
機器學習與資料探勘-K最近鄰(KNN)演算法的實現(java和python版)
阿新 • • 發佈:2019-02-07
KNN演算法基礎思想前面文章可以參考,這裡主要講解java和python的兩種簡單實現,也主要是理解簡單的思想。
python版本:
這裡實現一個手寫識別演算法,這裡只簡單識別0~9熟悉,在上篇文章中也展示了手寫識別的應用,可以參考:機器學習與資料探勘-logistic迴歸及手寫識別例項的實現
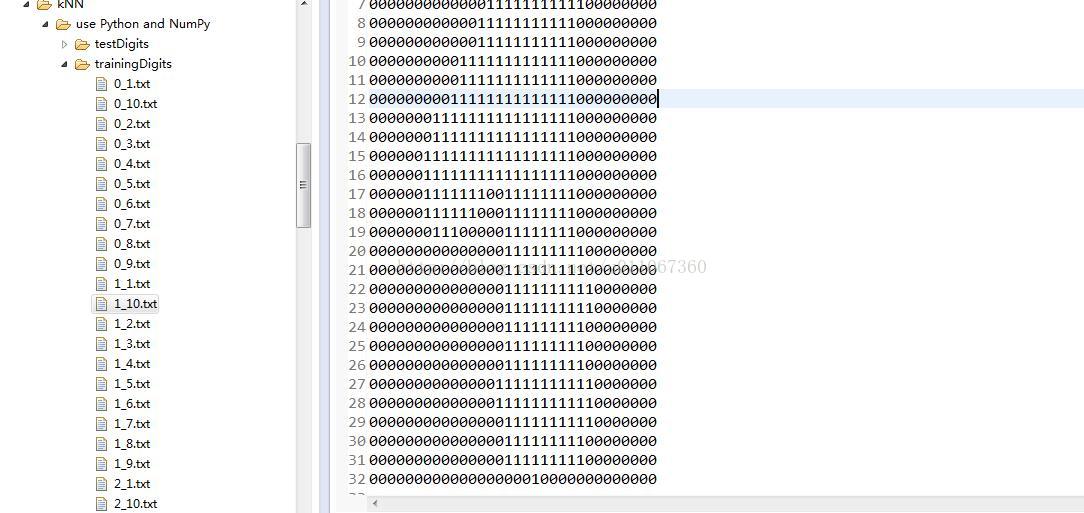
輸入:每個手寫數字已經事先處理成32*32的二進位制文字,儲存為txt檔案。0~9每個數字都有10個訓練樣本,5個測試樣本。訓練樣本集如下圖:左邊是檔案目錄,右邊是其中一個檔案開啟顯示的結果,看著像1,這裡有0~9,每個數字都有是個樣本來作為訓練集。
第一步:將每個txt文字轉化為一個向量,即32*32的陣列轉化為1*1024的陣列,這個1*1024的陣列用機器學習的術語來說就是特徵向量。
<span style="font-size:14px;">def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect</span>第二步:訓練樣本中有10*10個圖片,可以合併成一個100*1024的矩陣,每一行對應一個圖片,也就是一個txt文件。
def handwritingClassTest(): hwLabels = [] trainingFileList = listdir('trainingDigits') print trainingFileList m = len(trainingFileList) trainingMat = zeros((m,1024)) for i in range(m): fileNameStr = trainingFileList[i] fileStr = fileNameStr.split('.')[0] classNumStr = int(fileStr.split('_')[0]) hwLabels.append(classNumStr) #print hwLabels #print fileNameStr trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr) #print trainingMat[i,:] #print len(trainingMat[i,:]) testFileList = listdir('testDigits') errorCount = 0.0 mTest = len(testFileList) for i in range(mTest): fileNameStr = testFileList[i] fileStr = fileNameStr.split('.')[0] classNumStr = int(fileStr.split('_')[0]) vectorUnderTest = img2vector('testDigits/%s' % fileNameStr) classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3) print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr) if (classifierResult != classNumStr): errorCount += 1.0 print "\nthe total number of errors is: %d" % errorCount print "\nthe total error rate is: %f" % (errorCount/float(mTest))
第三步:測試樣本中有10*5個圖片,同樣的,對於測試圖片,將其轉化為1*1024的向量,然後計算它與訓練樣本中各個圖片的“距離”(這裡兩個向量的距離採用歐式距離),然後對距離排序,選出較小的前k個,因為這k個樣本來自訓練集,是已知其代表的數字的,所以被測試圖片所代表的數字就可以確定為這k箇中出現次數最多的那個數字。
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
#tile(A,(m,n))
print dataSet
print "----------------"
print tile(inX, (dataSetSize,1))
print "----------------"
diffMat = tile(inX, (dataSetSize,1)) - dataSet
print diffMat
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]#-*-coding:utf-8-*-
from numpy import *
import operator
from os import listdir
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
#tile(A,(m,n))
print dataSet
print "----------------"
print tile(inX, (dataSetSize,1))
print "----------------"
diffMat = tile(inX, (dataSetSize,1)) - dataSet
print diffMat
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits')
print trainingFileList
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
#print hwLabels
#print fileNameStr
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
#print trainingMat[i,:]
#print len(trainingMat[i,:])
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))
handwritingClassTest()
執行結果:原始碼文章尾可下載
java版本
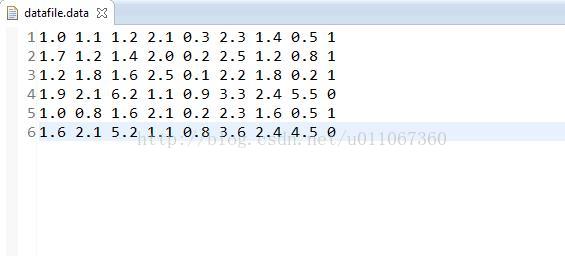
先看看訓練集和測試集:
訓練集:
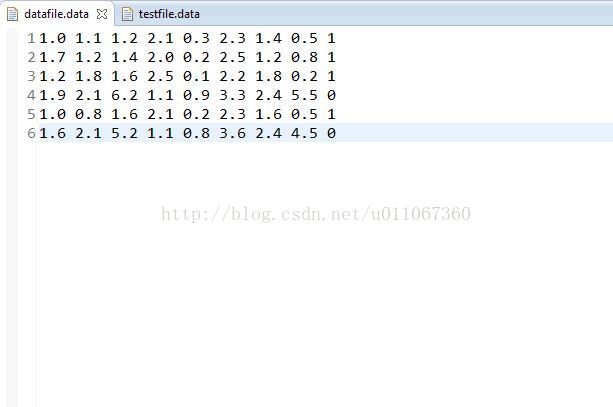
測試集:
訓練集最後一列代表分類(0或者1)
程式碼實現:
KNN演算法主體類:
package Marchinglearning.knn2;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.PriorityQueue;
/**
* KNN演算法主體類
*/
public class KNN {
/**
* 設定優先順序佇列的比較函式,距離越大,優先順序越高
*/
private Comparator<KNNNode> comparator = new Comparator<KNNNode>() {
public int compare(KNNNode o1, KNNNode o2) {
if (o1.getDistance() >= o2.getDistance()) {
return 1;
} else {
return 0;
}
}
};
/**
* 獲取K個不同的隨機數
* @param k 隨機數的個數
* @param max 隨機數最大的範圍
* @return 生成的隨機數陣列
*/
public List<Integer> getRandKNum(int k, int max) {
List<Integer> rand = new ArrayList<Integer>(k);
for (int i = 0; i < k; i++) {
int temp = (int) (Math.random() * max);
if (!rand.contains(temp)) {
rand.add(temp);
} else {
i--;
}
}
return rand;
}
/**
* 計算測試元組與訓練元組之前的距離
* @param d1 測試元組
* @param d2 訓練元組
* @return 距離值
*/
public double calDistance(List<Double> d1, List<Double> d2) {
System.out.println("d1:"+d1+",d2"+d2);
double distance = 0.00;
for (int i = 0; i < d1.size(); i++) {
distance += (d1.get(i) - d2.get(i)) * (d1.get(i) - d2.get(i));
}
return distance;
}
/**
* 執行KNN演算法,獲取測試元組的類別
* @param datas 訓練資料集
* @param testData 測試元組
* @param k 設定的K值
* @return 測試元組的類別
*/
public String knn(List<List<Double>> datas, List<Double> testData, int k) {
PriorityQueue<KNNNode> pq = new PriorityQueue<KNNNode>(k, comparator);
List<Integer> randNum = getRandKNum(k, datas.size());
System.out.println("randNum:"+randNum.toString());
for (int i = 0; i < k; i++) {
int index = randNum.get(i);
List<Double> currData = datas.get(index);
String c = currData.get(currData.size() - 1).toString();
System.out.println("currData:"+currData+",c:"+c+",testData"+testData);
//計算測試元組與訓練元組之前的距離
KNNNode node = new KNNNode(index, calDistance(testData, currData), c);
pq.add(node);
}
for (int i = 0; i < datas.size(); i++) {
List<Double> t = datas.get(i);
System.out.println("testData:"+testData);
System.out.println("t:"+t);
double distance = calDistance(testData, t);
System.out.println("distance:"+distance);
KNNNode top = pq.peek();
if (top.getDistance() > distance) {
pq.remove();
pq.add(new KNNNode(i, distance, t.get(t.size() - 1).toString()));
}
}
return getMostClass(pq);
}
/**
* 獲取所得到的k個最近鄰元組的多數類
* @param pq 儲存k個最近近鄰元組的優先順序佇列
* @return 多數類的名稱
*/
private String getMostClass(PriorityQueue<KNNNode> pq) {
Map<String, Integer> classCount = new HashMap<String, Integer>();
for (int i = 0; i < pq.size(); i++) {
KNNNode node = pq.remove();
String c = node.getC();
if (classCount.containsKey(c)) {
classCount.put(c, classCount.get(c) + 1);
} else {
classCount.put(c, 1);
}
}
int maxIndex = -1;
int maxCount = 0;
Object[] classes = classCount.keySet().toArray();
for (int i = 0; i < classes.length; i++) {
if (classCount.get(classes[i]) > maxCount) {
maxIndex = i;
maxCount = classCount.get(classes[i]);
}
}
return classes[maxIndex].toString();
}
}
KNN結點類,用來儲存最近鄰的k個元組相關的資訊
package Marchinglearning.knn2;
/**
* KNN結點類,用來儲存最近鄰的k個元組相關的資訊
*/
public class KNNNode {
private int index; // 元組標號
private double distance; // 與測試元組的距離
private String c; // 所屬類別
public KNNNode(int index, double distance, String c) {
super();
this.index = index;
this.distance = distance;
this.c = c;
}
public int getIndex() {
return index;
}
public void setIndex(int index) {
this.index = index;
}
public double getDistance() {
return distance;
}
public void setDistance(double distance) {
this.distance = distance;
}
public String getC() {
return c;
}
public void setC(String c) {
this.c = c;
}
}
KNN演算法測試類
package Marchinglearning.knn2;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.util.ArrayList;
import java.util.List;
/**
* KNN演算法測試類
*/
public class TestKNN {
/**
* 從資料檔案中讀取資料
* @param datas 儲存資料的集合物件
* @param path 資料檔案的路徑
*/
public void read(List<List<Double>> datas, String path){
try {
BufferedReader br = new BufferedReader(new FileReader(new File(path)));
String data = br.readLine();
List<Double> l = null;
while (data != null) {
String t[] = data.split(" ");
l = new ArrayList<Double>();
for (int i = 0; i < t.length; i++) {
l.add(Double.parseDouble(t[i]));
}
datas.add(l);
data = br.readLine();
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 程式執行入口
* @param args
*/
public static void main(String[] args) {
TestKNN t = new TestKNN();
String datafile = new File("").getAbsolutePath() + File.separator +"knndata2"+File.separator + "datafile.data";
String testfile = new File("").getAbsolutePath() + File.separator +"knndata2"+File.separator +"testfile.data";
System.out.println("datafile:"+datafile);
System.out.println("testfile:"+testfile);
try {
List<List<Double>> datas = new ArrayList<List<Double>>();
List<List<Double>> testDatas = new ArrayList<List<Double>>();
t.read(datas, datafile);
t.read(testDatas, testfile);
KNN knn = new KNN();
for (int i = 0; i < testDatas.size(); i++) {
List<Double> test = testDatas.get(i);
System.out.print("測試元組: ");
for (int j = 0; j < test.size(); j++) {
System.out.print(test.get(j) + " ");
}
System.out.print("類別為: ");
System.out.println(Math.round(Float.parseFloat((knn.knn(datas, test, 3)))));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
執行結果為:
資源下載: