
fastdfs 原理與過程
前言:
(1)每次上傳檔案後都會返回一個地址,使用者需要自己儲存此地址。
(2)為了支援大容量,儲存節點(伺服器)採用了分卷(或分組)的組織方式。儲存系統由一個或多個卷組成,卷與卷之間的檔案是相互獨立的,所有卷的檔案容量累加就是整個儲存系統中的檔案容量。一個卷可以由一臺或多臺儲存伺服器組成,一個卷下的儲存伺服器中的檔案都是相同的,卷中的多臺儲存伺服器起到了冗餘備份和負載均衡的作用。
網摘1
FastDFS是一個開源的輕量級分散式檔案系統,由跟蹤伺服器(tracker server)、儲存伺服器(storage server)和客戶端(client)三個部分組成,主要解決了海量資料儲存問題,特別適合以中小檔案(建議範圍:4KB < file_size <500MB)為載體的線上服務。

Storage server
Storage server(後簡稱storage)以組(卷,group或volume)為單位組織,一個group內包含多臺storage機器,資料互為備份,儲存空間以group內容量最小的storage為準,所以建議group內的多個storage儘量配置相同,以免造成儲存空間的浪費。
以group為單位組織儲存能方便的進行應用隔離、負載均衡、副本數定製(group內storage server數量即為該group的副本數),比如將不同應用資料存到不同的group就能隔離應用資料,同時還可根據應用的訪問特性來將應用分配到不同的group來做負載均衡;缺點是group的容量受單機儲存容量的限制,同時當group內有機器壞掉時,資料恢復只能依賴group內地其他機器,使得恢復時間會很長。
group內每個storage的儲存依賴於本地檔案系統,storage可配置多個數據儲存目錄,比如有10塊磁碟,分別掛載在/data/disk1-/data/disk10,則可將這10個目錄都配置為storage的資料儲存目錄。
storage接受到寫檔案請求時,會根據配置好的規則(後面會介紹),選擇其中一個儲存目錄來儲存檔案。為了避免單個目錄下的檔案數太多,在storage第一次啟動時,會在每個資料儲存目錄裡建立2級子目錄,每級256個,總共65536個檔案,新寫的檔案會以hash的方式被路由到其中某個子目錄下,然後將檔案資料直接作為一個本地檔案儲存到該目錄中。
Tracker server
Tracker是FastDFS的協調者,負責管理所有的storage server和group,每個storage在啟動後會連線Tracker,告知自己所屬的group等資訊,並保持週期性的心跳,tracker根據storage的心跳資訊,建立group==>[storage server list]的對映表。
Tracker需要管理的元資訊很少,會全部儲存在記憶體中;另外tracker上的元資訊都是由storage彙報的資訊生成的,本身不需要持久化任何資料,這樣使得tracker非常容易擴充套件,直接增加tracker機器即可擴充套件為tracker cluster來服務,cluster裡每個tracker之間是完全對等的,所有的tracker都接受stroage的心跳資訊,生成元資料資訊來提供讀寫服務。
Upload file
FastDFS向使用者提供基本檔案訪問介面,比如upload、download、append、delete等,以客戶端庫的方式提供給使用者使用。

選擇tracker server
當叢集中不止一個tracker server時,由於tracker之間是完全對等的關係,客戶端在upload檔案時可以任意選擇一個trakcer。
選擇儲存的group
當tracker接收到upload file的請求時,會為該檔案分配一個可以儲存該檔案的group,支援如下選擇group的規則:1.Round robin,所有的group間輪詢2.Specifiedgroup,指定某一個確定的group3.Load balance,剩餘儲存空間多多group優先
選擇storage server
當選定group後,tracker會在group內選擇一個storage server給客戶端,支援如下選擇storage的規則:1.Round robin,在group內的所有storage間輪詢2.First server ordered by ip,按ip排序3.First server ordered by priority,按優先順序排序(優先順序在storage上配置)
選擇storage path
當分配好storage server後,客戶端將向storage傳送寫檔案請求,storage將會為檔案分配一個數據儲存目錄,支援如下規則:1.Round robin,多個儲存目錄間輪詢2.剩餘儲存空間最多的優先
生成Fileid
選定儲存目錄之後,storage會為檔案生一個Fileid,由storage server ip、檔案建立時間、檔案大小、檔案crc32和一個隨機數拼接而成,然後將這個二進位制串進行base64編碼,轉換為可列印的字串。
選擇兩級目錄
當選定儲存目錄之後,storage會為檔案分配一個fileid,每個儲存目錄下有兩級256*256的子目錄,storage會按檔案fileid進行兩次hash(猜測),路由到其中一個子目錄,然後將檔案以fileid為檔名儲存到該子目錄下。
生成檔名
當檔案儲存到某個子目錄後,即認為該檔案儲存成功,接下來會為該檔案生成一個檔名,檔名由group、儲存目錄、兩級子目錄、fileid、檔案字尾名(由客戶端指定,主要用於區分檔案型別)拼接而成。

檔案同步
寫檔案時,客戶端將檔案寫至group內一個storage server即認為寫檔案成功,storage server寫完檔案後,會由後臺執行緒將檔案同步至同group內其他的storage server。
每個storage寫檔案後,同時會寫一份binlog,binlog裡不包含檔案資料,只包含檔名等元資訊,這份binlog用於後臺同步,storage會記錄向group內其他storage同步的進度,以便重啟後能接上次的進度繼續同步;進度以時間戳的方式進行記錄,所以最好能保證叢集內所有server的時鐘保持同步。
storage的同步進度會作為元資料的一部分彙報到tracker上,tracke在選擇讀storage的時候會以同步進度作為參考。
比如一個group內有A、B、C三個storage server,A向C同步到進度為T1 (T1以前寫的檔案都已經同步到B上了),B向C同步到時間戳為T2(T2 > T1),tracker接收到這些同步進度資訊時,就會進行整理,將最小的那個做為C的同步時間戳,本例中T1即為C的同步時間戳為T1(即所有T1以前寫的資料都已經同步到C上了);同理,根據上述規則,tracker會為A、B生成一個同步時間戳。
Download file
客戶端upload file成功後,會拿到一個storage生成的檔名,接下來客戶端根據這個檔名即可訪問到該檔案。

跟upload file一樣,在download file時客戶端可以選擇任意tracker server。
tracker傳送download請求給某個tracker,必須帶上檔名資訊,tracke從檔名中解析出檔案的group、大小、建立時間等資訊,然後為該請求選擇一個storage用來服務讀請求。由於group內的檔案同步時在後臺非同步進行的,所以有可能出現在讀到時候,檔案還沒有同步到某些storage server上,為了儘量避免訪問到這樣的storage,tracker按照如下規則選擇group內可讀的storage。
1.該檔案上傳到的源頭storage -源頭storage只要存活著,肯定包含這個檔案,源頭的地址被編碼在檔名中。2.檔案建立時間戳==storage被同步到的時間戳且(當前時間-檔案建立時間戳)>檔案同步最大時間(如5分鐘)-檔案建立後,認為經過最大同步時間後,肯定已經同步到其他storage了。3.檔案建立時間戳< storage被同步到的時間戳。-同步時間戳之前的檔案確定已經同步了4.(當前時間-檔案建立時間戳)>同步延遲閥值(如一天)。-經過同步延遲閾值時間,認為檔案肯定已經同步了。
小檔案合併儲存
將小檔案合併儲存主要解決如下幾個問題:
1.本地檔案系統inode數量有限,從而儲存的小檔案數量也就受到限制。2.多級目錄+目錄裡很多檔案,導致訪問檔案的開銷很大(可能導致很多次IO)3.按小檔案儲存,備份與恢復的效率低
FastDFS在V3.0版本里引入小檔案合併儲存的機制,可將多個小檔案儲存到一個大的檔案(trunk file),為了支援這個機制,FastDFS生成的檔案fileid需要額外增加16個位元組
1. trunk file id 2.檔案在trunk file內部的offset 3.檔案佔用的儲存空間大小(位元組對齊及刪除空間複用,檔案佔用儲存空間>=檔案大小)
每個trunk file由一個id唯一標識,trunk file由group內的trunk server負責建立(trunk server是tracker選出來的),並同步到group內其他的storage,檔案儲存合併儲存到trunk file後,根據其offset就能從trunk file讀取到檔案。
檔案在trunk file內的offset編碼到檔名,決定了其在trunk file內的位置是不能更改的,也就不能通過compact的方式回收trunk file內刪除檔案的空間。但當trunk file內有檔案刪除時,其刪除的空間是可以被複用的,比如一個100KB的檔案被刪除,接下來儲存一個99KB的檔案就可以直接複用這片刪除的儲存空間。
HTTP訪問支援
FastDFS的tracker和storage都內建了http協議的支援,客戶端可以通過http協議來下載檔案,tracker在接收到請求時,通過http的redirect機制將請求重定向至檔案所在的storage上;除了內建的http協議外,FastDFS還提供了通過apache或nginx擴充套件模組下載檔案的支援。

其他特性
FastDFS提供了設定/獲取檔案擴充套件屬性的介面(setmeta/getmeta),擴充套件屬性以key-value對的方式儲存在storage上的同名檔案(擁有特殊的字首或字尾),比如/group/M00/00/01/some_file為原始檔案,則該檔案的擴充套件屬性儲存在/group/M00/00/01/.some_file.meta檔案(真實情況不一定是這樣,但機制類似),這樣根據檔名就能定位到儲存擴充套件屬性的檔案。
以上兩個介面作者不建議使用,額外的meta檔案會進一步“放大”海量小檔案儲存問題,同時由於meta非常小,其儲存空間利用率也不高,比如100bytes的meta檔案也需要佔用4K(block_size)的儲存空間。
FastDFS還提供appender file的支援,通過upload_appender_file介面儲存,appender file允許在建立後,對該檔案進行append操作。實際上,appender file與普通檔案的儲存方式是相同的,不同的是,appender file不能被合併儲存到trunk file。
問題討論
從FastDFS的整個設計看,基本上都已簡單為原則。比如以機器為單位備份資料,簡化了tracker的管理工作;storage直接藉助本地檔案系統原樣儲存檔案,簡化了storage的管理工作;檔案寫單份到storage即為成功、然後後臺同步,簡化了寫檔案流程。但簡單的方案能解決的問題通常也有限,FastDFS目前尚存在如下問題(歡迎探討)。
資料安全性
- 寫一份即成功:從源storage寫完檔案至同步到組內其他storage的時間視窗內,一旦源storage出現故障,就可能導致使用者資料丟失,而資料的丟失對儲存系統來說通常是不可接受的。
- 缺乏自動化恢復機制:當storage的某塊磁碟故障時,只能換存磁碟,然後手動恢復資料;由於按機器備份,似乎也不可能有自動化恢復機制,除非有預先準備好的熱備磁碟,缺乏自動化恢復機制會增加系統運維工作。
- 資料恢復效率低:恢復資料時,只能從group內其他的storage讀取,同時由於小檔案的訪問效率本身較低,按檔案恢復的效率也會很低,低的恢復效率也就意味著資料處於不安全狀態的時間更長。
- 缺乏多機房容災支援:目前要做多機房容災,只能額外做工具來將資料同步到備份的叢集,無自動化機制。
儲存空間利用率
- 單機儲存的檔案數受限於inode數量
- 每個檔案對應一個storage本地檔案系統的檔案,平均每個檔案會存在block_size/2的儲存空間浪費。
- 檔案合併儲存能有效解決上述兩個問題,但由於合併儲存沒有空間回收機制,刪除檔案的空間不保證一定能複用,也存在空間浪費的問題
負載均衡
- group機制本身可用來做負載均衡,但這只是一種靜態的負載均衡機制,需要預先知道應用的訪問特性;同時group機制也導致不可能在group之間遷移資料來做動態負載均衡。
網摘2
FastDFS 介紹
FastDFS 是一個 C 語言實現的開源輕量級分散式檔案系統,作者餘慶(happyfish100),支援 Linux、FreeBSD、AID 等 Unix 系統,解決了大資料儲存和讀寫負載均衡等問題,適合儲存 4KB~500MB 之間的小檔案,如圖片網站、短視訊網站、文件、app 下載站等,UC、京東、支付寶、迅雷、酷狗等都有使用,其中 UC 基於 FastDFS 向用戶提供網盤、廣告和應用下載的業務的儲存服務 FastDFS 與 MogileFS、HDFS、TFS 等都不是系統級的分散式檔案系統,而是應用級的分散式檔案儲存服務。FastDFS 架構
FastDFS服務有三個角色:跟蹤伺服器(tracker server)、儲存伺服器(storage server)和客戶端(client)tracker server: 跟蹤伺服器,主要做排程工作,起到均衡的作用;負責管理所有的 storage server 和 group,每個 storage 在啟動後會連線 Tracker,告知自己所屬 group 等資訊,並保持週期性心跳, Tracker根據storage心跳資訊,建立group—>[storage server list]的對映表;tracker管理的元資料很少,會直接存放在記憶體;tracker 上的元資訊都是由 storage 彙報的資訊生成的,本身不需要持久化任何資料,tracker 之間是對等關係,因此擴充套件 tracker 服務非常容易,之間增加 tracker伺服器即可,所有tracker都接受stroage心跳資訊,生成元資料資訊來提供讀寫服務(與 其他 Master-Slave 架構的優勢是沒有單點,tracker 也不會成為瓶頸,最終資料是和一個可用的 Storage Server進行傳輸的)
 storage server:儲存伺服器,主要提供容量和備份服務;以 group 為單位,每個 group 內可以包含多臺storage server,資料互為備份,儲存容量空間以group內容量最小的storage為準;建 議group內的storage server配置相同;以group為單位組織儲存能夠方便的進行應用隔離、負載均衡和副本數定製;缺點是 group 的容量受單機儲存容量的限制,同時 group 內機器壞掉,資料 恢復只能依賴 group 內其他機器重新同步(壞盤替換,重新掛載重啟 fdfs_storaged 即可)
多個group之間的儲存方式有3種策略:round robin(輪詢)、load balance(選擇最大剩餘空 間的組上傳檔案)、specify group(指定group上傳)
group 中 storage 儲存依賴本地檔案系統,storage 可配置多個數據儲存目錄,磁碟不做 raid, 直接分別掛載到多個目錄,將這些目錄配置為 storage 的資料目錄即可
storage 接受寫請求時,會根據配置好的規則,選擇其中一個儲存目錄來儲存檔案;為避免單 個目錄下的檔案過多,storage 第一次啟時,會在每個資料儲存目錄裡建立 2 級子目錄,每級 256 個,總共 65536 個,新寫的檔案會以 hash 的方式被路由到其中某個子目錄下,然後將檔案資料直 接作為一個本地檔案儲存到該目錄中

總結:1.高可靠性:無單點故障 2.高吞吐性:只要Group足夠多,資料流量是足夠分散的
FastDFS 工作流程
上傳
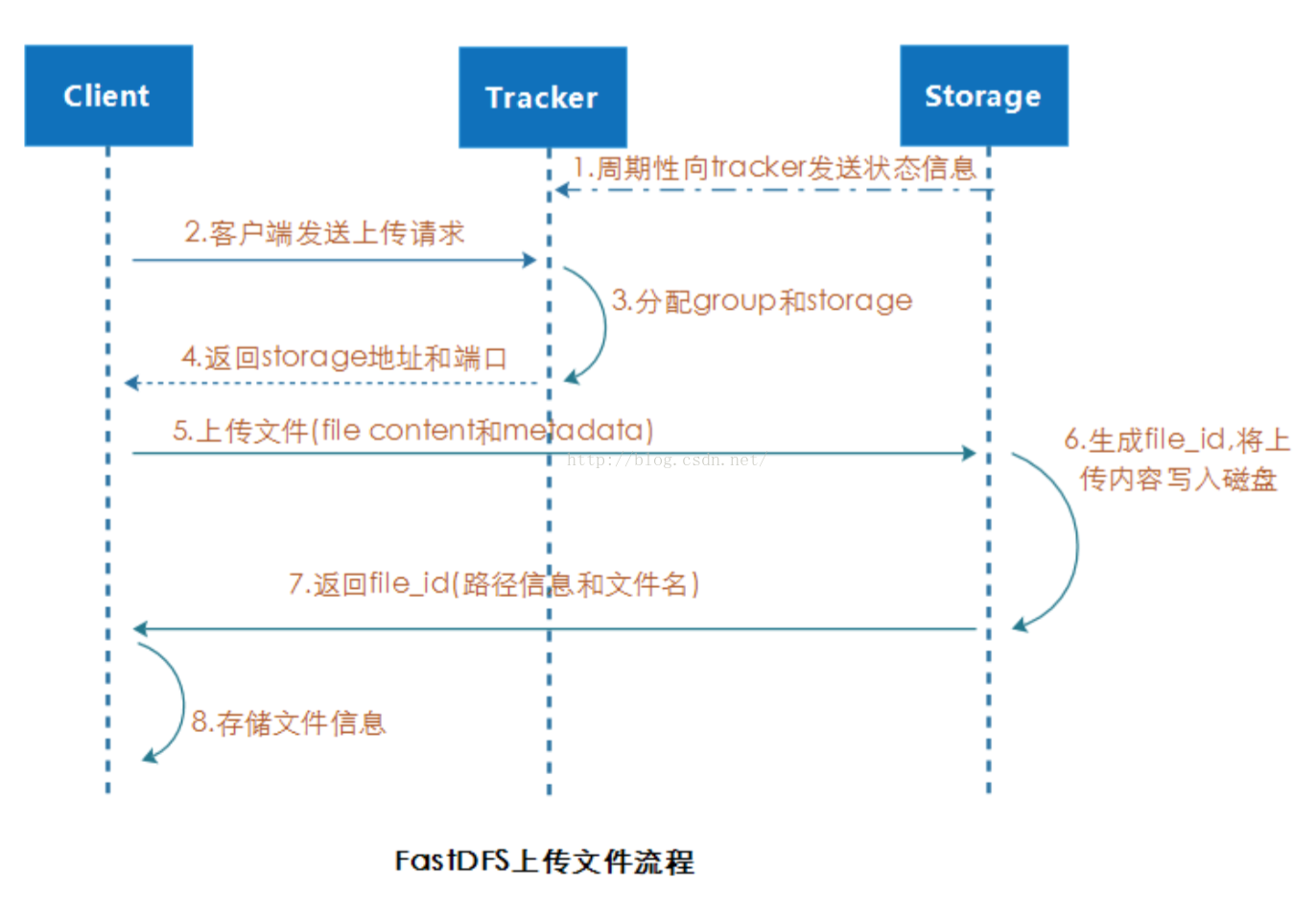
FastDFS 提供基本的檔案訪問介面,如 upload、download、append、delete 等
選擇tracker server
叢集中 tracker 之間是對等關係,客戶端在上傳檔案時可用任意選擇一個 tracker
選擇儲存 group
當tracker接收到upload file的請求時,會為該檔案分配一個可以儲存檔案的group,目前支援選擇 group 的規則為:
1. Round robin,所有 group 輪詢使用
2. Specified group,指定某個確定的 group
3. Load balance,剩餘儲存空間較多的 group 優先
選擇storage server
當選定group後,tracker會在group內選擇一個storage server給客戶端,目前支援選擇server 的規則為:
1. Round robin,所有 server 輪詢使用(預設)
2. 根據IP地址進行排序選擇第一個伺服器(IP地址最小者)
3. 根據優先順序進行排序(上傳優先順序由storage server來設定,引數為upload_priority)
選擇storage path(磁碟或者掛載點)
當分配好storage server後,客戶端將向storage傳送寫檔案請求,storage會將檔案分配一個數據儲存目錄,目前支援選擇儲存路徑的規則為:
1. round robin,輪詢(預設)
2. load balance,選擇使用剩餘空間最大的儲存路徑
選擇下載伺服器
目前支援的規則為:
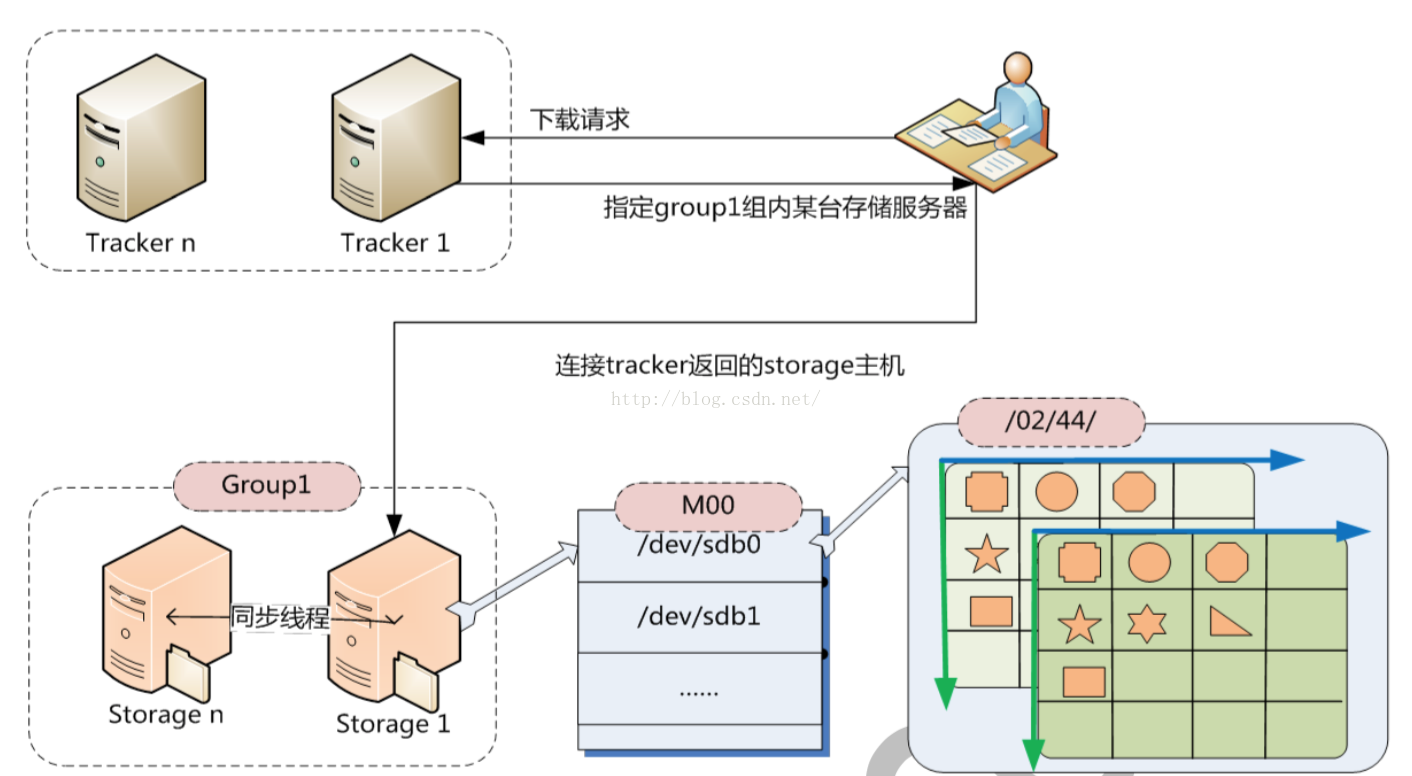
1. 輪詢方式,可以下載當前檔案的任一storage server 2. 從源storage server下載 生成 file_id 選擇儲存目錄後,storage 會生成一個 file_id,採用 Base64 編碼,包含欄位包括:storage server ip、檔案建立時間、檔案大小、檔案 CRC32 校驗碼和隨機數;每個儲存目錄下有兩個 256*256 個子目錄,storage 會按檔案 file_id 進行兩次 hash,路由到其中一個子目錄,,然後將檔案以 file_id 為檔名儲存到該子目錄下,最後生成檔案路徑:group 名稱、虛擬磁碟路徑、資料兩級目錄、file_id
 其中,
組名:檔案上傳後所在的儲存組的名稱,在檔案上傳成功後由儲存伺服器返回,需要客戶端自行儲存
虛擬磁碟路徑:儲存伺服器配置的虛擬路徑,與磁碟選項 store_path*引數對應
資料兩級目錄:儲存伺服器在每個虛擬磁碟路徑下建立的兩級目錄,用於儲存資料檔案
其中,
組名:檔案上傳後所在的儲存組的名稱,在檔案上傳成功後由儲存伺服器返回,需要客戶端自行儲存
虛擬磁碟路徑:儲存伺服器配置的虛擬路徑,與磁碟選項 store_path*引數對應
資料兩級目錄:儲存伺服器在每個虛擬磁碟路徑下建立的兩級目錄,用於儲存資料檔案
同步機制
1. 新增tracker伺服器資料同步問題由於 storage server 上配置了所有的 tracker server. storage server 和 trackerserver 之間的通訊是由 storage server 主動發起的,storage server 為每個 tracker server 啟動一個執行緒進行通訊;在通訊過程中,若發現該 tracker server 返回的本組 storage server列表比本機記錄少,就會將該tracker server上沒有的storage server 同步給該 tracker,這樣的機制使得 tracker 之間是對等關係,資料保持一致
2. 新增storage伺服器資料同步問題
若新增storage server或者其狀態發生變化,tracker server都會將storage server列表同步給該組內所有 storage server;以新增 storage server 為例,因為新加入的 storage server 會主動連線 tracker server,tracker server 發現有新的 storage server 加入,就會將該組內所有的 storage server 返回給新加入的 storage server,並重新將該組的storage server列表返回給該組內的其他storage server;
3. 組內storage資料同步問題
組內storage server之間是對等的,檔案上傳、刪除等操作可以在組內任意一臺storageserver 上進行。檔案同步只能在同組內的 storage server 之間進行,採用 push 方式, 即源伺服器同步到目標伺服器
A. 只在同組內的storage server之間進行同步
B. 源資料才需要同步,備份資料不再同步
C. 特例:新增storage server時,由其中一臺將已有所有資料(包括源資料和備份資料)同步到新增伺服器
storage server的7種狀態:
通過命令 fdfs_monitor /etc/fdfs/client.conf 可以檢視 ip_addr 選項顯示 storage server 當前狀態
INIT : 初始化,尚未得到同步已有資料的源伺服器 WAIT_SYNC : 等待同步,已得到同步已有資料的源伺服器 SYNCING : 同步中
DELETED : 已刪除,該伺服器從本組中摘除
OFFLINE :離線
ONLINE : 線上,尚不能提供服務
ACTIVE : 線上,可以提供服務
組內增加storage serverA狀態變化過程:
1. storage server A 主動連線 tracker server,此時 tracker server 將 storageserverA 狀態設定為 INIT
2. storage server A 向 tracker server 詢問追加同步的源伺服器和追加同步截止時間點(當前時間),若組內只有storage server A或者上傳檔案數為0,則告訴新機器不需要資料同步,storage server A 狀態設定為 ONLINE ;若組內沒有 active 狀態機器,就返回錯誤給新機器,新機器睡眠嘗試;否則 tracker 將其狀態設定為 WAIT_SYNC
3. 假如分配了 storage server B 為同步源伺服器和截至時間點,那麼 storage server B會將截至時間點之前的所有資料同步給storage server A,並請求tracker設定 storage server A 狀態為SYNCING;到了截至時間點後,storage server B向storage server A 的同步將由追加同步切換為正常 binlog 增量同步,當取不到更多的 binlog 時,請求tracker將storage server A設定為OFFLINE狀態,此時源同步完成
4. storage server B 向 storage server A 同步完所有資料,暫時沒有資料要同步時, storage server B請求tracker server將storage server A的狀態設定為ONLINE
5. 當 storage server A 向 tracker server 發起心跳時,tracker sercer 將其狀態更改為 ACTIVE,之後就是增量同步(binlog)
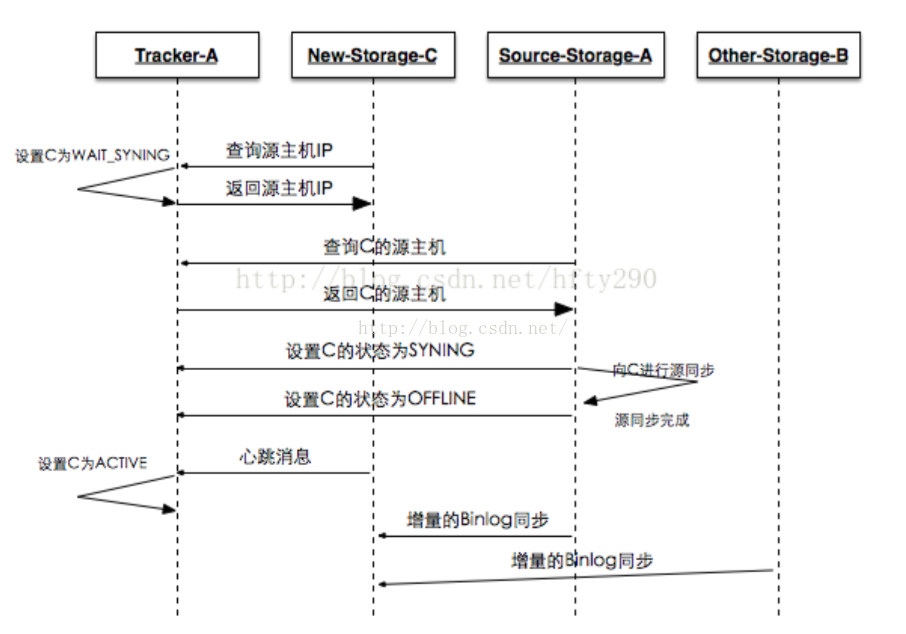
註釋: 1.整個源同步過程是源機器啟動一個同步執行緒,將資料 push 到新機器,最大達到一個磁碟的 IO,不能併發
2.由於源同步截止條件是取不到 binlog,系統繁忙,不斷有新資料寫入的情況,將會導致一直無法完成源同步過程
下載

client 傳送下載請求給某個 tracker,必須帶上檔名資訊,tracker 從檔名中解析出檔案的 group、大小、建立時間等資訊,然後為該請求選擇一個 storage 用於讀請求;由於 group 內的檔案同步在後臺是非同步進行的,可能出現檔案沒有同步到其他storage server上或者延遲的問題, 後面我們在使用 nginx_fastdfs_module 模組可以很好解決這一問題
檔案合併原理
小檔案合併儲存主要解決的問題:1. 本地檔案系統inode數量有限,儲存小檔案的數量受到限制
2. 多級目錄+目錄裡很多檔案,導致訪問檔案的開銷很大(可能導致很多次IO)
3. 按小檔案儲存,備份和恢復效率低 FastDFS 提供合併儲存功能,預設建立的大檔案為 64MB,然後在該大檔案中儲存很多小檔案; 大檔案中容納一個小檔案的空間稱作一個 Slot,規定 Slot 最小值為 256 位元組,最大為 16MB,即小於 256 位元組的檔案也要佔用 256 位元組,超過 16MB 的檔案獨立儲存;
為了支援檔案合併機制,FastDFS生成的檔案file_id需要額外增加16個位元組;每個trunk file 由一個id唯一標識,trunk file由group內的trunk server負責建立(trunk server是tracker 選出來的),並同步到group內其他的storage,檔案儲存合併儲存到trunk file後,根據其檔案偏移量就能從trunk file中讀取檔案