
XML之dom4j解析器
阿新 • • 發佈:2019-02-07
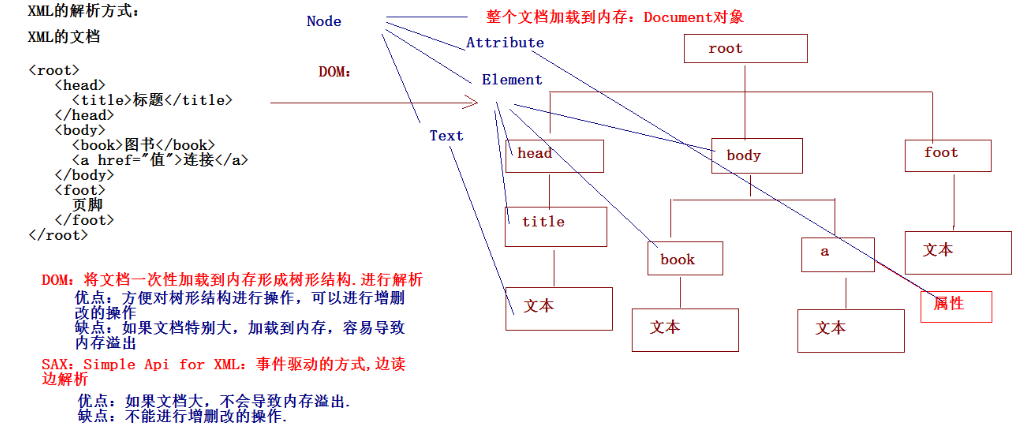
解析原理
常用API
1. SaxReader物件
a) read(...) 載入執行xml文件2. Document物件
a) getRootElement( ) 獲得根元素
3. Element物件
a) elements(...) 獲得指定名稱的所有子元素,可以不指定名稱
b) element(...) 獲得指定名稱第一個子元素,可以不指定名稱
c) getName() 獲得當前元素的元素名
d) attributeValue(...) 獲得指定屬性名的屬性值
e) elementText(...) 獲得指定名稱子元素的文字值
f) getText() 獲得當前元素的文字內容
解析程式碼
import java.util.List; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.io.SAXReader; import org.junit.Test; public class TestDom4j { @Test public void testReadWebXML() { try { // 1.獲取解析器 SAXReader saxReader = new SAXReader(); // 2.獲得document文件物件 Document doc = saxReader.read("src/cn/mark/xml/schema/web.xml"); // 3.獲取根元素 Element rootElement = doc.getRootElement(); // System.out.println(rootElement.getName());//獲取根元素的名稱 // System.out.println(rootElement.attributeValue("version"));//獲取根元素中的屬性值 // 4.獲取根元素下的子元素 List<Element> childElements = rootElement.elements(); // 5.遍歷子元素 for (Element element : childElements) { //6.判斷元素名稱為servlet的元素 if ("servlet".equals(element.getName())) { //7.獲取servlet-name元素 Element servletName = element.element("servlet-name"); //8.獲取servlet-class元素 Element servletClass = element.element("servlet-class"); System.out.println(servletName.getText()); System.out.println(servletClass.getText()); } } } catch (DocumentException e) { e.printStackTrace(); } } }