
OCR開源庫Tesseract漢字識別訓練
阿新 • • 發佈:2019-02-07
先用中文做個示例:
1. 拿到一張chi.pingfang.exp0.jpg:

2. 將它轉化為tif:http://image.online-convert.com/convert-to-tiff
3. 拿到chi.pingfang.exp0.tif之後,開始訓練。
第一步,生成box檔案。
//由tif圖片生成box檔案
tesseract chi.pingfang.exp0.tif chi.pingfang.exp0 -l chi_sim batch.nochop makebox這樣就得到一個 “chi.pingfang.exp0.box” 檔案,它在tif圖片檔案上用方框標註了它識別出的漢字。
它的識別不能保證100%對,要手動糾錯,用的是 “JTessBoxEditor”。
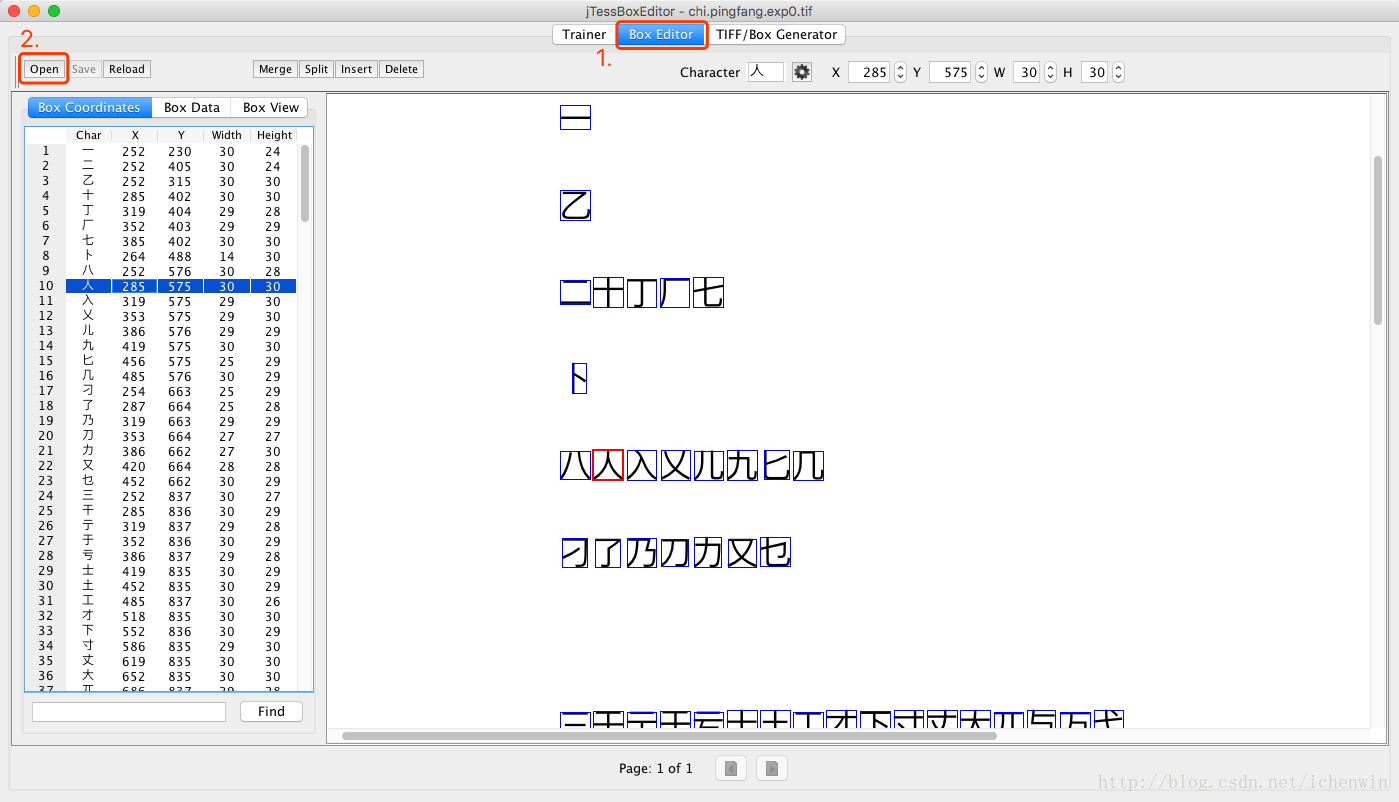
修正完之後
第二步,訓練,生成特徵檔案。
tesseract chi.pingfang.exp0.tif chi.pingfang.exp0 nobatch box.train
unicharset_extractor chi.pingfang.exp0.box第三步,聚集
新建一個 font_properties 檔案,內容是PingFang 0 0 0 0 0 (5個零表示:斜體, 粗體, 無襯線體, 襯線體, 哥特體)
上一步的特徵檔案生成後,需要將同樣文字的不同字型的特徵聚集到一起來產生該文字的一個原型 ,這一步需要執行三個命令:
shapeclustering -F font_properties -U unicharset chi.pingfang 這一步將會生成一個名為 shapetable 的檔案。
mftraining -F font_properties -U unicharset -O chi.unicharset chi.pingfang.exp0.tr這一步將會生成一個名為 inttemp 的檔案和一個名為 pffmtable 的檔案。
cntraining chi.pingfang.exp0.tr這一步將會生成一個名為 normproto 的檔案。
上述命令將生成名為 chi.pingfang.exp0.tr 的特徵檔案。對每一張生成的 TIF 影象,都要進行該步驟以生成特徵檔案。
第四步,打包
在上述步驟都完成後,將要打包入資原始檔的那些檔案加上一個統一的字首,該字首即是待生成的資原始檔的名稱,這裡假定我們要生成 chi.traineddata 這樣一個資原始檔,那麼我們的可能操作就是:
mv unicharset chi.unicharset
mv shapetable chi.shapetable
mv inttemp chi.inttemp
mv pffmtable chi.pffmtable
mv normproto chi.normproto
combine_tessdata chi至此,一個簡單的訓練過程結束。