
推薦系統(Recommender System)的技術基礎
推薦系統是通過分析使用者屬性、訪問日誌、反饋資訊等對使用者可能感興趣的項進行預測。推薦系統在web2.0時代將有非常廣泛的應用。
推薦系統應用了多個領域的方法和技術,如人機對話(Human Computer Interaction)、資訊檢索(Information Retrieval)等。不過說到底,這些都是以資料探勘(Data Mining)為基礎的。
資料探勘的過程由下圖中所示的三個步驟組成:

1.資料預處理(preprocessing)
資料探勘的物件是資料,在對資料進行分析之前,要對資料進行清洗,轉換、轉載(ETL)使其完整、一致,在推薦系統中,資料的預處理主要包括距離計算,取樣和降維。
(1)距離計算(Distance Measures)
推薦目前主要採用兩種方法:基於內容的推薦和協同推薦。協同推薦的原理是尋找使用者的鄰居,為其推薦鄰居感興趣的東西。發現鄰居的方法就是通過計算使用者間的相似度對使用者進行分類,相似度的基礎就是距離計算。
常見的兩個物件間距離的計算有如下幾種方法:
1)歐幾里得距離
定義如下:

其中,n為物件的屬性的個數,xk、yk為第k個屬性,x、y為物件。
2)閔可夫斯基距離是歐幾里得距離的推廣
定義如下:

其中,r是距離的度,有時被稱為Lr範數。另外,我們可以發現,當r=1時,它表示為曼哈頓距離,r=2時,表示為歐幾里得距離,當r→∞時,表示為supremum距離,它對應於計算兩個物件間任意維度的最大區別。
3)馬氏距離
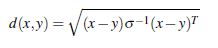
其中,σ是x、y的協方差矩陣。
此外,還有一種常見的計算物件間相似度的方法。將項看成n維的文件矩陣,通過計算兩個物件間的cos值來表示相似度。公式如下:
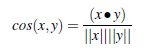
其中•表示向量的點乘,||x||表示x的範數。
當物件的屬性為二元變數時,即只有0,1兩種狀態。此時,就需要特定的方法來計算相似度。例如用M00、M01、M10、M11來表示具有兩個二元變數的物件的四種狀態,如果二元屬性是對稱的,也就是說兩個狀態具有相同的價值和相同的價值,那麼物件間的相似度計算公式為:
簡單匹配係數=(number of matched/number of attributes)=(M00+M11)/(M01+M01+M10+M11)
如果二元屬性不是對稱的,則計算公式為:
Jaccard係數=M11/(M01+M10+M11)
(2)取樣(Sampling)
資料探勘過程中,不可能對所有的資料進行處理,往往是選擇一個子集作為資料來源,從所有資料中選擇資料子集的過程就是取樣。選擇出的子集還分為訓練集(training dataset)和測試集( testing dataset),訓練集主要用來學習演算法,測試集用來測試演算法質量。
取樣要求選擇出的資料具有代表性,目前主要取樣以下兩種方法:
1)隨機取樣 即等概率的從資料整體中抽取資料。
2)分層取樣 基於資料的特徵將資料分成幾部分,在每一部分再進行隨機取樣。
在取樣過程中,一種是不重複取樣,另一種是重複取樣。最常用的一種方法是80/20原則的不重複隨機取樣。80/20是指從取樣結果中取80%作為訓練集,另外20%作為測試集,這種方法在超過2/3情況下是適合的。
另外,為了防止取樣結果不具有代表性,一般會重複取樣,對資料經過多次測試來保證準確性。
(3)降維(Dimensionality Reduction)
取樣得到的資料可能會有冗餘、維難等問題,為了解決這些問題,就需要對資料進行降維。常用的降維方法有以下兩種:
1)主成分分量分析法(Principal Compenent Analysis,PCA)
2)奇異值分解法(Singular Value Decomposit,SVD)
(未完,待續)