
hdfs讀寫檔案核心流程詳解巧說
阿新 • • 發佈:2019-02-07
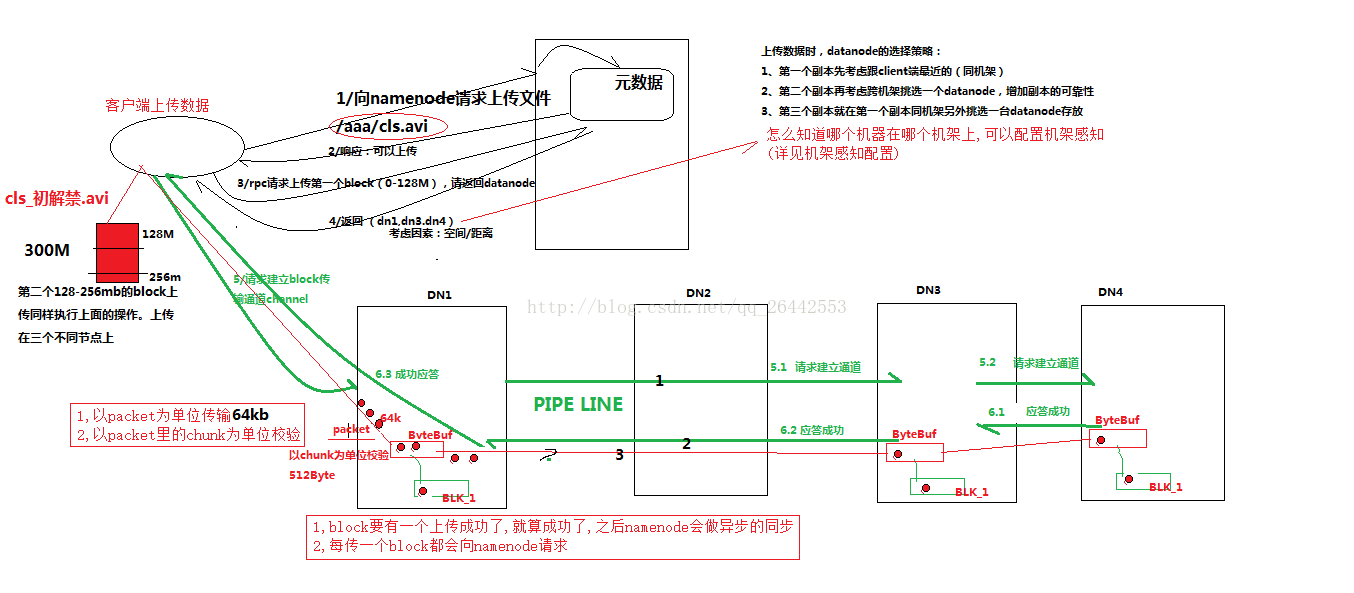
一.hdfs寫資料流程(面試重點)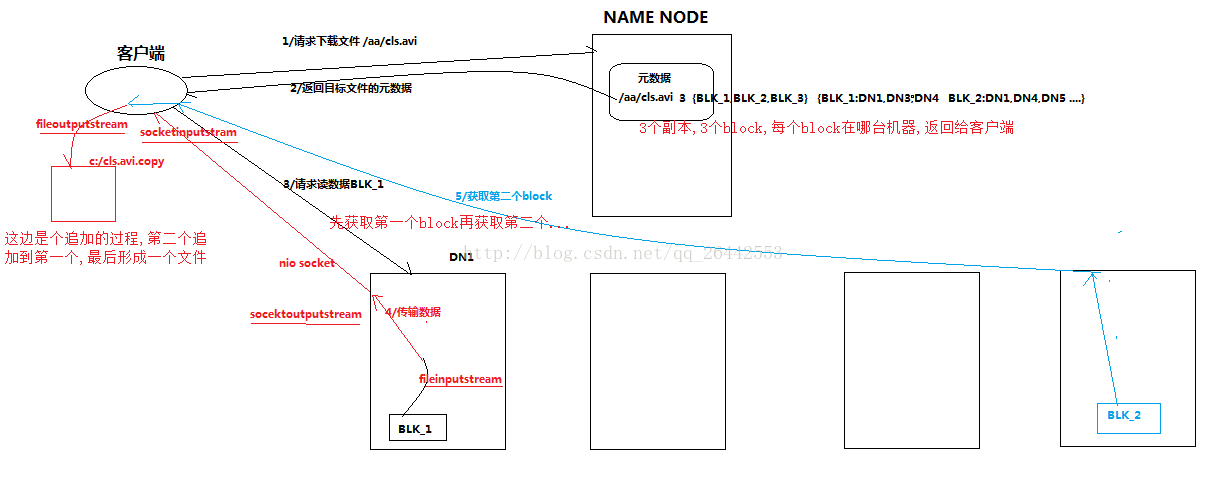 1)客戶端(fs)向namenode請求上傳檔案,namenode檢查目標檔案是否已存在,父目錄是否存在。
2)namenode返回是否可以上傳。
3)客戶端請求第一個 block上傳到哪幾個datanode伺服器上。
4)namenode返回3個datanode節點,分別為dn1、dn2、dn3。
5)客戶端請求dn1上傳資料,dn1收到請求會繼續呼叫dn2,然後dn2呼叫dn3,(本質上是一個RPC呼叫,建立pipeline)將這個通訊管道建立完成
6)dn1、dn2、dn3逐級應答客戶端
7)客戶端開始往dn1上傳第一個block(先從磁碟讀取資料放到一個本地記憶體快取),以packet為單位,dn1收到一個packet就會傳給dn2,dn2傳給dn3;dn1每傳一個packet會放入一個應答佇列等待應答
1)客戶端(fs)向namenode請求上傳檔案,namenode檢查目標檔案是否已存在,父目錄是否存在。
2)namenode返回是否可以上傳。
3)客戶端請求第一個 block上傳到哪幾個datanode伺服器上。
4)namenode返回3個datanode節點,分別為dn1、dn2、dn3。
5)客戶端請求dn1上傳資料,dn1收到請求會繼續呼叫dn2,然後dn2呼叫dn3,(本質上是一個RPC呼叫,建立pipeline)將這個通訊管道建立完成
6)dn1、dn2、dn3逐級應答客戶端
7)客戶端開始往dn1上傳第一個block(先從磁碟讀取資料放到一個本地記憶體快取),以packet為單位,dn1收到一個packet就會傳給dn2,dn2傳給dn3;dn1每傳一個packet會放入一個應答佇列等待應答 
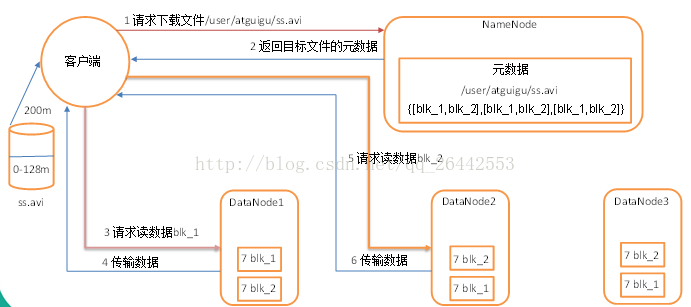
1)客戶端向namenode請求下載檔案,namenode通過查詢元資料,找到檔案塊所在的datanode地址。 2)挑選一臺datanode(就近原則,然後隨機)伺服器,請求讀取資料。 3)datanode開始傳輸資料給客戶端(從磁盤裡面讀取資料放入流,以packet為單位來做校驗)。 4)客戶端以packet為單位接收,先在本地快取,然後寫入目標檔案。 三:一致性模型 1)debug除錯如下程式碼
2)總結
寫入資料時,如果希望資料被其他client立即可見,呼叫如下方法
FsDataOutputStream. hflush (); //清理客戶端緩衝區資料,被其他client立即可見
1)客戶端(fs)向namenode請求上傳檔案,namenode檢查目標檔案是否已存在,父目錄是否存在。
2)namenode返回是否可以上傳。
3)客戶端請求第一個 block上傳到哪幾個datanode伺服器上。
4)namenode返回3個datanode節點,分別為dn1、dn2、dn3。
5)客戶端請求dn1上傳資料,dn1收到請求會繼續呼叫dn2,然後dn2呼叫dn3,(本質上是一個RPC呼叫,建立pipeline)將這個通訊管道建立完成
6)dn1、dn2、dn3逐級應答客戶端
7)客戶端開始往dn1上傳第一個block(先從磁碟讀取資料放到一個本地記憶體快取),以packet為單位,dn1收到一個packet就會傳給dn2,dn2傳給dn3;dn1每傳一個packet會放入一個應答佇列等待應答1)客戶端向namenode請求下載檔案,namenode通過查詢元資料,找到檔案塊所在的datanode地址。 2)挑選一臺datanode(就近原則,然後隨機)伺服器,請求讀取資料。 3)datanode開始傳輸資料給客戶端(從磁盤裡面讀取資料放入流,以packet為單位來做校驗)。 4)客戶端以packet為單位接收,先在本地快取,然後寫入目標檔案。 三:一致性模型 1)debug除錯如下程式碼
|
@Test
public void writeFile() throws Exception{
// 1建立配置資訊物件
Configuration configuration = new Configuration(); |