
神經網路學習筆記(五) 徑向基函式神經網路
阿新 • • 發佈:2019-02-07
徑向基函式神經網路
首先介紹一下網路結構:
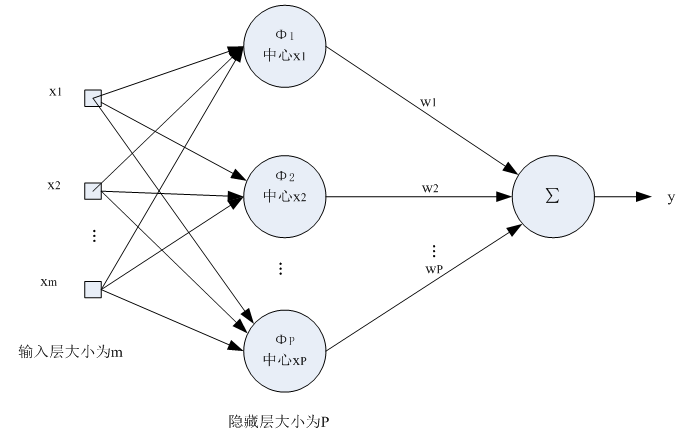
1.輸入層為向量,維度為m,樣本個數為n,線性函式為傳輸函式。
2.隱藏層與輸入層全連線,層內無連線,隱藏層神經元個數與樣本個數相等,也就是n,傳輸函式為徑向基函式。
3.輸出層為線性輸出。
理論基礎
徑向基函式神經網路只要隱含層有足夠多的隱含層節點,可以逼近任何非線性函式。
在擬合函式的時候,我們要儘量的經過每一個點,但是當一大堆散亂資料的時候我們如果經過每一個點就造成過擬合,也就是根本無法尋找裡面的隱含規律,我們需要一個權值均衡的擬合方式,這時候就要用到最小二乘法。
那麼我們對樣本點附近的點用什麼方法插值呢?
這就是基函式的作用了。通常我們將基函式設為高斯函式,那麼高斯函式裡面就涉及到兩個引數了:sigma和距離d
高斯函式: exp(-d^2/(2*sigma^2));
sigam就是平滑因子,他可以控制高斯函式的平滑度。
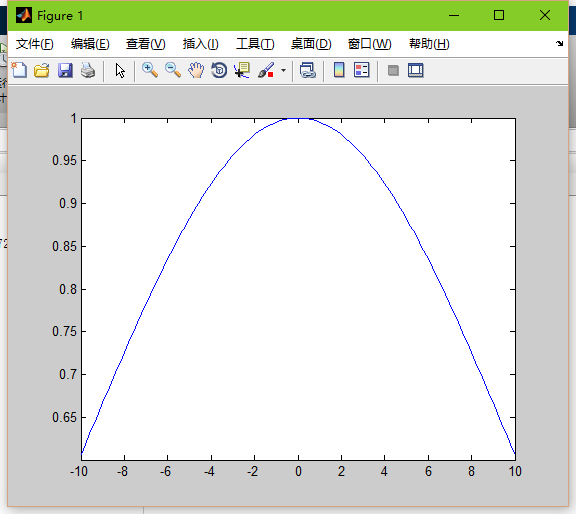
sigma=10
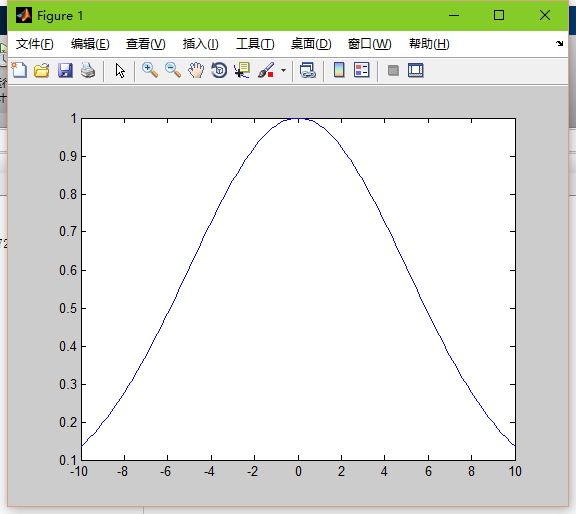
sigma=5
sigma=1
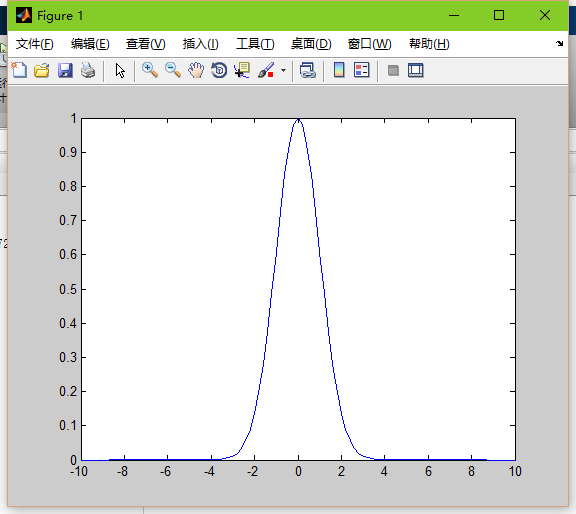
sigma=0.1
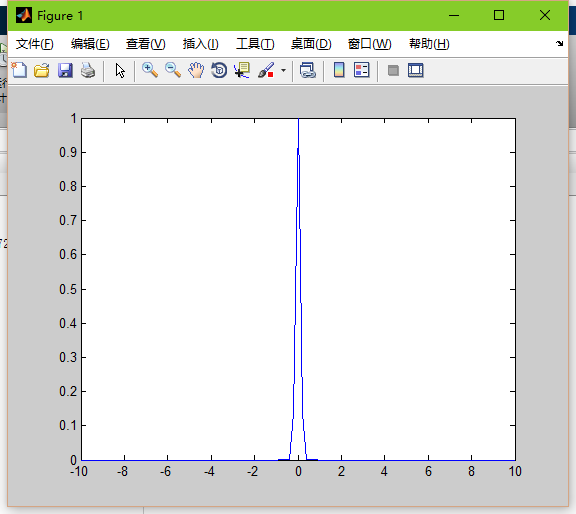
當平滑因子較低時,高斯函式就會尖銳,也就是邊緣點的權值會很小,導致過擬合。
那麼距離d是什麼呢?
距離d就是向量離每一個隱含層中心的距離,通常隱含層的中心對應每個節點,所以每個距離就是節點矩陣自身相對自身每個點的距離。
距離表示著離節點越近,所受該節點的輸出影響就越大。
下面就來實現一下這個神經網路
matlab(非API實現)
1.定義一些變數:
data=-9 spread就是sigma值 也稱平滑度。
data為實際資料。
x為測試資料。
label表示目標輸出。
2.看一下輸出點
plot(data,label,'o');
hold on;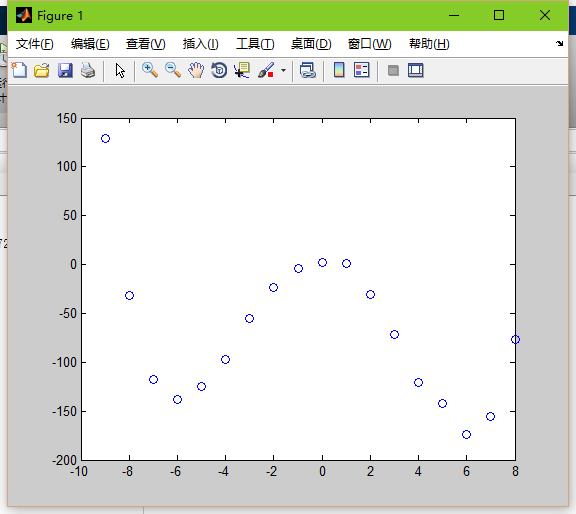
3.擬合這條曲線的權值
dis=dist(data',data); %求距離
gdis=exp(-dis.^2/spread);%gauss
G=[gdis,ones(length(data 4.測試所擬合的權值
chdis=dist(x',data);
chgdis=exp(-chdis.^2/spread);
chG=[chgdis,ones(length(x(1,:)),1)];
chy=chG*w;
plot(x,chy);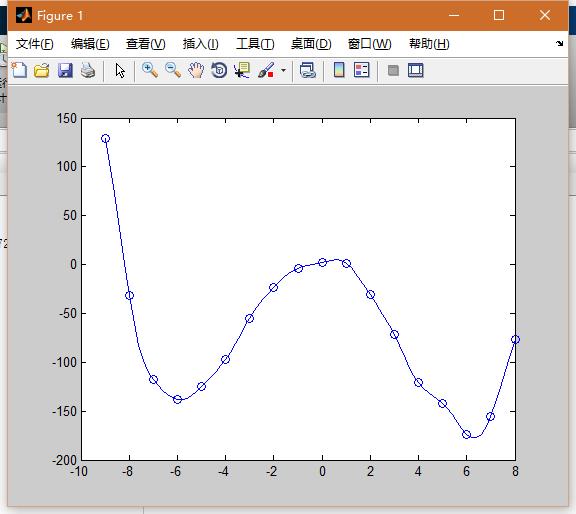
如果將spread取0.1
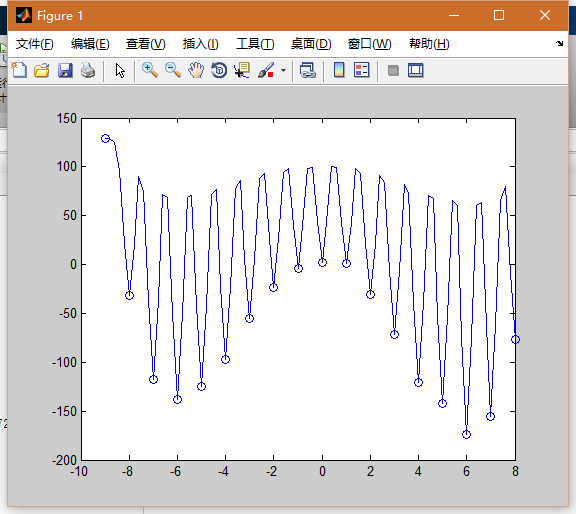
節點附近的插值點的全脂會非常小導致曲線過擬合。
如果將spread取50000
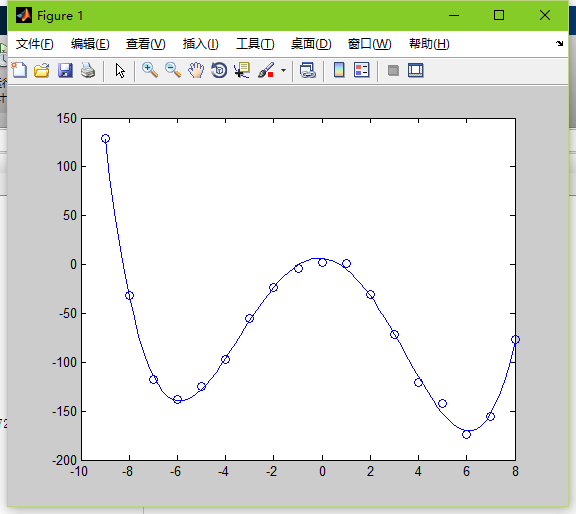
很多點都已經偏離,曲線過於平滑。導致欠擬合。
如果再加2個0,取5000000
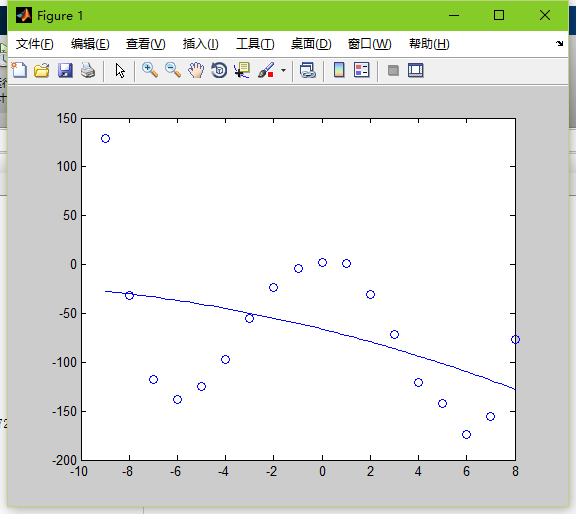
這個sigma太大了,直接會導致函式不擬合。
結束語
徑向基函式有著bp演算法不能達到的擬合效果,在擬合曲線上,徑向基函式更快,更準確。
下一節我們會討論優化的變種徑向基函式神經網路—-廣義迴歸神經網路(GRNN)。