
[JVM]Java工程師要懂的硬體知識-前言
Mechanical Sympathy這個短語描述了一種車手對汽車天生的感覺,也是Martin Thompson大牛的部落格標題。從併發程式設計網Disruptor的介紹中注意到這個短語,再去品位Martin對它的簡短闡述’Hardware and software working together in harmony’的確很有道理。在對任何語言的深入學習研究中,總逃不過對底層硬體的瞭解與學習,很多語言的特性、行為在硬體的角度去觀察就很容易解釋了;同時在追求語言的更高效能的過程中,也要更多去了解硬體的知識,讓軟體更加匹配硬體的特性、更好利用硬體的優化才能獲得更高的優化效果。
概述硬體工程師的傑作
今天網際網路的繁榮是站在硬體工程師的偉大傑作之上的,使硬體更加高效的一個途徑是提高硬體的執行速度,另外一個途徑就是讓可以任務並行起來,隨之而來的就是快取、併發、同步等一些列設計和優化。現代計算機的異步特性加之這些優化使得軟體系統在多執行緒的情況下常常出現背離程式直覺的情況。作為一個高階語言開發者瞭解硬體就是為去感受Mechanical Sympathy,去了解硬體工程師的用心良苦從而讓軟體與硬體更加匹配。
講故事要從開頭說,在很早很早以前有一位叫圖靈的先生畫了一個盒子,這個盒子就一直把人們圈到了現在,這就是圖靈機模型。
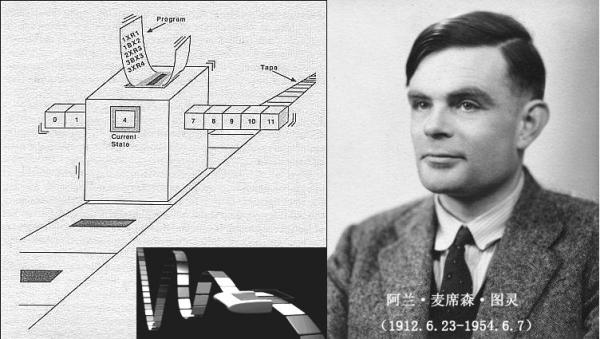
這個盒子有一條紙帶和一個規則表格還有一個內部狀態儲存,當然還有一個用來讀、寫紙帶的讀寫頭。整個過程模擬了人類在算草紙進行運算的過程
言歸正傳雖然現代計算器體系還在這個圈圈之中,但是整體的結構已經變得極度複雜了。
下圖是一個CPU的邏輯組成(物理上並不是都在CPU裡),它作為整個計算機系統的大腦,負責著處理所有型別資料的運算工作(其實還有各式各樣的協處理器幫忙),這也是軟體工程師關注的計算機系統核心模型。它主要有CU,MU,ALU,IO四個子系統組成,看似簡單的四個框框其實每個都涵蓋了N個複雜的結構。
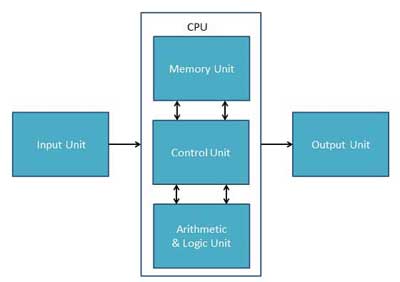
Memory Unit
簡單說記憶體和儲存單元(MU)就是負責儲存各種資料的部分,它也稱為內部儲存/主儲存/RAM。RAM的名稱來自其硬體特性隨機訪問,內部儲存/主儲存的名稱來自相對於硬碟等通過IO系統訪問的儲存而言的。注意這裡說的是CPU的邏輯組成
MU指的並不僅僅是CPU內部的儲存部件還應該涵蓋了記憶體。
MU負責儲存的有以下資料:
- 處理過程中,所需的所有資料和指令
- 處理過程中,產生的中間結果
- 已處理完成,但尚未通過輸出裝置釋出的資料
- 經輸入/輸出裝置,要進入/輸出的所有主記憶體資料
MU功能看似簡單但這一塊卻是Java工程師最需要關注的部分。眾所周知各種儲存部件的速度有很大差別,為了匹配高速執行的運算核心並很好的平衡成本,硬體工程師在這裡設計了多層的快取系統。也因為儲存系統及IO系統的延遲,為了更好的發揮硬體能力,硬體工程師在這裡設計了指令亂序、回寫緩衝等等。
先給出一張Intel的Sandy Bridge微架構處理器的MU示意圖,讓大家對MU的快取系統組成和各個部分的訪問速度有一個直觀的印象。
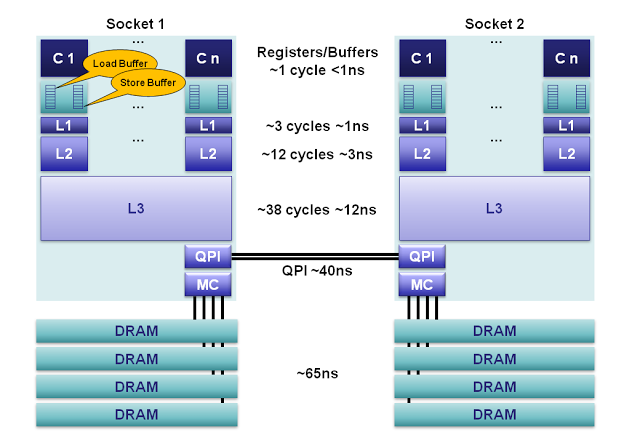
從圖中看到整個MU由每個核心獨享的暫存器,讀取緩衝,儲存緩衝,L1 Cache,L2 Cache;同插槽核心共享的L3 Cache以及一個跨插槽的NUMA結構組成。
NUMA是每個插槽獨享的記憶體控制器(MC)和MC分配到的記憶體組成以及連線插槽通訊的QPI匯流排的。
在這些不同核心的快取之間存在著硬體連線,通過MESI/MESIF/MOESI協議,QPI匯流排或HT匯流排保證快取的一致性。現在網上經常出現對這一塊誤解的文章,從快取不一致角度去解釋多執行緒的某些一致性問題;新手要認識到MU的這些快取在硬體上都已經保證了一致性不要被誤導。
圖中標註了每種儲存訪問的延遲,從最小的1個CPU節拍到跨插槽記憶體訪問時QPI延遲+DRAM訪問延遲大致100ns左右的延遲,各級訪問速度的差異顯而易見。這裡的優化一般考慮儘可能命中快取、降低快取間一致性協議通訊流量的方案。
直觀的看對於一顆頻率為3G的CPU核心,因為流水線(Pipeline)技術每CPU節拍可以[並行執行]1[4條指令]2;1ns就有3個節拍也就是每顆核心能並行執行12條指令,可以想象跑一趟主存就可能要耽誤1200條指令,而且這個延遲還從10-100納秒不一定。在等待這個延遲的時候CPU就什麼都不做嗎?硬體工程師在這裡設計了亂序執行,這樣就可以很大限度的隱藏這個延遲了。
由此可見這裡對於軟體工程師提升效能有多大的發揮空間,軟體工程師的Mechanical Sympathy就是在這些細節中展現出的力量。相反這裡提到的亂序能很大隱藏延遲,但它也是無數程式設計師都踩過的深坑,在多執行緒程式設計中迷糊了無數人。天下沒有免費的午餐!作為一個Java工程師去學習硬體知識可以更好的理解多執行緒程式設計、可能大大提升程式的響應速度,但如果平時工作中太糾結於這些硬體細節又會迷失忘卻作為一名高階語言開發者最重要的開發效率。
ALU(Arithmetic Logic Unit)
算數邏輯運算單元(ALU)由算數運算單元(AU)和邏輯運算單元(LU)組成。
算數運算單元主要完成各種數學運算,也就是加、減、乘、除等運算。在這一塊的優化一般就是推薦儘量使用AU擅長的加法、移位運算,比如使用移位運算代替乘法運算、在二維座標系求兩點距離儘量直接使用未開方運算的數值等。
上述內容在組原教材中有明確的記載大家也很理解和認同。的確在早期的CPU中乘法運算相對加法運算非常耗時,但是隨著技術的發展越來越多的CPU整合了數學協處理器,現在差距可能不是那麼懸殊了。協處理器就好比CPU的一個小弟,因為其電路是專為某種行為設計的所以在特定操作上比通用處理器速度更快。當CPU遇到某個複雜的運算時會將這個運算交給協處理器完成從而提升整體的速度。這裡提到協處理並不是說我們沒有必要進行優化了,而是提醒剛剛畢業的小鮮肉們技術日新月異,有的時候我們的教材不一定適用了不要墨守成規,像這樣的例子更極端的還有Java(32位JVM測試)裡面short運算比int運算更慢。
邏輯運算單元(LU)就是完成邏輯運算的元件,例如比較、判斷、匹配及歸併資料(comparing, selecting, matching and merging of data)。
Control Unit
控制單元(CU)負責操作計算機的所有部件協調的工作,它並不直接參與到資料處理、讀寫過程而是指揮、協調元件完成資料處理。
CU主要完成以下功能:
- 控制資料流和指令流在其它系統中的流轉
- 從
MU中獲取指令、翻譯指令並根據指令操作計算機的完成指令 - 控制和協調其它單元的工作
- 控制
IO單元進行資料的輸入輸出
作為一個Java工程師本人對這一塊的瞭解也不是很深入,寫在這裡也是希望拋磚引玉盼望有朋友能給出一兩個這一塊優化的例項。
IO系統
IO系統負責著與外部裝置通訊,對於Java工程師最常見的就是檔案系統訪問、資料庫訪問、網路服務等。這一塊延遲相對MU延遲可能是非常大數字,所以作為一個Java工程師這也許是我們使用多執行緒程式設計最重要的原因,讓程式在IO等待期間並行起來充分利用系統的計算能力。配合多執行緒還有批量處理、NIO等技術,總之一個應用響應時間出現問題最常見的就是IO佔用的時間比非常高而且還是阻塞等待。
小節
本節非常概括的介紹了CPU基本邏輯組成和一些技術名詞;一方面是希望使大家在後續討論中對這些名詞不是很陌生,另外主要的目的還是為新手提供一個參考的概覽圖,希望在後續討論過各種區域性技術後能為其形成自己的知識體系有一點幫助。