
JDK7和JDK8中HashMap的資料結構以及執行緒不安全和無序
JDK7中HashMap實現
jdk7中HashMap的資料結構是陣列+連結串列來實現的,底層維護著一個數組,每個陣列項是一個Entry;
transient Entry<K,V>[] table;static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;陣列中的Entry的位置是通過key的HashCode進行計算的:
final int hash(Object k) { int h = 0; h ^= k.hashCode(); h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }
之後通過IndexFor進行計算出來:
static int indexFor(int h, int length) {
return h & (length-1);
}其實就是key的hash值對length取模;如果兩個key的hash值一樣,那麼就產生衝突,或者說碰撞;HashMap解決碰撞的方法是通過連結串列。將新的值存放在entry[i]陣列中,原來的值作為entry[i]的next;所以新插入的值放在連結串列的頭節點中,舊值存放在連結串列的尾部;
當size大於capacity*裝載因子的時候就發生擴容;
void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); }
每次擴容,容量變為原來的2倍;
JDK8中的HashMap實現
在jdk7中,如果上百個元素存在一個連結串列上,那麼如果要查詢其中的一個元素的時候,查詢時間為o(n),效能比較低的;在Jdk8中解決了這個問題,通過引入紅黑樹,在最差的情況下,時間複雜度為o(logN);
JDK8中HashMap的實現為陣列+連結串列/紅黑樹;預設當連結串列的長度大於8之後,資料結構就變成紅黑樹;如圖所示
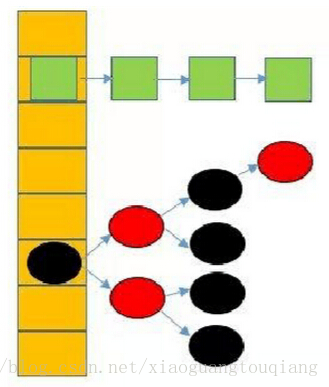
jdk8中的定義如下
transient Node<K,V>[] table;節點名字不再是entry,而是node,就是因為和紅黑樹的實現TreeNode關聯;put方法如下所示
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; //如果當前map中無資料,執行resize方法。並且返回n if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; //如果要插入的鍵值對要存放的這個位置剛好沒有元素,那麼把他封裝成Node物件,放在這個位置上就完事了 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); //否則的話,說明這上面有元素 else { Node<K,V> e; K k; //如果這個元素的key與要插入的一樣,那麼就替換一下,也完事。 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; //1.如果當前節點是TreeNode型別的資料,執行putTreeVal方法 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { //還是遍歷這條鏈子上的資料,跟jdk7沒什麼區別 for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); //2.完成了操作後多做了一件事情,判斷,並且可能執行treeifyBin方法 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) //true || -- e.value = value; //3. afterNodeAccess(e); return oldValue; } } ++modCount; //判斷閾值,決定是否擴容 if (++size > threshold) resize(); //4. afterNodeInsertion(evict); return null; }
紅黑樹
紅黑樹是二叉排序樹,但在每個結點增加了一個儲存位來標識顏色,red或者black;滿足二叉排序樹的所有特性:
1.若任意結點的左子樹不為空,則左子樹的所有結點的值小於根結點;
2.若任意結點的右子樹不為空,則右子樹的所有結點的值大於根結點;
3.左右子樹也是二叉排序樹;
4.沒有鍵值相等的節點
一個有n個節點的二叉排序樹的高度為lgn,所以查詢時間複雜度為O(lgn);
執行緒不安全的
HashMap是執行緒不安全的,是因為在resize的時候會產生死迴圈;預設的size是16,當超過這個size之後,會擴容,這樣一來,整個Hash表中的元素都需要被重新計算一遍,實現程式碼如下所示:
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}transfer簡單解釋下:每次取出舊陣列的頭結點的next,之後重新計算頭結點在新的Hash中的位置,然後將頭節點的next指向新的table[i],然後把table[i]設定成當前的頭結點,那麼就完成了頭結點的轉移;
所以轉移之後的順序會跟之前的順序相反,比如原來是1->2->3,轉移之後為
第一次 1
第二次 2 1
第三次 3 2 1,
順序正好反過來了。HashMap的死鎖問題就出在這個transfer函式上;
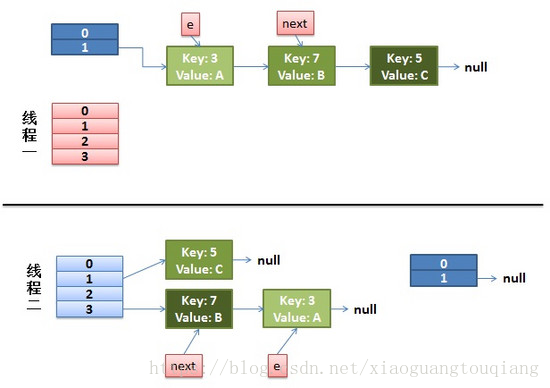
用個圖進行簡單的說明:
執行緒一執行到這裡被掛起;執行緒二執行了
Entry<K,V> next = e.next;完成了3和7元素的轉移之後,執行緒一就接著執行,這時候,執行緒一種3.next是7,執行緒二中7.next是3;就形成了環形的連結串列;
另外:在迭代的過程中,如果有執行緒修改了map,會丟擲ConcurrentModificationException錯誤,就是所謂的fail-fast策略;
無序的
HashMap是無序的,先通過一個例子驗證下
HashMap< String, String> map = new HashMap<>();
map.put("5", "@sohu.com");
map.put("2","@163.com");
map.put("3", "@sina.com");
for (String key : map.keySet()) {
System.out.println("key= "+key+" and value= "+map.get(key));
}程式的返回結果:
key= 2 and value= @163.com
key= 3 and value= @sina.com
key= 5 and value= @sohu.com可以發現,放進去的順序和遍歷的時候的順序是不一致的;那麼為什麼會是這樣的那,我們需要先了解下HashMap的遍歷方式;
先說map.keySet的方式,keySet的程式碼如下所示(Jdk8的情況)
public Set<K> keySet() {
Set<K> ks = keySet;
if (ks == null) {
ks = new KeySet();
keySet = ks;
}
return ks;
}可以看到是new了一個keySet物件,這個KeySet是一個內部類,程式碼如下所示
final class KeySet extends AbstractSet<K> {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator<K> iterator() { return new KeyIterator(); }
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator<K> spliterator() {
return new KeySpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumer<? super K> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
}這個內部類中的iterator方法實現了迭代器介面,介面定義程式碼如下
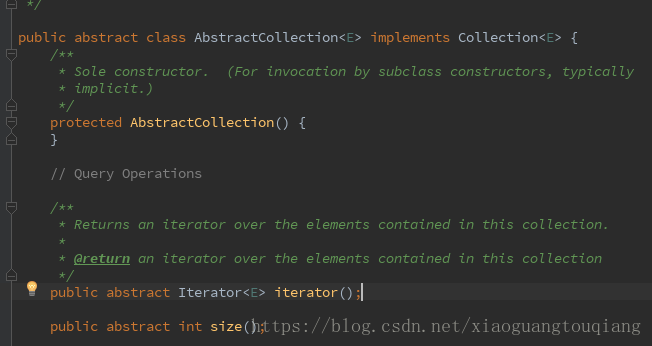
這裡有一點需要說明下,增強for迴圈,那麼什麼是增強for迴圈那,上面遍歷keyset的for就是一個增強for迴圈:
for(String key:keys)類似這樣的,底層在迭代的時候還是使用的迭代器,當然這個呼叫是jvm來完成的,我們只需要知道呼叫for的時候就會呼叫iterator方法,我們再來接著看iteraotr方法返回一個new keyIterator物件

然後KeyIteraotr類的定義如下所示;

這裡的nextNode方法如下所示
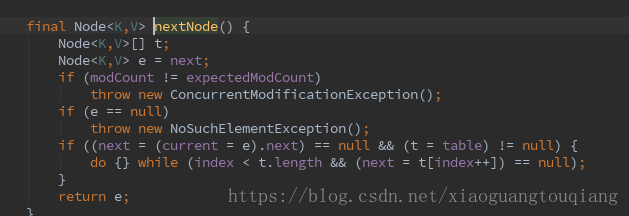
這裡看到的就是最終的核心了,真正的遍歷過程;之前我們說HashMap的資料結構是陣列+連結串列,這裡遍歷的時候從第一個元素開始,然後遍歷連結串列,當連結串列遍歷結束的時候,遍歷下面一個數組和對應的連結串列資料;
現在再來看看HashMap為啥是無序的,因為存放的時候是根據key的Hash值來存放的,先放進去的計算hash之後可能存放在陣列的後面了,所以遍歷之後就在後面的再遍歷出來;