
SparseAutoEncoder 稀疏編碼詳解(Andrew ng課程系列)
先簡單敘述問題,原始碼詳細解析在下面
前言
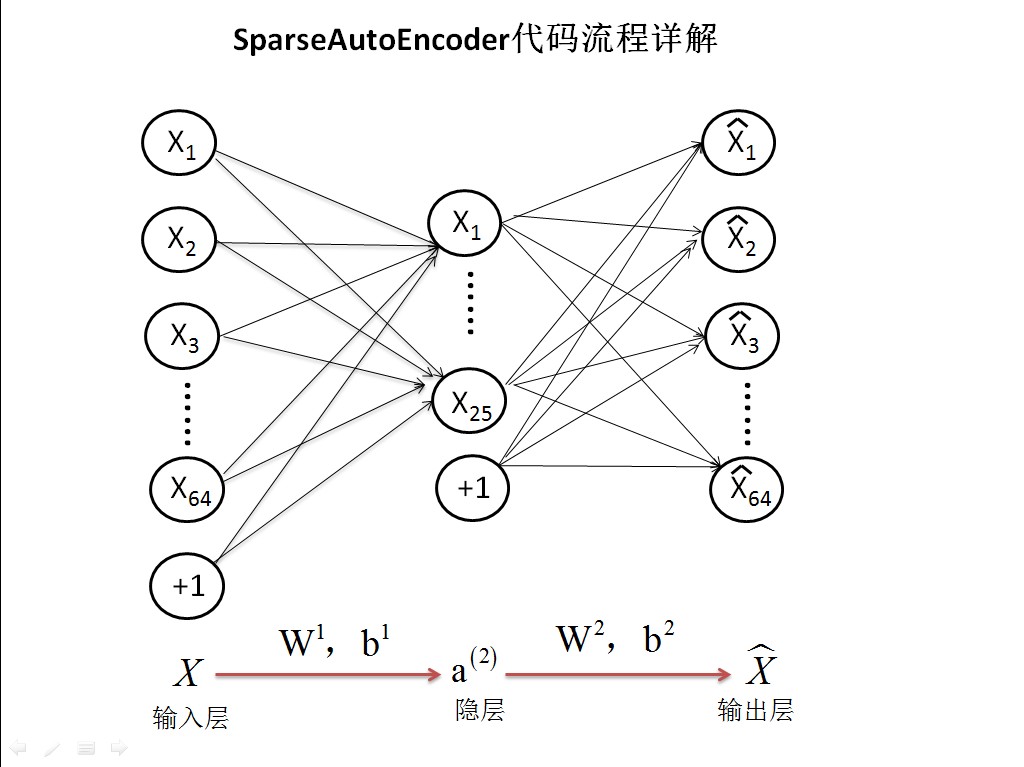
首先介紹sparse autoencoder的一個例項練習,參考Ng的網頁教程:Exercise:Sparse Autoencoder。這個例子所要實現的內容大概如下:從給定的很多張自然圖片中截取出大小為8*8的小patches圖片共10000張,現在需要用sparse autoencoder的方法訓練出一個隱含層網路所學習到的特徵。該網路共有3層,輸入層是64個節點,隱含層是25個節點,輸出層當然也是64個節點了。
實驗基礎:
其實實現該功能的主要步驟還是需要計算出網路的損失函式以及其偏導數,具體的公式可以參考前面的博文Deep learning:八(Sparse Autoencoder)
1. 計算出網路每個節點的輸入值(即程式中的z值)和輸出值(即程式中的a值,a是z的sigmoid函式值)。
2. 利用z值和a值計算出網路每個節點的誤差值(即程式中的delta值)。
3. 這樣可以利用上面計算出的每個節點的a,z,delta來表達出系統的損失函式以及損失函式的偏導數了,當然這些都是一些數學推導,其公式就是前面的博文Deep learning:八(Sparse Autoencoder)了。
其實步驟1是前向進行的,也就是說按照輸入層——》隱含層——》輸出層的方向進行計算。而步驟2是方向進行的(這也是該演算法叫做BP演算法的來源),即每個節點的誤差值是按照輸出層——》隱含層——》輸入層方向進行的。
一些malab函式:
bsxfun:
C=bsxfun(fun,A,B)表達的是兩個陣列A和B間元素的二值操作,fun是函式控制代碼或者m檔案,或者是內嵌的函式。在實際使用過程中fun有很多選擇比如說加,減等,前面需要使用符號’@’.一般情況下A和B需要尺寸大小相同,如果不相同的話,則只能有一個維度不同,同時A和B中在該維度處必須有一個的維度為1。比如說bsxfun(@minus, A, mean(A)),其中A和mean(A)的大小是不同的,這裡的意思需要先將mean(A)擴充到和A大小相同,然後用A的每個元素減去擴充後的mean(A)對應元素的值。
rand:
生成均勻分佈的偽隨機數。分佈在(0~1)之間
主要語法:rand(m,n)生成m行n列的均勻分佈的偽隨機數
rand(m,n,'double')生成指定精度的均勻分佈的偽隨機數,引數還可以是'single'
rand(RandStream,m,n)利用指定的RandStream(我理解為隨機種子)生成偽隨機數
randn:
生成標準正態分佈的偽隨機數(均值為0,方差為1)。主要語法:和上面一樣
randi:
生成均勻分佈的偽隨機整數
主要語法:randi(iMax)在閉區間(0,iMax)生成均勻分佈的偽隨機整數
randi(iMax,m,n)在閉區間(0,iMax)生成mXn型隨機矩陣
r = randi([iMin,iMax],m,n)在閉區間(iMin,iMax)生成mXn型隨機矩陣
exist:
測試引數是否存在,比如說exist('opt_normalize', 'var')表示檢測變數opt_normalize是否存在,其中的’var’表示變數的意思。
colormap:
設定當前常見的顏色值表。
floor:
floor(A):取不大於A的最大整數。
ceil:
ceil(A):取不小於A的最小整數。
imagesc:
imagesc和image類似,可以用於顯示影象。比如imagesc(array,'EraseMode','none',[-1 1]),這裡的意思是將array中的資料線性對映到[-1,1]之間,然後使用當前設定的顏色表進行顯示。此時的[-1,1]充滿了整個顏色表。背景擦除模式設定為node,表示不擦除背景。
repmat:
該函式是擴充套件一個矩陣並把原來矩陣中的資料複製進去。比如說B = repmat(A,m,n),就是建立一個矩陣B,B中複製了共m*n個A矩陣,因此B矩陣的大小為[size(A,1)*m size(A,2)*m]。
使用函式控制代碼的作用:
不使用函式控制代碼的情況下,對函式多次呼叫,每次都要為該函式進行全面的路徑搜尋,直接影響計算速度,藉助控制代碼可以完全避免這種時間損耗。也就是直接指定了函式的指標。函式控制代碼就像一個函式的名字,有點類似於C++程式中的引用。
以上部分摘自部落格:
程式過程解析
step0:引數初始化
visibleSize = 8*8; % 輸入特徵數,也是每個小圖片的維數
hiddenSize = 25; % 隱層節點數
sparsityParam = 0.01; % 期望稀疏值
lambda = 0.0001; % 權值懲罰引數
beta = 3;
step1:呼叫sampleIMAGES函式,載入並處理資料
1)sampleIMAGE函式關鍵部分解析
for imageNum = 1:10%在每張圖片中隨機選取1000個patch,共10000個patch
[rowNum colNum] = size(IMAGES(:,:,imageNum));
for patchNum = 1:1000%實現每張圖片選取1000個patch
xPos = randi([1,rowNum-patchsize+1]);%randi用於生產隨機整數矩陣randi([min max],m,n)
yPos = randi([1, colNum-patchsize+1]);
patches(:,(imageNum-1)*1000+patchNum) = reshape(IMAGES(xPos:xPos+7,yPos:yPos+7,...
imageNum),64,1);%reshap函式,將8*8的方陣,變形為64*1的列向量
end
end
處理資料
patches = normalizeData(patches);normalizeData()函式先使用標準差使資料範圍變為-1到1,之後再變換到[0.1,0.9],以便和sigmoid函式輸出值匹配
2)initializeParameters函式
通過輸入層和隱層節點數,初始化權值矩陣和偏置項矩陣。
初始化權值矩陣是,是通過在[-r, r]區間內隨機初始化矩陣r = sqrt(6) / sqrt(hiddenSize+visibleSize+1)=0.2582;(這個我不不清楚為啥,只知道Andrew教程中權值初始值要隨機,且隨機數值不應過大)
theta = [W1(:) ; W2(:) ; b1(:) ; b2(:)];把矩陣向量化,通過向量來傳遞引數;個人猜測應該是通過向量傳參效率高
STEP 2: 實現 sparseAutoencoderCost,稀疏損失函式
1)通過反轉向量,把向量還原為權值矩陣
2)計算損失函式和梯度
由於畫圖和矩陣的原因,原稿使用ppt來製作的,現在就只能通過貼圖的方式展現了,有需要ppt的可以私信我
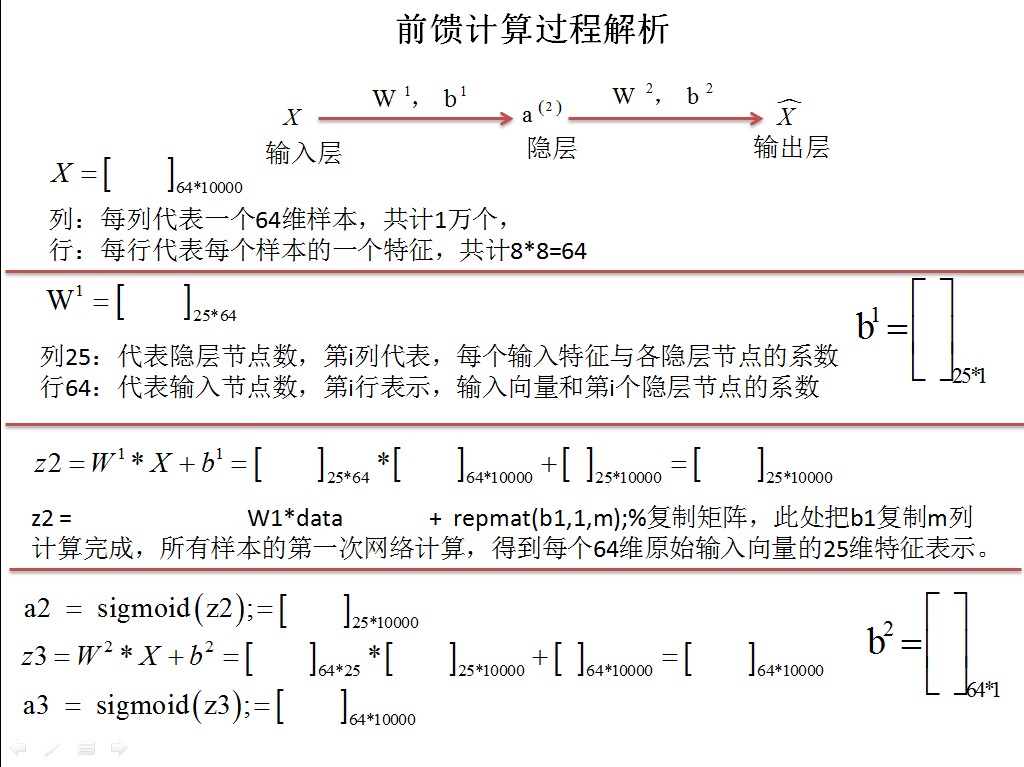




最後把矩陣權值向量化,當做引數傳遞出來
grad = [W1grad(:) ; W2grad(:) ; b1grad(:) ; b2grad(:)];
STEP 3: 通過l-bfgs演算法優化
STEP4:視覺化學習到的權值矩陣W1.