
C++連結串列學習筆記
如果要儲存一些資料型別相同的變數,比如n個int型別的變數,就可以存放在一個數組中,然後通過下標方便的訪問。可是陣列的缺點也比較多,第一個就是在宣告陣列的時候,陣列的長度必須是明確的,即便是動態宣告一個數組,處理器必須要知道長度才能在記憶體中找出一段連續的記憶體來儲存你的變數。第二個缺點也就是上一句中說到的,陣列在記憶體中的地址必須是連續的,這樣就可以通過陣列首地址再根據下標求出偏移量,快速訪問陣列中的內容。現在計算機記憶體越來越大,這也算不上什麼缺點。第三個缺點,也是非常難以克服的缺點,就是在陣列中插入一個元素是非常費勁的。比如一個長度為n的陣列,你要在陣列下標為0處插入一個元素,在不額外申請記憶體的情況下,就需要把陣列中的元素全部後移一位,還要捨棄末尾元素,這個時間開銷是很大的,時間複雜度為o(n)。
陣列的改良版本就是vector向量,它很好的克服了陣列長度固定的缺點,vector的長度是可以動態增加的。如果明白向量的內部實現原理,那麼我們知道,vector的內部實現還是陣列,只不過在元素數量超過vector長度時,會按乘法或者指數增長的原則,申請一段更大的記憶體,將原先的資料複製過去,然後釋放掉原先的記憶體。
如果你的資料不需要在陣列中進行插入操作,那麼陣列就是個很好的選擇,如果你的元素陣列是動態增長的,那麼vector就可以滿足。
連結串列很好的克服了陣列的缺點,它在記憶體中不需要連續的記憶體,插入或者刪除操作o(1)時間複雜度就能解決,長度也是動態增長。如果你的元素需要頻繁的進行插入、刪除操作,那麼連結串列就是個很好的選擇。下圖是陣列和連結串列在記憶體中的組織形式
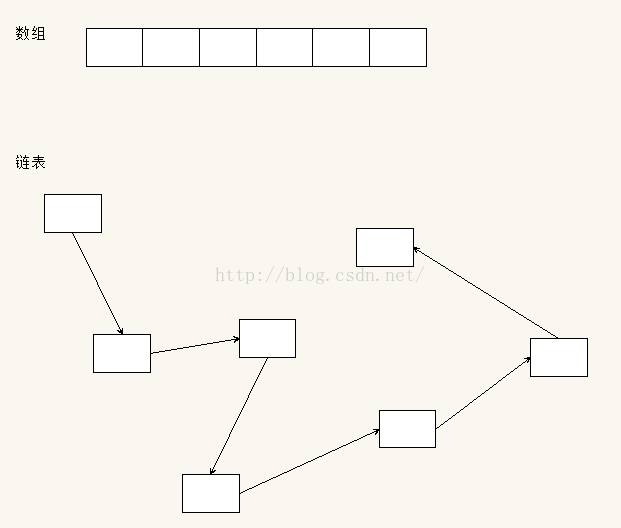
可以看到陣列在記憶體中是連續的,用起始地址加上偏移地址就可以直接取出其中的元素,起始地址就是陣列名,偏移地址就是陣列的下標index*sizeof(t),t就是陣列的型別。
但是連結串列在記憶體中是不連續,為什麼叫連結串列,就是感覺像是用鏈子把一個個節點串起來的。那麼一個個節點是怎麼串接起來的呢,就是指標,每一個節點(末尾節點除外)都包含了指向下一個節點的指標,也就是說指標中儲存著下一個節點的首地址,這樣,1號節點知道2號節點儲存在什麼地址,2號節點知道3號節點儲存在什麼地址...以此類推。就像現實中尋寶一樣,你只知道1號藏寶點,所以你先到達1號藏寶點,1號藏寶點你會得到2號藏寶點的地址,然後你再到達2號藏寶點...直到你找到了你需要的寶藏。連結串列的遍歷就是用這種原理。
連結串列已經超出了基本資料型別的範圍,所以要使用連結串列,要麼使用STL庫,要麼自己用基本資料型別實現一個連結串列。如果是程式設計中正常的使用,當然是推薦前者,如果想真正搞懂連結串列這個資料結構,還是推薦後者。那樣不僅知道標準庫提供的API,也知道這種資料結構內部 的實現原理。這樣的一個好處就是在你程式設計的時候,尤其是對時間空間複雜度比較敏感的程式,你可以根據要求選擇一種最適合的資料結構,提高程式執行的效率。
一個個節點按順序串接起來,就構成了連結串列。顯然這一個個節點是很關鍵的,假設我們要構造一個int型別的連結串列,那麼一個節點中就需要包含兩個元素,一個是當前節點所儲存的值,設為int value。另一個就是指向下一個節點的指標,我們再假設這個節點類是node,那麼這個指標就是 node *next。這裡一定不是int *next。因為這個指標指向的下一個元素是一個類的例項,而不是int型別的資料。那麼node這個類最簡單的實現就如下
class node
{
public:
int value;
node *next;
node()
{
value = 0;
next = NULL;
}
};拿到這個類以後,假設我們生成兩個這個類的例項,node1和node2,再將node1的next指標指向node2,就構成了有兩個元素的連結串列。這樣如果我們拿到node1這個節點,就可以通過next指標訪問node2。比如下面的程式碼
#include <iostream>
using namespace std;
class node
{
public:
int value;
node *next;
node()
{
value = 0;
next = NULL;
}
};
int main()
{
node node1,node2;
node1.value = 1;
node2.value = 2;
node1.next = &node2;
cout << (node1.next)->value << endl;
}將剛剛的程式碼稍作修改
#include <iostream>
using namespace std;
class node
{
public:
int value;
node *next;
node()
{
value = 0;
next = NULL;
}
};
int main()
{
node node1,node2;
node1.value = 1;
node2.value = 2;
node1.next = &node2;
cout << sizeof(node) << endl;
cout << &node1 << endl;
cout << &node2 << endl;
}輸出是這樣的
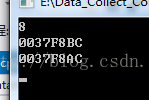
這樣我們就可以根據輸出畫出它們在記憶體中的非常詳細結構圖
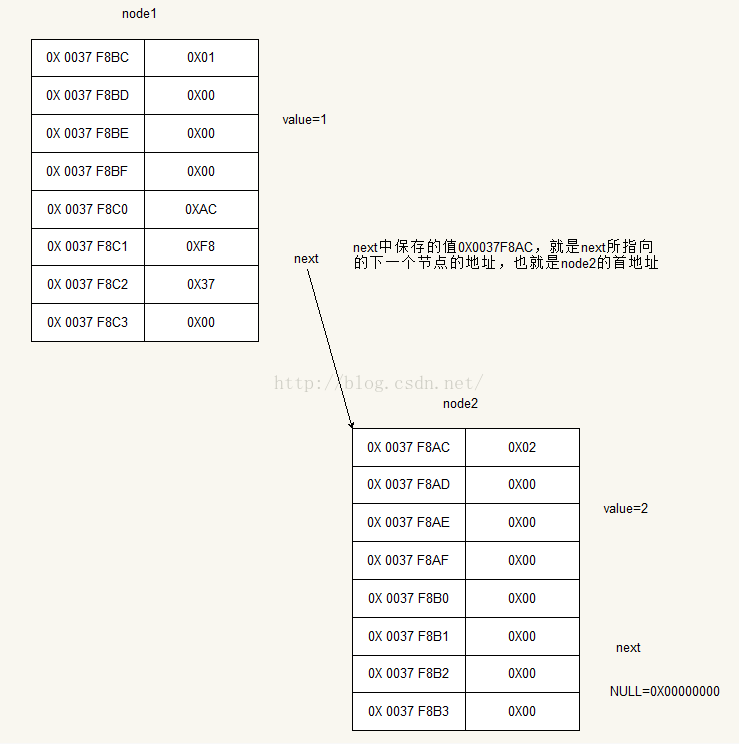
這樣就構成了一個最簡單的連結串列,如果還有新的節點出現,那麼就如法炮製,鏈在表尾或者表頭,當然插在中間也是沒問題的。
但是這樣還有個問題就是node1和node2是我們提前宣告好的,而且知道這兩個例項的名稱,如果我們需要1000甚至跟多節點,這種方式顯然是不科學的,而且在很多時候,我們都是動態生成一個類的例項,返回的是這個例項的首地址。下面的程式碼我們用一個for迴圈,生成11個節點,串起來形成一個連結串列
#include <iostream>
using namespace std;
class node
{
public:
int value;
node *next;
node()
{
value = 0;
next = NULL;
}
};
int main()
{
node *head,*curr;
head = new node();
head->next = NULL;
head->value = 15;
for (size_t i = 0; i < 10; i++)
{
curr = new node();
curr->value = i;
curr->next = head;
head = curr;
}
cout << head->value << endl;
}那麼連結串列該如何遍歷呢,剛開頭的時候就說,遍歷連結串列需要從頭到尾,訪問每一個元素,直到連結串列尾。也就是說不斷地訪問當前節點的next,直到NULL。下面是連結串列的遍歷輸出
#include <iostream>
using namespace std;
class node
{
public:
int value;
node *next;
node()
{
value = 0;
next = NULL;
}
};
int main()
{
node *head,*curr;
head = new node();
head->next = NULL;
head->value = 15;
for (size_t i = 0; i < 10; i++)
{
curr = new node();
curr->value = i;
curr->next = head;
head = curr;
}
while (head!=NULL)
{
cout << head->value << endl;
head = head->next;
}
}
連結串列相對於陣列有個非常明顯的優點就是能以時間複雜度o(1)完成一個節點的插入或者刪除操作。
插入操作的原理很簡單,假設現在有三個節點,一個是當前節點curr,一個是當前節點的下一個節點,也就是後繼節點,假設為next,還有一個待插入的節點,假設為insert。插入操作就是讓當前節點的後繼節點指向insert節點,insert節點的後繼節點指向next節點。以下是示意圖
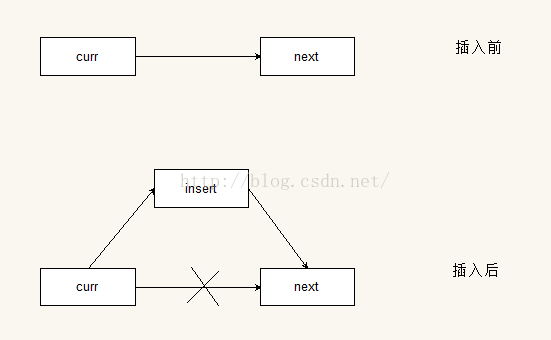
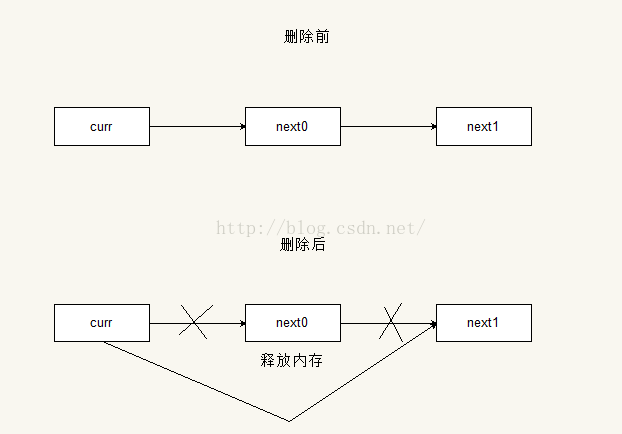
刪除操作的原理也是類似的,就是讓當前節點的後繼節點指向它後繼節點的後繼節點。示意圖如下
那麼插入和刪除操作用程式碼如何實現呢,我們還有原先的連結串列,先插入一個值為20的節點,輸出連結串列的全部元素。然後再刪除連結串列中這個值為20的元素,輸出元素的全部內容。程式碼如下
#include <iostream>
using namespace std;
class node
{
public:
int value;
node *next;
node()
{
value = 0;
next = NULL;
}
};
int main()
{
node *head=NULL,
*curr=NULL, //當前節點
*insert=NULL, //插入節點
*next=NULL, //後繼節點
*pre=NULL; //前驅節點
head = new node();
head->next = NULL;
head->value = 15;
for (size_t i = 0; i < 10; i++)
{
curr = new node();
curr->value = i;
curr->next = head;
head = curr;
}
curr = head; //取出頭結點
while (curr->value != 5)
{
curr = curr->next;
}
//找到值為5的節點
next = curr->next; //找到值為5的節點的後繼節點
insert = new node(); //生成一個新的節點,值為20
insert->value = 20;
curr->next = insert; //當前節點的後繼節點為插入節點
insert->next = next; //插入節點的後繼節點為值為5的節點的後繼節點
curr = head; //遍歷連結串列,輸出每一個元素
while (curr!=NULL)
{
cout << curr->value<<endl;
curr = curr->next;
}
curr = head; //找到頭結點
while (curr->value!=20)
{
pre = curr;
curr = curr->next;
}
//找到值為20的節點,注意現在是單向連結串列,每個節點中不儲存它的前驅節點,所以在遍歷的過程中要人為儲存一下前驅節點
next = curr->next; //找到當前節點的後繼節點(當前節點就是值為20的節點)
pre->next = next; //當前節點的前驅節點的後繼節點為當前節點的後繼節點
delete curr; //刪除當前節點
curr = head; //遍歷這個連結串列輸出每個元素
while (curr != NULL)
{
cout << curr->value << endl;
curr = curr->next;
}
while (true)
{
}
}輸出如下:
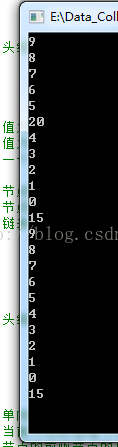
至於完整的連結串列,STL中有標準的庫,也有功能非常全面的API,只要我們知道內部的實現原理,呼叫這些API是非常簡單的事,用起來也會得心應手。