,這樣就可以呼叫 DoubleRDD 獨有的函數了,比如平均是 mean() 和方差 variance()。
JavaDoubleRDD result = rdd.mapToDouble(
new DoubleFunction<Integer>() {
public double call(Integer x) {
return (double) x * x;
} });
System.out.println(result.mean());
持久化(快取)
Spark RDD 是惰性求值的,而有時我們希望能多次使用同一個 RDD。如果簡單地對 RDD 呼叫行動操作,Spark 每次都會重算 RDD 以及它的所有依賴
迭代演算法中消耗格外大,因為迭代演算法常常會多次使用同一組資料
為了避免多次計算同一個 RDD,可以讓 Spark 對資料進行持久化。當我們讓 Spark 持久化 儲存一個 RDD 時,計算出 RDD 的節點會分別儲存它們所求出的分割槽資料。如果一個有持久化資料的節點發生故障,Spark 會在需要用到快取的資料時重算丟失的資料分割槽。如果希望節點故障的情況不會拖累我們的執行速度,也可以把資料備份到多個節點上。
預設情況下persist會把資料以序列化的形式快取在JVM的堆空間中(實際資料區)
Java 中,預設情況下 persist() 會把資料以序列化的形式快取在 JVM 的堆空間中

//對result進行快取
result.persist(StorageLevel.DISK_ONLY)
result.persist(StorageLevel.DISK_ONLY_2)
persist() 呼叫本身不會觸發強制求值
如果要快取的資料太多,記憶體中放不下,Spark 會自動利用最近最少使用(LRU)的快取策略把最老的分割槽從記憶體中移除。對於僅把資料存放在記憶體中的快取級別,下一次要用到已經被移除的分割槽時,這些分割槽就需要重新計算。但是對於使用記憶體與磁碟的快取級別的分割槽來說,被移除的分割槽都會寫入磁碟
RDD 還有一個方法叫作 unpersist(),呼叫該方法可以手動把持久化的 RDD 從緩 存中移除