
作業系統概念(第九章) 虛擬記憶體
背景
第八章所介紹的記憶體管理演算法都是基於一個基本要求:執行指令必須在實體記憶體中,滿足這一要求的第一種方法是整個程序放在記憶體中。動態載入能幫助減輕這一限制,但是它需要程式設計師特別小心地做一些額外的工作。
指令必須都在實體記憶體內的這一限制,似乎是必須和合理的,但也是不幸的,因為這使得程式的大小被限制在實體記憶體的大小內。事實上,研究實際程式會發現,許多情況下並不需要將整個程式放到記憶體中。即使在需要完整程式的時候,也並不是同時需要所有的程式。
因此執行一個部分在記憶體中的程式不僅有利於系統,還有利於使用者。
虛擬記憶體(virtual memory)將使用者邏輯記憶體和實體記憶體分開。這在現有實體記憶體有限的情況下,為程式設計師提供了巨大的虛擬記憶體。
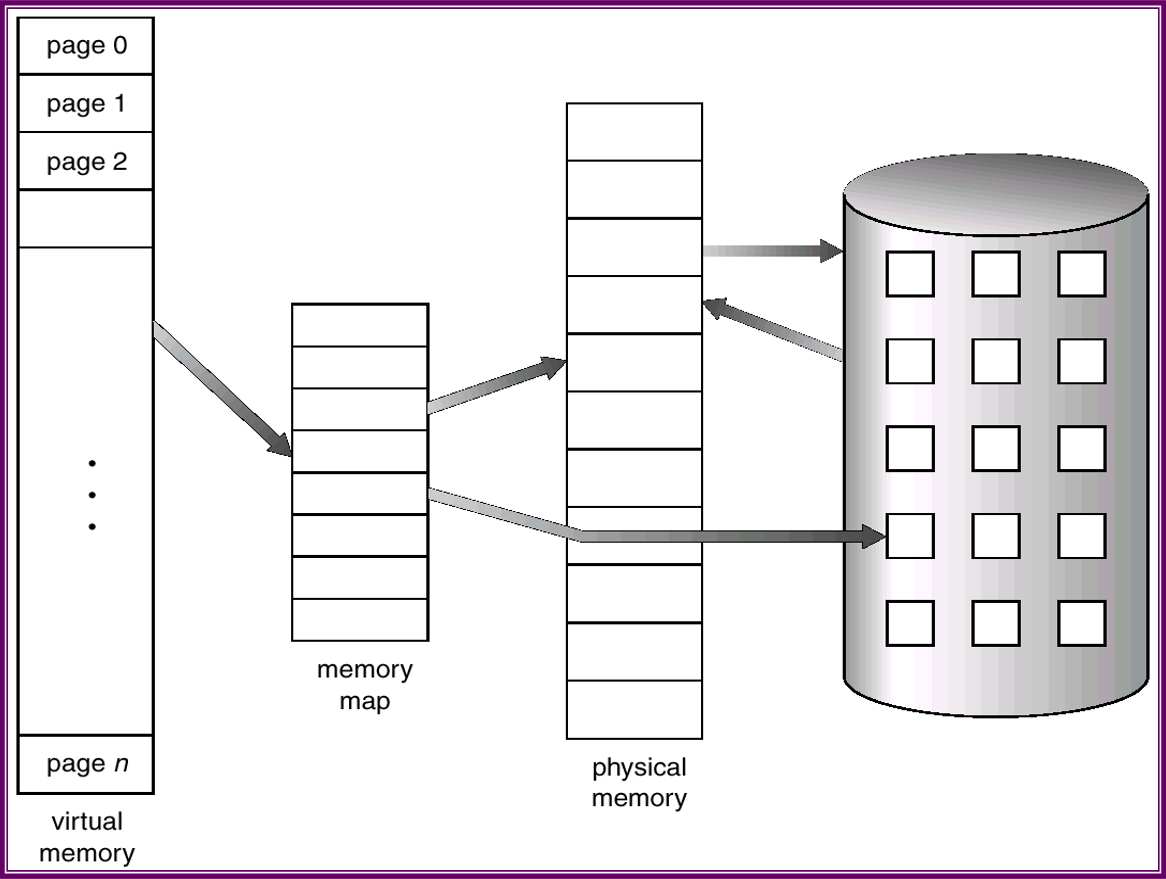
程序的虛擬地址空間就是程序如何在記憶體中存放的邏輯(或虛擬)檢視。通常,該檢視為程序從某一個邏輯地址(如地址0)開始,連續存放。

根據第八章,實體地址可以按頁幁來組織,且分配給程序的物理頁幀也可能不是連續的。這就需要記憶體管理單元(MMU)將邏輯頁對映到記憶體的物理頁幀。
如上圖顯示,執行隨著動態記憶體的分配,堆可向上生長。類似地,還允許隨著子程式的不斷呼叫,棧可以向下生長。堆與棧之間的巨大空白空間(或hole)為虛擬地址的一部分,只有在堆與棧生長的時候,才需要實際的物理頁。包括空白的虛擬地址空間成為稀地址空間,採用稀地址空間的優點是:隨著程式的執行,棧或者堆段的生長或需要載入動態連結庫(或共享物件)時,這些空白可以填充。
除了將邏輯記憶體與實體記憶體分開,虛擬記憶體也允許檔案和記憶體通過共享頁而為兩個或者多個程序所共享,這樣帶來了如下的有點:
- 通過將共享物件對映到虛擬地址空間,系統庫可為多個程序所共享。雖然每個程序都認為共享庫是其虛擬地址空間的一部分,而共享庫所用的實體記憶體的實際頁是為所有程序所共享。通常,庫是按制度方式來連結每個程序的空間的。
- 類似的,虛擬記憶體允許程序共享記憶體。兩個或者多個程序之間可以通過使用共享記憶體來相互通訊。虛擬記憶體允許一個程序建立記憶體區域,以便與其他程序進行共享。共享該記憶體區域的程序認為它是其虛擬地址空間的一部分,而事實上這部分是共享的。
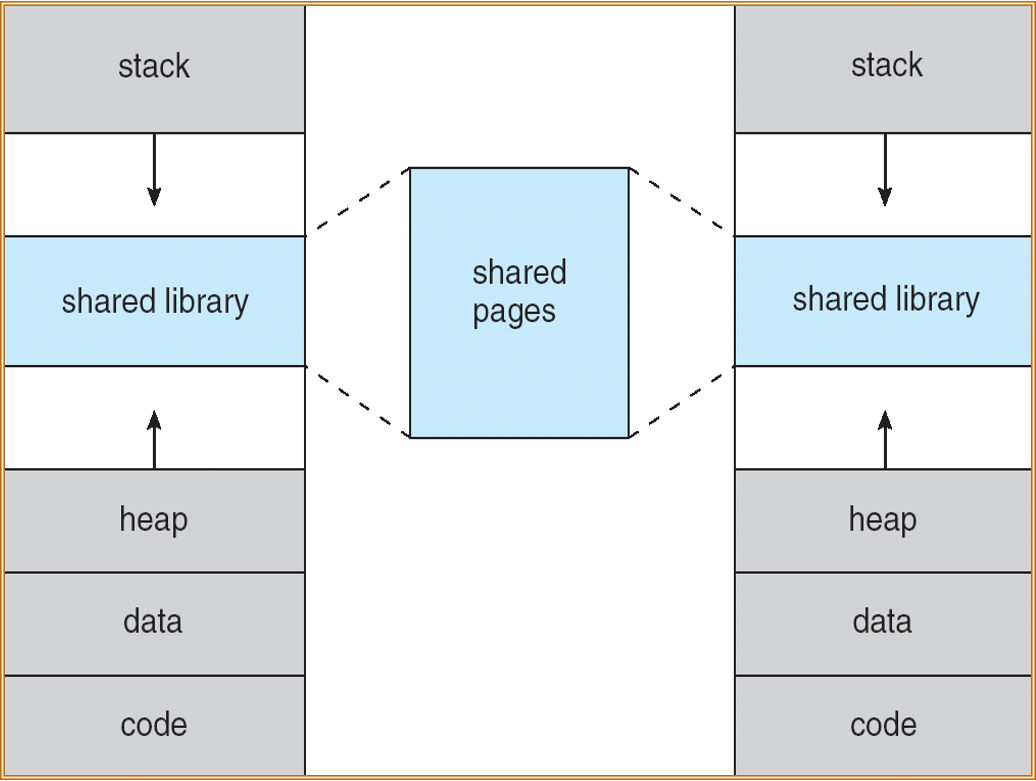
- 虛擬記憶體可允許在用系統呼叫fork()建立程序期間共享頁,從而加快程序的建立。
按需調頁
一個執行程式從磁碟載入記憶體的時候有兩種方法。
1. 選擇在程式執行時,將整個程式載入到記憶體中。不過這種方法的問題是可能開始並不需要整個程式在記憶體中。如有的程式開始時帶有一組使用者可選的選項。載入整個程式,也就將所有選項的執行程式碼都載入到記憶體中,而不管這些選項是否使用。
2. 另一種選擇是在需要時才調入相應的頁。這種技術稱為按需調頁(demand paging)
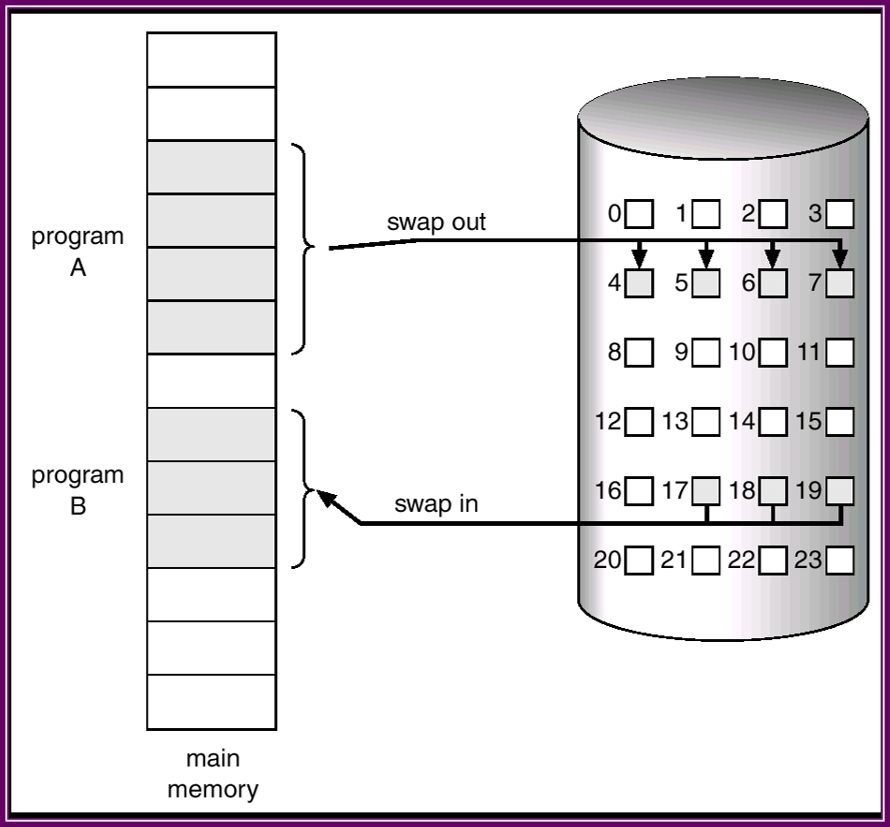
按需調頁系統看類似於使用交換的分頁系統,程序駐留在第二級儲存器上(通常為磁碟)。當需要執行程序時,將它換入記憶體。不過,不是講整個程序換入記憶體,而是使用懶惰交換(lazy swapper)。懶惰交換隻有在需要頁時,才將它調入記憶體。由於將程序看做是一系列的頁,而不是一個大的連續空間,因此使用交換從技術上來講並不正確。交換程式(swapper)對整個程序進行操作,而調頁程式(pager)只是對程序的單個頁進行操作。因此, 在討論有關按需調頁時,需要使用調頁程式而不是交換程式。
基本概念
當換入程序時,調頁程式推測在該程序再次換出之前使用到的哪些頁,僅僅把需要的頁調入記憶體。從而減少交換時間和所需的實體記憶體空間。
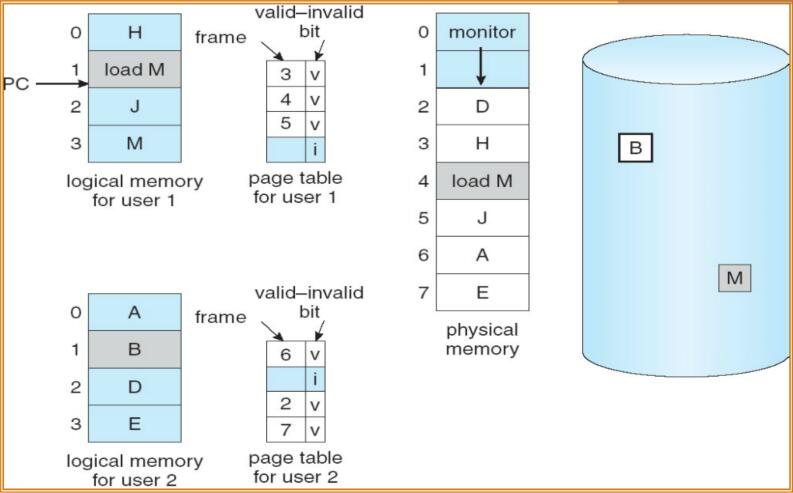
這種方案需要硬體支援區分哪些頁在記憶體,哪些在磁碟。採用有效/無效位來表示。當頁表中,一個條目的該位為有效時,表示該頁合法且在記憶體中;反之,可能非法,也可能合法但不在記憶體中。

如果程序從不試圖訪問標記為無效的頁,那麼並沒有什麼影響,因此,如果推測正確且只調入所有真正需要的頁,那麼程序就可如同所有頁都調入記憶體一樣正常執行。
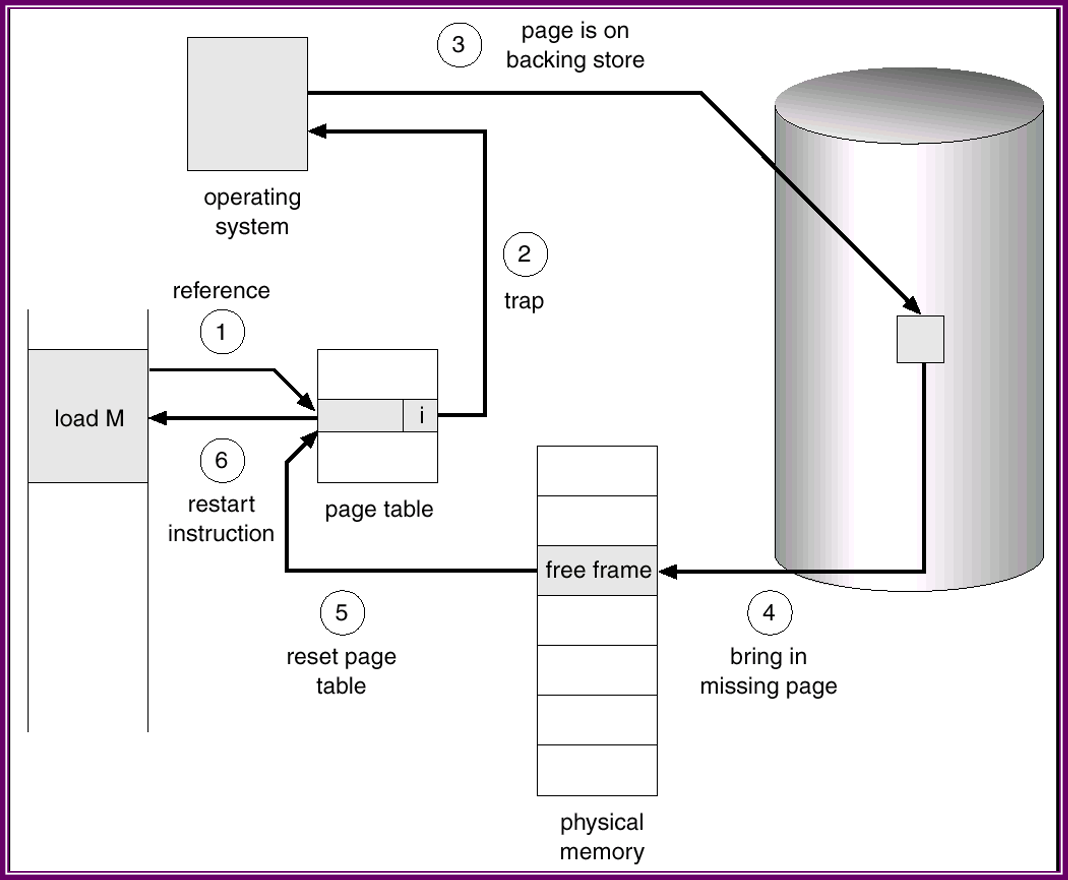
當程序試圖訪問這些尚未調入記憶體的頁時,會引起頁錯誤陷阱(page-fault trap)。這種情況的處理方式如下:
- 1)檢查程序的內部頁表(通常與PCB一起儲存)。以確定該引用是的合法還是非法的地址訪問。
- 2)如果非法,則終止程序;如果引用有效但是尚未調入頁面,則現在進行調入。
- 3)找到一個空閒幀(如,從空閒幀表中選取一個)。
- 4)排程一個磁碟操作,以便將所需頁調入剛分配的幀
- 5)磁碟讀操作完成後,修改程序的內部表和頁表,表示該頁已在記憶體中。
- 6)重新開始因陷阱而中斷的指令。
例如,block move 問題。
MVC指令能夠移動256B。
- 塊可能跨越頁邊界
- 移動部分字元後出現頁錯誤
- 如果源和目的塊有重疊
- 源塊可能已經被修改
解決方案:
- 試圖存取兩個塊的兩端
- 使用臨時暫存器儲存被覆蓋位置的值
按需調頁的效能
按需調頁對計算機系統的效能有重要影響,下面計算一下關於按需調頁記憶體的有效訪問時間(effective access time)。
設
如果
如果
其中頁錯誤時間有很多,主要是下面三種:
- 處理頁錯誤中斷
- 讀入頁(頁換入時間)
- 重新啟動程序
按需調頁的例子
記憶體存取時間
平均頁錯誤服務時間
如果每次1000次訪問中有1次頁錯誤,則
因此來看,對於按需調頁,降低頁錯誤率至關重要。
另外是對交換空間的處理的使用。磁碟IO到交換空間通常比到檔案系統要快,因為交換空間是按大塊進行分配,並不使用檔案查詢和間接分配方法。因此,在程序開始時將整個檔案映象複製到交換空間,並從空間交換執行按頁排程,那麼有可能獲得更好的效能。
另一種選擇是開始時從檔案系統進行按需調頁,但置換出來的頁寫入交換空間,而後的調頁則從交換空間中讀取。這種方法確保只有需要的頁才從檔案系統中調入,又可以保證一定的效能。
寫時複製
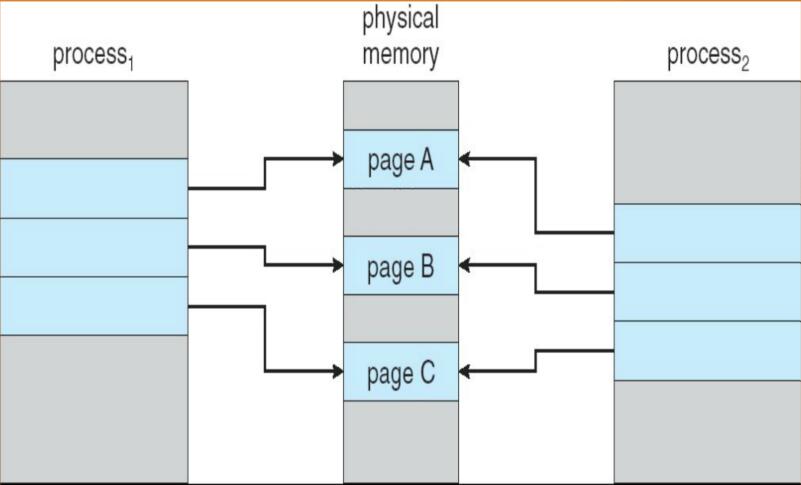
寫時複製Copy-on-Write (COW) 執行父程序與子程序開始時共享同一頁面,這些頁面標記為寫時複製頁,即如果任何一個程序需要對頁進行寫操作,那就建立一個共享頁的副本。
因為指標及那些能夠被修改的頁,所以建立程序的過程更有效率。
寫時複製所需的空閒也老子一個空閒緩衝池,系統通常用按需填零(zero-fill-on-demand)的技術分配這些頁。按需填零在需要分配之前先填零,因此清除了以前的內容。
下面的兩個過程提箱了程序1修改C前後的實體記憶體的情況。
after
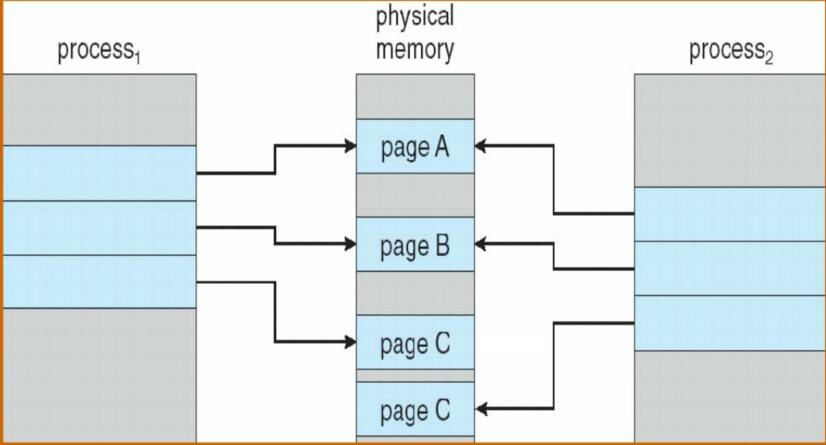
如果沒有空閒幀時該如何處理呢?
- 頁替換:在記憶體中找到一些不再使用的頁,將它換出去。
- 一些頁可能被多次載入如記憶體。
頁面置換
作業系統為何要進行頁面置換呢?這是由於作業系統給使用者態的應用程式提供了一個虛擬的“大容量”記憶體空間,而實際的實體記憶體空間又沒有那麼大。所以作業系統就就“瞞著”應用程式,只把應用程式中“常用”的資料和程式碼放在實體記憶體中,而不常用的資料和程式碼放在了硬碟這樣的儲存介質上。如果應用程式訪問的是“常用”的資料和程式碼,那麼作業系統已經放置在記憶體中了,不會出現什麼問題。但當應用程式訪問它認為應該在記憶體中的的資料或程式碼時,如果這些資料或程式碼不在記憶體中,則根據上文的介紹,會產生缺頁異常。這時,作業系統必須能夠應對這種缺頁異常,即儘快把應用程式當前需要的資料或程式碼放到記憶體中來,然後重新執行應用程式產生異常的訪存指令。如果在把硬碟中對應的資料或程式碼調入記憶體前,作業系統發現物理記憶體已經沒有空閒空間了,這時作業系統必須把它認為“不常用”的頁換出到磁碟上去,以騰出記憶體空閒空間給應用程式所需的資料或程式碼。
作業系統遲早會碰到沒有記憶體空閒空間而必須要置換出記憶體中某個“不常用”的頁的情況。如何判斷記憶體中哪些是“常用”的頁,哪些是“不常用”的頁,把“常用”的頁保持在記憶體中,在實體記憶體空閒空間不夠的情況下,把“不常用”的頁置換到硬碟上就是頁面置換演算法著重考慮的問題。容易理解,一個好的頁面置換演算法會導致缺頁異常次數少,也就意味著訪問硬碟的次數也少,從而使得應用程式執行的效率就高。
下面提供了一種需要頁置換的情況。
基本頁置換
基本頁置換採用方法如下。
- 查詢需要頁在磁碟上的位置。
- 查詢一空閒幀:
- 如果有空閒幀,那麼就使用它
- 如果沒有空閒幀,那麼就是用頁置換演算法選擇一個“犧牲”幀(victim frame)
- 將犧牲幀的內容放到磁碟上,改變頁表和幀表。
- 將所需頁讀入(新)空閒幀,改變頁表和幀表。
- 重啟使用者程序。
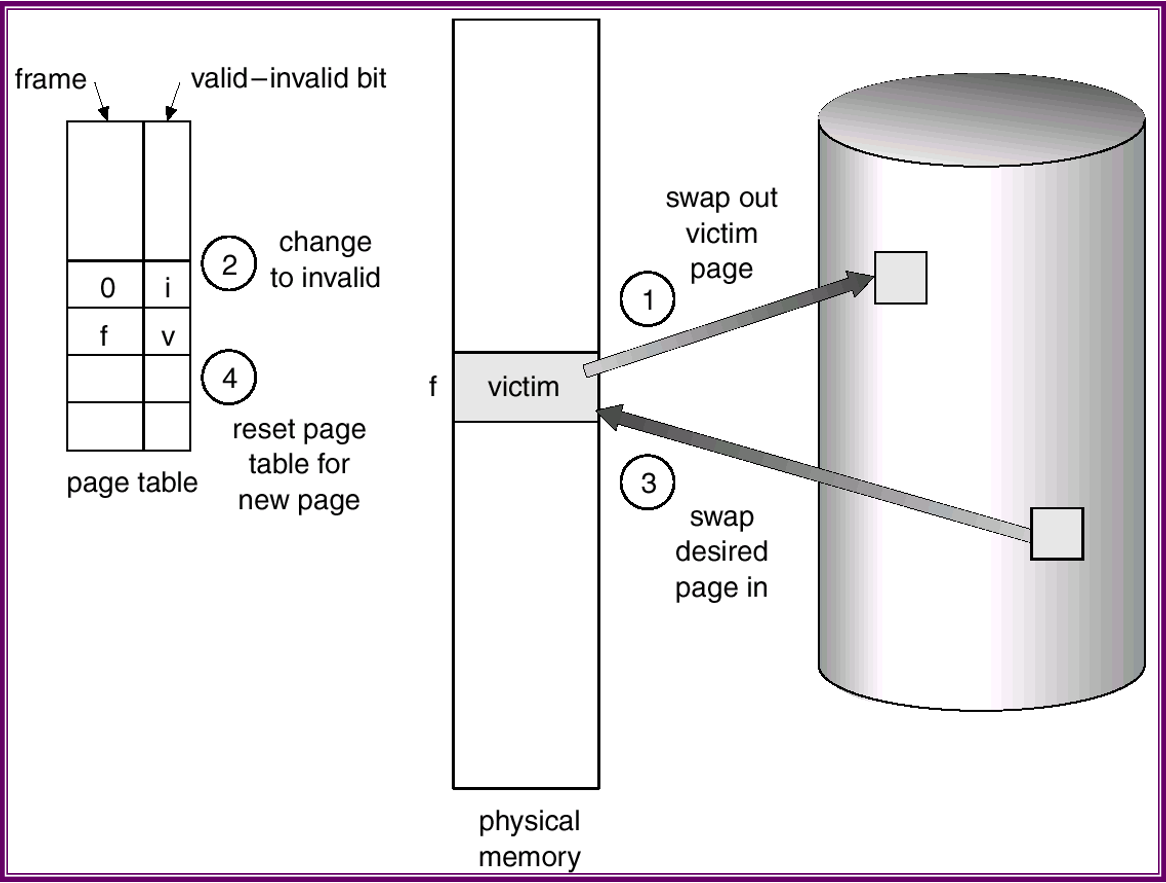
頁置換是按需調頁的基礎。為鎖骨下班按需調頁,必須解決兩個主要問題:必須開發幀分配演算法(frame-allocation algorithm)和頁置換演算法(page-replacement algorithm)。如果在記憶體中有多個程序,那麼必須決定為每個程序各分配多少幀。而且,當需要頁置換時,必須選擇要置換的幀。
可以這樣來評估一個演算法:針對特定記憶體引用序列,執行某個置換演算法,並計算出頁錯誤的數量。記憶體的引用序列成為引用串(reference string)。
第一,對給定頁大小(頁大小通常由硬體或系統來決定),只需要考慮頁碼,而不需要完整的地址。第二,如果有一個頁
FIFO頁置換
該演算法總是淘汰最先進入記憶體的頁,即選擇在記憶體中駐留時間最久的頁予以淘汰。只需把一個應用程式在執行過程中已調入記憶體的頁按先後次序連結成一個佇列,佇列頭指向記憶體中駐留時間最久的頁,佇列尾指向最近被調入記憶體的頁。這樣需要淘汰頁時,從佇列頭很容易查詢到需要淘汰的頁。FIFO演算法只是在應用程式按線性順序訪問地址空間時效果才好,否則效率不高。因為那些常被訪問的頁,往往在記憶體中也停留得最久,結果它們因變“老”而不得不被置換出去。FIFO演算法的另一個缺點是,它有一種異常現象(Belady現象),即在增加放置頁的頁幀的情況下,反而使缺頁異常次數增多。
問題:隨機一訪問串和駐留集的大小,通過模擬程式顯示淘汰的頁號並統計命中率。示例:
輸入訪問串:7 0 1 2 0 3 0 4 2 3 0 3 2 1 2 0 1
駐留集大小:3

紅色表示:指標指向調入記憶體的頁面中“最老“的頁面
通過模擬程式輸出淘汰的頁號分別為:7 0 1 2 3 0 4 2 3
命中率為:
注意:記憶體的頁面中“最老“的頁面,會被新的網頁直接覆蓋,而不是“最老“的頁面先出隊,然後新的網頁從隊尾入隊。
最優(Optimal)置換
由Belady於1966年提出的一種理論上的演算法。其所選擇的被淘汰頁面,將是以後永不使用的或許是在最長的未來時間內不再被訪問的頁面。採用最佳置換演算法,通常可保證獲得最低的缺頁率。但由於作業系統其實無法預知一個應用程式在執行過程中訪問到的若干頁中,哪一個頁是未來最長時間內不再被訪問的,因而該演算法是無法實際實現,但可以此演算法作為上限來評價其它的頁面置換演算法。
LRU(Least Recently Used)頁置換
FIFO置換演算法效能之所以較差,是因為它所依據的條件是各個頁調入記憶體的時間,而頁調入的先後順序並不能反映頁是否“常用”的使用情況。
最近最久未使用(LRU)置換演算法,是根據頁調入記憶體後的使用情況進行決策頁是否“常用”。由於無法預測各頁面將來的使用情況,只能利用“最近的過去”作為“最近的將來”的近似,因此,LRU置換演算法是選擇最近最久未使用的頁予以淘汰。該演算法賦予每個頁一個訪問欄位,用來記錄一個頁面自上次被訪問以來所經歷的時間t,,當須淘汰一個頁面時,選擇現有頁面中其t值最大的,即最近最久未使用的頁面予以淘汰。
問題:隨機一訪問串和駐留集的大小,通過模擬程式顯示淘汰的頁號並統計命中率。示例:
輸入訪問串:7 0 1 2 0 3 0 4 2 3 0 3 2
駐留集大小:3
演算法的實現:由於LRU演算法淘汰的是上次使用距離t時刻最遠的頁,故需記錄這個距離。
有兩張方法:
計數器:為每個頁表項關聯一個使用時間域,併為CPU增加一個邏輯時鐘或計數器。對每次記憶體引用,計數器都會增加。每次記憶體引用時,時鐘暫存器的內容會複製到相應頁所對應頁表項的使用時間域內。置換具有最小時間的頁,這種方案需要搜尋頁表以查詢LRU頁,且每次記憶體訪問都要寫入記憶體。在頁表改變時也必須要保證時間,必須考慮時鐘溢位。
堆疊:實現LRU置換的另一個方法是採用頁碼堆疊。每當引用一個頁,該頁就從堆疊中刪除並放在頂部,這樣,堆疊底部總是LRU頁,該堆疊可實現為具有頭指標和尾指標的雙向連結串列
每次記憶體引用都必須更新時鐘域或堆疊,如果每次引用都採用中斷,以允許軟體更新這些資料結構,那麼它會使記憶體引用慢至少10倍

紅色表示:每個頁幀對應的計數器值
通過模擬程式輸出淘汰的頁號分別為:7 1 2 3 0 4
命中率為:
LRU的另一種通俗理解:
例如一個三道程式,等待進入的是1,2,3,4,4,2,5,6,3,4,2,1。先分別把1,2,3匯入,然後匯入4,置換的是1,因為他離匯入時間最遠。然後又是4,不需要置換,然後是2,也不需要,因為記憶體中有,到5的時候,因為3最遠,所以置換3,依次類推。
注意:雖然兩個演算法都是用佇列這種資料結構實現的,但具體操作不完全遵從佇列的原則。這一點不必糾結。
命中率是指在隊滿的情況下,新的元素的加入,不影響佇列其它元素。即該元素已存在在佇列中。
OPT、LRU以及FIFO演算法的對比圖如下所示:

近似LRU頁置換
很少有計算機系統能夠提供足夠的硬體來支援真正的LRU頁置換。有的系統不提供任何支援,因此必須使用其他置換演算法。然而,許多系統都通過應用為方式提供一定支援,頁表內的每項都關聯著一個引用位(reference bit),每當引用一個頁時,相應頁表的引用位就會被引腳置位。如新增一個8bit的引用位(極端情況下只有一個引用位,即二次機會演算法)。每個時鐘都向右移位,引用的話高位置1,否則置0。
開始,作業系統會將所有引用位都清零。隨著使用者程序的執行,與引用頁相關聯的引用位被硬體置位。通過檢查引用位,能確定那些用過而那些沒用過。這種部分排序資訊導致了許多近似LRU演算法的頁置換演算法。
- 附加引用位演算法:
- 可以為位於記憶體中的每個表中的頁保留一個8bit的位元組。作業系統把每個頁的引用位轉移到其8bit位元組的高位,而將其他位右移,並拋棄最低位。如果將8bit位元組作為無符號整數,那麼具有最小值的頁為LRU頁,且可以被置換。
- 二次機會演算法:
- 二次機會置換的基本演算法是FIFO置換演算法。當要選擇一個頁時,檢查其引用位。如果其值為0,那麼就直接置換該頁。如果引用位為1,那麼就給該頁第二次機會,並選擇下一個FIFO頁。當一個頁獲得第二次機會時,其引用位清零。且其到達時間設為當前時間。因此獲得第二次機會的頁,在所有其他頁置換之前,是不會被置換的。另外,如果一個頁經常使用以致於其引用位總是得到設定,那麼它就不會被置換。
- 一種實現二次機會演算法的方法是採用迴圈佇列。用一個指標表示下次要置換哪個頁。當需要一個幀時,指標向前移動直到找到一個引用位為0的頁。在向前移動時,它將清除引用位。
- 增強型二次機會演算法
- 通過將引用位和修改位作為一個有序對來考慮,能增強二次機會演算法。有下面四種可能型別:
- 1 (0,0)最近沒有使用且也沒有修改。—用於置換的最佳頁
- 2 (0,1)最近沒有使用但修改過。—不是很好,因為在置換之前需要將頁寫出到磁碟
- 3 (1,0)最近使用過但沒有修改—它有可能很快又要被使用
- 4 (1,1)最近使用過且修改過—它有可能很快又要被使用,且置換之前需要將頁寫出到磁碟
- 通過將引用位和修改位作為一個有序對來考慮,能增強二次機會演算法。有下面四種可能型別:
當頁需要置換時,每個頁都屬於這四種類型之一。置換在最低非空型別中所碰到的頁,可能要多次搜尋整個迴圈佇列。
基於計數的頁置換
有如下兩種演算法:
1. 最不經常使用頁置換演算法(LFU)
2. 最常使用頁置換演算法(MFU)
這兩種演算法的實現都很費時,且不能很好地近似OPT置換演算法。
頁緩衝演算法
系統通常保留一個空閒幀緩衝池。當出現頁錯誤時,會像以前一樣選擇一個犧牲幀,在犧牲幀寫出之前,所需要的頁就從緩衝池中讀到空閒記憶體。
幀分配
如何在各個程序之間分配一定的空閒記憶體?
簡單辦法是將幀掛在空閒幀連結串列上,當發生頁錯誤之時即進行分配。程序終止時幀再次放回空閒幀連結串列。
幀分配策略受到多方面限制。例如, 分配數不能超過可用幀數,也必須分配至少最少數量。保證最少量的原因之一是效能。頁錯誤增加會減慢程序的執行。並且,在指令完成前出現頁錯誤,該指令必須重新執行。所以有足夠的幀至關重要。
每個程序幀的最少數量由體系結構決定,而最大數量是由可用實體記憶體數量決定。
分配演算法
1)平均分配,每個程序一樣多
2)按程序大小使用比例分
3)按程序優先順序分
4)大小和優先順序組合分
全域性分配和區域性分配
全域性置換允許程序從所有幀集合中選擇一個進行置換,而不管該幀是否已分配給其他程序,即它可以從其他程序搶奪幀,比如高優先順序搶奪低優先順序的幀;區域性分配則要求每個程序只能從自己的分配幀中分配。
全域性置換通常有更好的吞吐量,且更為常用。