
構建於HDFS之上的Greenplum: HAWQ
1. HAWQ 是什麼
如果你知道Greenplum是什麼,那麼你就能很簡單的明白HAWQ是什麼。Greenplum是一個關係型的分散式MPP資料庫,同樣運行於X86架構的基礎之上,具有查詢、載入效率高,支援TB/PB級大資料量的OLAP應用, Greenplum的所有資料都儲存於系統本地檔案系統中。而HAWQ的最大改變就是將本地檔案系統儲存更換為了HDFS,成功的搭上了大資料庫的班車。不過HAWQ相較於其它的SQL on Hadoop元件來說,也是具有很多優勢的,比如:
- 對SQL的完善支援,以及語法上的OLAP擴充套件支援
- 具有比較成熟的SQL並行優化器,而這正是其它SQL on Hadoop元件比較欠缺的。
- 支援ACID事務特性,這個在其它SQL on Hadoop元件也是比較欠缺的。
- 支援多語言的UDF支援:Python, Perl, Java, C/C++, R
- 等等,反正比較牛B,原Greenplum上支援的功能在HAWQ基本都能找到。
2. HAWQ 結構
HAWQ在結構仍然是Master-Slave的主從模式,典型的部署方式仍然是在Master伺服器上部署:HAWQ Master, HDFS Master, YARN ResouceManager, 在每一個SLAVE機器上部署: HAWQ segment, DataNode, NodeManager。具體結構看圖:
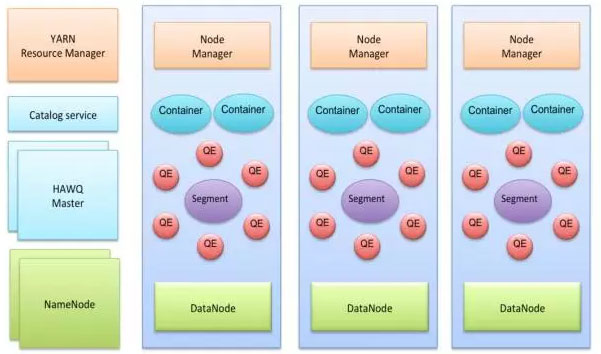
下面是一張HAWQ的軟體元件圖:
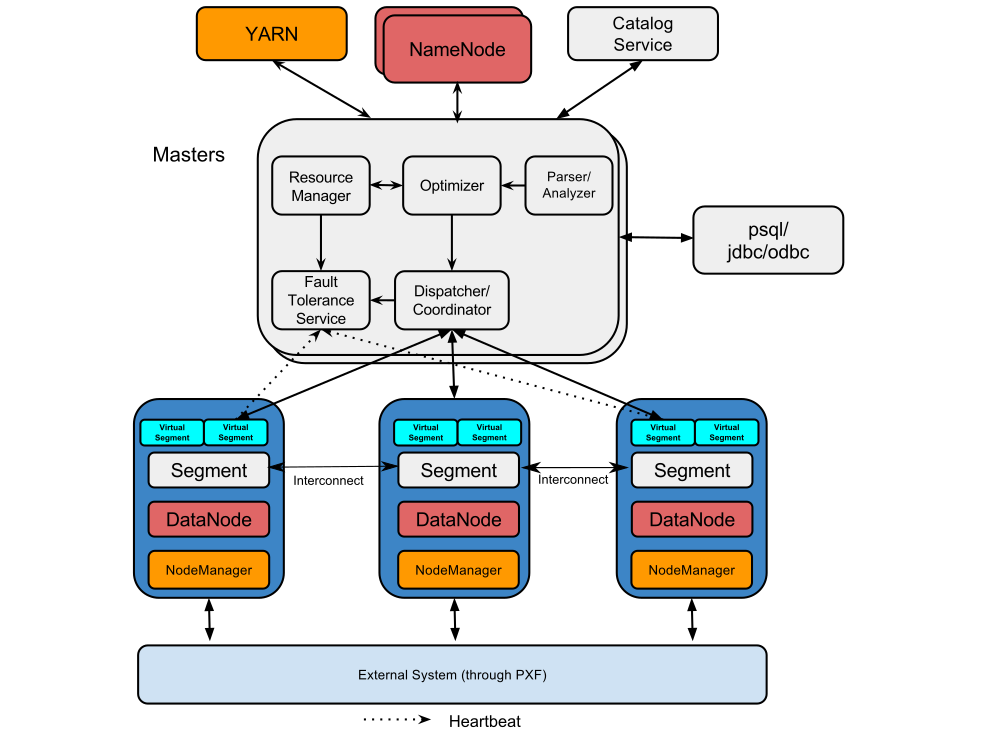
可以看出HAWQ包含了好幾個重要的元件,分別是:
1. HAWQ Master
HAWQ Master是整個系統的介面,它負責接收客戶端查詢請求,解析SQL,優化查詢,分發和協調查詢的執行。當然作為老大,任務肯定不是這麼簡單的,它還得負責
global system catalog的管理工作。 2. HAWQ Segment
Segments是並行處理資料的單元。每一個Slave機器上部署的HAWQ程式叫作物理Segment,而且第一臺Slave上只能部署一個物理Segment。一個物理Segment上可以執行多個虛擬Segment(一個查詢解析後的並行分片就是虛擬Segment).虛擬Segment的數量決定了一個查詢的並行度。
3. HAWQ Interconnect
Segment之間的高速通訊網路,預設採用UDP協議,並且HAWQ軟體提供了針對UDP額外的資料包驗證。使其可靠性接近於TCP,但效能和可擴充套件性又比TCP好。HAWQ也可以使用TCP進行通訊,但有最大1000個Segment的限制。而使用UDP則沒有該限制。
4. HAWQ Resource Manager
HAWQ資源管理用於從YARN獲取資源並響應資源請求。同時HAWQ會快取資源用於低延遲的查詢請求。除了使用YARN來管理資源外,HAWQ還可以使用自帶的資源管理器,而不需要YARN.
5. HAWQ Catalog Service
元資料服務存在於HAWQ Master中。作用肯定就是用於儲存metadata.比如UDF,表資訊等。以及提供元資料的查詢服務。
6. HAWQ Fault Tolerance Service
容錯服務自然就是針對各個Segment節點的狀態監控和失敗處理等工作。
7. HAWQ Dispatcher
HAWQ分發器是則是分發查詢到指定的Segment上和coordinates上進行執行。
3. HAWQ 安裝
如果你安裝過Greenplum,那麼你會發現HAWQ的安裝過程與Greenplum是極期相似,必竟它們兩可以說是不同儲存的版本。而整個安裝過程相對其它實時元件來說,還是比較繁瑣的。同時也可以看出來HAWQ是基於HDFS的獨立資料庫。而不像其它實時查詢元件除了HDFS,可能還需要依賴於其它Hadoop元件。
本文的測試環境為基於CDH 5.5的Hadoop叢集環境的安裝和測試。HAWQ的版本為:2.0.0, 另外HAWQ還可以使用Ambari圖形介面安裝。發竟安裝過程請看:
1. 設定系統引數,更改檔案/etc/sysctl.conf,增加內容:
kernel.shmmax = 1000000000
kernel.shmmni = 4096
kernel.shmall = 4000000000
kernel.sem = 250 512000 100 2048
kernel.sysrq = 1
kernel.core_uses_pid = 1
kernel.msgmnb = 65536
kernel.msgmax = 65536
kernel.msgmni = 2048
net.ipv4.tcp_syncookies = 0
net.ipv4.ip_forward = 0
net.ipv4.conf.default.accept_source_route = 0
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_max_syn_backlog = 200000
net.ipv4.conf.all.arp_filter = 1
net.ipv4.ip_local_port_range = 1281 65535
net.core.netdev_max_backlog = 200000
vm.overcommit_memory = 50
fs.nr_open = 3000000
kernel.threads-max = 798720
kernel.pid_max = 798720
# increase network
net.core.rmem_max=2097152
net.core.wmem_max=2097152 然後使用命令sysctl -p生效
2. 更改檔案/etc/security/limits.conf,增加內容:
* soft nofile 2900000
* hard nofile 2900000
* soft nproc 131072
* hard nproc 131072rpm -ivh epel-release-latest-6.noarch.rpm4. 選擇一臺伺服器上,配置HAWQ安裝的YUM源
#啟動httpd 服務,如果沒有安裝使用yum安裝並啟動:
service httpd start
#解壓hdb 包:
tar -xzvf hdb-2.0.0.0-22126.tar.gz
cd hdb-2.0.0.0 #進到解壓後的目錄
./setup_repo.sh #執行指令碼建立YUM源
#將生成的/etc/yum.repos.d/HDB.repo原始檔拷由到每臺叢集節點上5. 先只在主節點上安裝HAWQ:
yum install hawq6. 在主節點上建立主機名檔案
建立檔案 hostfile包含叢集所有主機(包含MASTER),如:
[root@master hzh]# cat hostfile
master
slave2
slave3
slave4
5.建立檔案僅包含seg(Slave)主機,如:
[root@master hzh]# cat seg_hosts
slave2
slave3
slave47. 打通各主機root使用者ssh
source /usr/local/hawq/greenplum_path.sh
hawq ssh-exkeys -f hostfile #這裡的hostfile就是上面建立的那個檔案8. 然後在每個節點上安裝hawq:
source /usr/local/hawq/greenplum_path.sh
hawq ssh -f hostfile -e "yum install -y epel-release"
hawq ssh -f hostfile -e "yum install -y hawq"9. 在每個節點上增加gpadmin使用者,並設定密碼
hawq ssh -f hostfile -e '/usr/sbin/useradd gpadmin'
hawq ssh –f hostfile -e 'echo -e "changeme\changeme" | passwd gpadmin'10. 在主節點上切換到gpadmin 使用者,打通每個節點的ssh
su - gpadmin
source /usr/local/hawq/greenplum_path.sh
hawq ssh-exkeys -f hostfile11. 檢查安裝是否完成,在gpadmin使用者下執行:
hawq ssh -f hostfile -e "ls -l $GPHOME" #如有輸出目錄檔案則安裝成功12. 建立hawq的資料儲存目錄:
hawq ssh -f hostfile -e 'mkdir -p /hawq/master' #主節點目錄資料存放位置
hawq ssh -f hostfile -e 'mkdir -p /hawq/segment' #segment 節點資料存放目錄
hawq ssh -f hostfile -e 'mkdir -p /hawq/tmp' #spill臨時資料存放目錄,每臺伺服器可以建多個
hawq ssh -f hostfile -e 'chown -R gpadmin /hawq'13.編輯hawq-site.xml檔案在 $GP_HOME/etc/, 如果檔案不存在,直接從template-hawq-site.xml複製一個出來就是,屬性設定包括:
<property>
<name>hawq_dfs_url</name>
<value>localhost:8020/hawq</value> # hdfs的URL, 也可以設定成HDFS HA: <value>hdpcluster/hawq</value>
#注意前面不要帶hdfs://字首
<description>URL for accessing HDFS.</description>
</property>另外還要包括屬性:
| Property | Example Value |
|---|---|
| hawq_master_address_host | mdw |
| hawq_master_address_port | 5432 |
| hawq_standby_address_host | smdw |
| hawq_segment_address_port | 40000 |
| hawq_master_directory | /data/master |
| hawq_segment_directory | /data/segment |
| hawq_master_temp_directory | /data1/tmp,/data2/tmp |
| hawq_segment_temp_directory | /data1/tmp,/data2/tmp |
| hawq_global_rm_type | none |
* 注意如果你需要安裝HAWQ在 secure mode (Kerberos-enabled),則需要設定hawq_global_rm_type為none,來避開已知的安裝問題。 這裡設定為none,就是沒有采用YARN來作資源管理,而使用了自帶的標準模式。
14. 建立HDFS /hawq資料目錄
hadoop fs -mkdir /hawq
hadoop fs -chown gpadmin /hawq15. 建立 $GPHOME/etc/slaves檔案包含所有segment機器的主機名,如:
[root@master etc]# cat slaves
slave2
slave3
slave416.如果HDFS是使用的HA模式,則需要在${GPHOME}/etc/hdfs-client.xml下配置一個hdfs-client.xml檔案。幸好這裡是單機,少配一個.
17. 將以上的hawq-site.xml slaves hdfs-client.xml檔案拷貝到叢集的每個節點上。
18. 準備工作終於作完了,接下來開始幹正事了,初始化HAWQ
chown -R gpadmin /usr/local/hawq-2.0.0.0 #先要給安裝目錄授權,在每一臺
#僅在主節點上,使用gpadmin 使用者執行:
hawq init cluster初始後後,HAWQ就安裝完成啦,你可以使用以下命令檢查叢集狀態:
[gpadmin@master ~]$ hawq state
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:--HAWQ instance status summary
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:------------------------------------------------------
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- Master instance = Active
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- No Standby master defined
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- Total segment instance count from config file = 3
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:------------------------------------------------------
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- Segment Status
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:------------------------------------------------------
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- Total segments count from catalog = 3
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- Total segment valid (at master) = 3
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- Total segment failures (at master) = 0
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- Total number of postmaster.pid files missing = 0
20161122:23:46:07:120722 hawq_state:master:gpadmin-[INFO]:-- Total number of postmaster.pid files found = 34. 使用HAWQ
在HAWQ的使用上跟Greenplum基本就一樣一樣的了。比如:
1. 建立表空間
#選建立filespace,生成配置檔案
[gpadmin@master ~]$ hawq filespace -o hawqfilespace_config
Enter a name for this filespace
> hawqfs
Enter replica num for filespace. If 0, default replica num is used (default=3)
> 0
Please specify the DFS location for the filespace (for example: localhost:9000/fs)
location> master:8020/fs
#執行建立
[gpadmin@master ~]$ hawq filespace --config ./hawqfilespace_config
Reading Configuration file: './hawqfilespace_config'
CREATE FILESPACE hawqfs ON hdfs
('slave2:8020/fs/hawqfs')
20161121:11:26:25:122509 hawqfilespace:master:gpadmin-[INFO]:-Connecting to database
20161121:11:27:38:122509 hawqfilespace:master:gpadmin-[INFO]:-Filespace "hawqfs" successfully created
#再建立表空間
[gpadmin@master ~]$ psql template1
psql (8.2.15)
Type "help" for help.
template1=#
template1=# CREATE TABLESPACE hawqts FILESPACE hawqfs;
CREATE TABLESPACE2. 建立資料庫
template1=# CREATE DATABASE testdb WITH TABLESPACE=hawqts; #指定儲存表空間為hawqts
CREATE DATABASE3. 建立表到新的資料庫中
[[email protected] ~]$ psql testdb //這裡指定連線到新的資料庫中
testdb=# create TABLE books(
testdb(# id integer
testdb(# , isbn varchar(100)
testdb(# , category varchar(100)
testdb(# , publish_date TIMESTAMP
testdb(# , publisher varchar(100)
testdb(# , price money
testdb(# ) DISTRIBUTED BY (id); #指定表的資料打雜湊
CREATE TABLE 建立的表預設都建立在了public schema中,也就是所有使用者都可以訪問,但可以在建表時指定schema. 如: testschema.books
4. 載入資料檔案到表中
testdb=# COPY books(id,isbn,category,publish_date,publisher,price)
testdb-# FROM '/tmp/books'
testdb-# WITH
testdb-# DELIMITER AS '|'
testdb-# ;
COPY 15970428
Time: 41562.606 ms 載入速度達到了 380248條/秒. 還是不錯的
5. 查詢表, HAWQ作為主用於資料倉庫的資料庫在SQL支援方面非常豐富,在標準SQL基礎上,還支援OLAP的視窗函式,視窗函式等。
testdb=# SELECT COUNT(*) FROM books;
count
----------
15970428
(1 row)
Time: 4750.786 ms
//求每個類別下的最高價,最低價
testdb=# SELECT category, max(price) max_price, min(price) min_price
testdb-# FROM books
testdb-# group by category
testdb-# LIMIT 5;
category | max_price | min_price
----------------+-----------+-----------
COMPUTERS | $199.99 | $5.99
SELF-HELP | $199.99 | $5.99
COOKING | $199.99 | $5.99
SOCIAL-SCIENCE | $199.99 | $5.99
SCIENCE | $199.99 | $5.99
(5 rows)
Time: 4755.163 ms
//求每類別下的最高,最小价格,及對應的BOOK ID
testdb=# SELECT category
testdb-# , max(case when desc_rn = 1 then id end) max_price_id, max(case when desc_rn = 1 then id end) max_price
testdb-# , max(case when asc_rn = 1 then id end) min_price_id, max(case when asc_rn = 1 then id end) min_price
testdb-# FROM (
testdb(# SELECT id, category, price
testdb(# , row_number() over(PARTITION BY category ORDER BY price desc) desc_rn
testdb(# , row_number() over(PARTITION BY category ORDER BY price asc) asc_rn
testdb(# FROM books
testdb(# ) t
testdb-# WHERE desc_rn = 1 or asc_rn = 1
testdb-# GROUP BY category
testdb-# limit 5;
category | max_price_id | max_price | min_price_id | min_price
----------------+--------------+-----------+--------------+-----------
CRAFTS-HOBBIES | 86389 | $199.99 | 7731780 | $5.99
GAMES | 5747114 | $199.99 | 10972216 | $5.99
STUDY-AIDS | 2303276 | $199.99 | 13723321 | $5.99
ARCHITECTURE | 9294400 | $199.99 | 7357451 | $5.99
POETRY | 7501765 | $199.99 | 554714 | $5.99
(5 rows)
Time: 23522.772 ms5. 使用HAWQ查詢HIVE資料
HAWQ是一個基於HDFS的一個獨立的資料庫系統,若需要訪問其它第三方資料,則還需要再安裝HAWQ Extension Framework (PXF) 外掛。PXF支援在HDFS上的HIVE, HBASE資料,還支援使用者開發自定義的其它並行資料來源的聯結器。
6. 問題
7. 最後
HAWQ作為一個從Greenplum更改過來的系統,在功能上支援上還是非常豐富的,除了上面介紹的查詢功能外,還支援像PL/Java, PL/Perl, PL/pgSQL, PL/Python, PL/R等儲存過程。但個人覺得,它最大的缺點就是這是一個獨立的資料庫,在當前的這樣一個具有多種多樣元件的HADOOP平臺上,不能實現資料共享,進而根據不同場景採用多種資料處理方式著實是一大遺憾。
相關推薦
構建於HDFS之上的Greenplum: HAWQ
1. HAWQ 是什麼 如果你知道Greenplum是什麼,那麼你就能很簡單的明白HAWQ是什麼。Greenplum是一個關係型的分散式MPP資料庫,同樣運行於X86架構的基礎之上,具有查詢、載入效率高,支援TB/PB級大資料量的OLAP應用, Green
Hawq學習筆記 --- 構建於HDFS之上的Greenplum(實時查詢引擎)
2. HAWQ 結構 HAWQ在結構仍然是Master-Slave的主從模式,典型的部署方式仍然是在Master伺服器上部署:HAWQ Master, HDFS Master, YARN ResouceManager, 在每一個SLAVE機器上部署: HAWQ segment, DataNode,
MQTT是IBM開發的一個即時通訊協議,構建於TCP/IP協議上,是物聯網IoT的訂閱協議,借助消息推送功能,可以更好地實現遠程控制
集合 cap 消息處理 簡易 遠程控制 mes ogr 設計思想 成本 最近一直做物聯網方面的開發,以下內容關於使用MQTT過程中遇到問題的記錄以及需要掌握的機制原理,主要講解理論。 背景 MQTT是IBM開發的一個即時通訊協議。MQTT構建於TCP/IP協議上
hdfs的使用:
sub 上傳文件 AD mit 查看分區 cat 狀態 rom com 1)、----使用hdfs命令,切換hdfs用戶 hdfs dfs -du -h /zxvmax/telecom/union/dm/dm_mdn_imsi_terni //查看分區大小
[HDFS-inotify]“IOException:客戶端在讀取檔案後停止
1.我想寫下一個在建立時在特定位置讀取檔案的程式碼(使用inotify) 所以我在github中修改了基於“hdfs-inotify-example”的示例程式碼https://github.com/onefoursix/ HDFS-的inotify-示例/
訪問HDFS報錯:org.apache.hadoop.security.AccessControlException: Permission denied
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class TestHDFS { publ
HDFS基礎1:HDFS的常用命令
前言 HDFS系統中不能使用touch命令來建立普通檔案。 1 檔案操作 (1)列出HDFS下的檔案 (2)刪除HDFS下的檔案或目錄 hdfs dfs -rm -r /[檔案或目錄] (3)檢視HDFS下檔案的內容 hdfs dfs -c
HDFS檢視異常:Operation category READ is not supported in state standby. Visit
跨叢集訪問hdfs失敗 $ hdfs dfs -ls hdfs://test:8020/hbase ls: Operation category READ is not supported in state standby. Visit https://s.apache.org/
【圖文詳細 】HDFS面試題:hadoop1.x和2.x架構上的區別
(1)Hadoop 1.0 Hadoop 1.0即第一代Hadoop,由分散式儲存系統HDFS和分散式計算框架MapReduce組成,其中,HDFS由一個NameNode和多個DataNode組成,MapReduce由一個JobTracker和多個TaskTracker組成,對應Hadoop
【圖文詳細 】HDFS面試題:hadoop的守護執行緒以及Namenode的職責是什麼
五個守護程序: SecondaryNameNode ResourceManager NodeManager NameNode DataNode Namenode:主節點,儲存檔案的元資料(檔名,檔案目錄結構,檔案屬性——生成時間,副本數,檔案許可權),以及每個檔案的塊列表
【圖文詳細 】HDFS面試題:介紹Hadoop中RPC協議,以及底層用什麼框架封裝的
用於將使用者請求中的引數或者應答轉換成位元組流以便跨機傳輸。 函式呼叫層:函式呼叫層主要功能是:定位要呼叫的函式,並執行該函式,Hadoop採用了java的反射機制和動態代理實現了函式的呼叫。 網路傳輸層:網路傳輸層描述了Client和Server之間訊息的傳輸方式,Hadoop採用了基
【圖文詳細 】HDFS面試題:hdfs裡的 edits和 fsimage作用
1)、fsimage檔案其實是Hadoop檔案系統元資料的一個永久性的檢查點,其中包含Hadoop檔案系統中的所有目錄和檔案idnode的序列化資訊; 2)、edits檔案存放的是Hadoop檔案系統的所有更新操作的路徑,檔案系統客戶端執行的所以寫操作首先會被記錄到edits檔案中。
【圖文詳細 】HDFS面試題:hdfs 的資料壓縮演算法?
(1) Gzip 壓縮 優點:壓縮率比較高,而且壓縮/解壓速度也比較快; hadoop 本身支援,在應用中處理gzip 格式的檔案就和直接處理文字一樣;大部分 linux 系統都自帶 gzip 命令,使用方便. 缺點:不支援 split。 應用場景: 當每個檔案壓縮之後在 130M
【圖文詳細 】HDFS面試題:hdfs的回收站(防止誤刪)
預設是關閉的,需要手動開啟,修改配置 core-site.xml 新增:
即構科技金健忠:回顧20年音視訊技術演進
多媒體技術是一個傳統行業,從模擬到數字,VCD到藍光,從窄帶到寬頻,標清到高清,技術演進讓人的視聽體驗發生了顛覆式的改變。LiveVideoStack採訪了即構科技CTO金健忠,他回顧了過去20年多媒體技術的發展,並展望了未來的技術趨勢。 文 / 金健忠 策劃 /
大資料雲平臺 Greenplum:多租戶篇
什麼是多租戶 多租戶指一套系統能夠支撐多個租戶。一個租戶通常是具有相似訪問模式和許可權的一組使用者,典型的租戶是同一個組織或者公司的若干使用者。 要實現多租戶,首先需要考慮的是資料層面的多租戶。資料層的多租戶模型對上層服務和應用的多租戶實現有突出影響。本文重點
hdfs常用命令:一
檔案操作 (1) 列出HDFS下的檔案 hdfs dfs -ls / (2) 列出HDFS檔案下名為users的文件中的檔案 hdfs dfs -ls /users (3) 上傳檔案 將hadoop目錄下的test01檔案上傳到HDFS上並重
Ranger配置HDFS報錯:curl: (3) [globbing] nested braces not supported at pos 2
Ambari上顯示錯誤資訊: 2017-11-06 13:01:00,618 - Will retry 65 time(s), caught exception: (u"Execution of 'curl --location-trusted -k --negotiat
構建於 B/S 端的 3D 攝像頭視覺化監控方案
前言 隨著視訊監控聯網系統的不斷普及和發展, 網路攝像機更多的應用於監控系統中,尤其是高清時代的來臨,更加快了網路攝像機的發展和應用。 在監控攝像機數量的不斷龐大的同時,在監控系統中面臨著嚴峻的現狀問題:海量視訊分散、孤立、視角不完整、位置不明確等問題,始終圍繞著使用者。因此,如何更直觀、更明確的管理攝像機和
C++筆記(11):拷貝控制(拷貝移動,構造賦值,析構)
con 對象 構造函數 col let 拷貝控制 支持 運算符 () 控制對象拷貝,賦值,析構 拷貝構造函數,移動構造函數 拷貝賦值運算符,移動賦值運算符 析構函數 -----------------------------------------------