
sparkSQL1.1入門之一:為什麼sparkSQL
阿新 • • 發佈:2019-02-08
2014年9月11日,Spark1.1.0忽然之間釋出。筆者立即下載、編譯、部署了Spark1.1.0。關於Spark1.1的編譯和部署,請參看筆者部落格Spark1.1.0 原始碼編譯和部署包生成 。
Spark1.1.0中變化較大是sparkSQL和MLlib,sparkSQL1.1.0主要的變動有:
第一節:為什麼sparkSQL 為本篇,介紹sparkSQL的發展歷程和效能 第二節:sparkSQL架構 介紹catalyst,然後介紹sqlContext、hiveContext的執行架構及區別 第三節:sparkSQL元件之解析 介紹sparkSQL執行架構中的各個元件的功能和實現 第四節:深入瞭解sparkSQL之執行 使用hive/console更深入瞭解各種計劃是如何生成的 第五節:測試環境之搭建 介紹後面章節將使用的環境搭建和測試資料 第六節:sparkSQL之基礎應用 介紹sqlContext的RDD、Json、parquet使用以及hiveContext使用 第七節:ThriftServer和CLI 介紹TriftServer和CLI的使用,以及如何使用JDBC訪問sparkSQL資料 第八節:sparkSQL之綜合應用 介紹sparkSQL和MLlib、sparkSQL和GraphX結合使用 第九節:sparkSQL之調優 介紹CG、壓縮、序化器、快取之使用 第十節:總結 至於與hive的相容性、具體的SQL語法以後有機會再介紹。 本篇為第一節,為什麼sparkSQL? 1:sparkSQL的發展歷程。 A:hive and shark sparkSQL的前身是shark。在hadoop發展過程中,為了給熟悉RDBMS但又不理解MapReduce的技術人員提供快速上手的工具,hive應運而生,是當時唯一執行在hadoop上的SQL-on-Hadoop工具。但是,MapReduce計算過程中大量的中間磁碟落地過程消耗了大量的I/O,降低的執行效率,為了提高SQL-on-Hadoop的效率,大量的SQL-on-Hadoop工具開始產生,其中表現較為突出的是: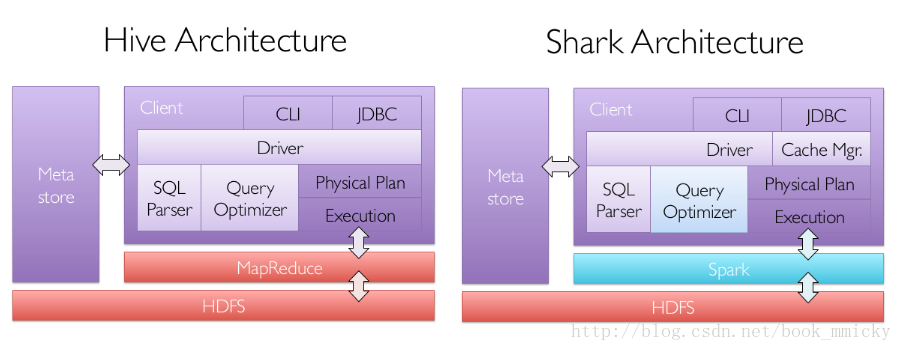
B:Shark和sparkSQL 但是,隨著Spark的發展,對於野心勃勃的Spark團隊來說,Shark對於hive的太多依賴(如採用hive的語法解析器、查詢優化器等等),制約了Spark的One Stack rule them all的既定方針,制約了spark各個元件的相互整合,所以提出了sparkSQL專案。SparkSQL拋棄原有Shark的程式碼,汲取了Shark的一些優點,如記憶體列儲存(In-Memory Columnar Storage)、Hive相容性等,重新開發了SparkSQL程式碼;由於擺脫了對hive的依賴性,SparkSQL無論在資料相容、效能優化、元件擴充套件方面都得到了極大的方便,真可謂“退一步, 海闊天空”。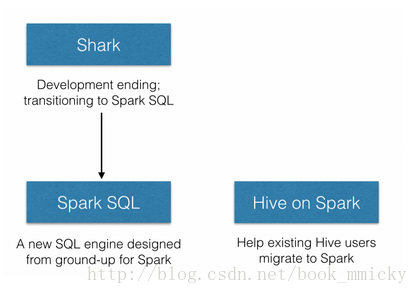
其中sparkSQL作為Spark生態的一員繼續發展,而不再受限於hive,只是相容hive;而hive on spark是一個hive的發展計劃,該計劃將spark作為hive的底層引擎之一,也就是說,hive將不再受限於一個引擎,可以採用map-reduce、Tez、spark等引擎。 2:sparkSQL的效能 shark的出現,使得SQL-on-Hadoop的效能比hive有了10-100倍的提高: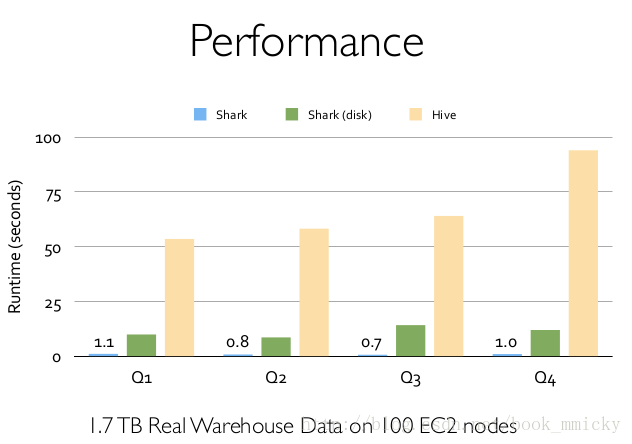
那麼,擺脫了hive的限制,sparkSQL的效能又有怎麼樣的表現呢?雖然沒有shark相對於hive那樣矚目地效能提升,但也表現得非常優異: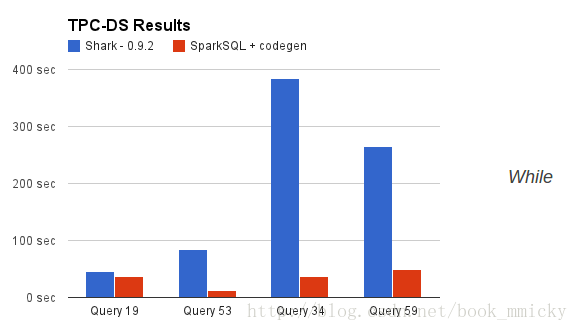
為什麼sparkSQL的效能會得到怎麼大的提升呢?主要sparkSQL在下面幾點做了優化: A:記憶體列儲存(In-Memory Columnar Storage) sparkSQL的表資料在記憶體中儲存不是採用原生態的JVM物件儲存方式,而是採用記憶體列儲存,如下圖所示。
該儲存方式無論在空間佔用量和讀取吞吐率上都佔有很大優勢。 對於原生態的JVM物件儲存方式,每個物件通常要增加12-16位元組的額外開銷,對於一個270MB的TPC-H lineitem table資料,使用這種方式讀入記憶體,要使用970MB左右的記憶體空間(通常是2~5倍於原生資料空間);另外,使用這種方式,每個資料記錄產生一個JVM物件,如果是大小為200B的資料記錄,32G的堆疊將產生1.6億個物件,這麼多的物件,對於GC來說,可能要消耗幾分鐘的時間來處理(JVM的垃圾收集時間與堆疊中的物件數量呈線性相關)。顯然這種記憶體儲存方式對於基於記憶體計算的spark來說,很昂貴也負擔不起。 對於記憶體列儲存來說,將所有原生資料型別的列採用原生陣列來儲存,將Hive支援的複雜資料型別(如array、map等)先序化後並接成一個位元組陣列來儲存。這樣,每個列建立一個JVM物件,從而導致可以快速的GC和緊湊的資料儲存;額外的,還可以使用低廉CPU開銷的高效壓縮方法(如字典編碼、行長度編碼等壓縮方法)降低記憶體開銷;更有趣的是,對於分析查詢中頻繁使用的聚合特定列,效能會得到很大的提高,原因就是這些列的資料放在一起,更容易讀入記憶體進行計算。 B:位元組碼生成技術(bytecode generation,即CG) 在資料庫查詢中有一個昂貴的操作是查詢語句中的表示式,主要是由於JVM的記憶體模型引起的。比如如下一個查詢:
然後,通過呼叫,最終呼叫: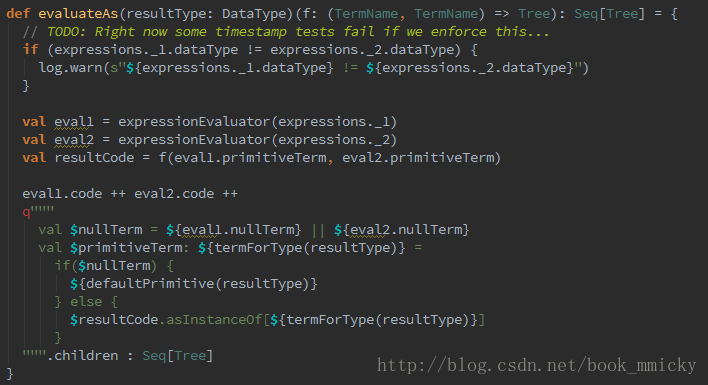
最終實現效果類似如下虛擬碼: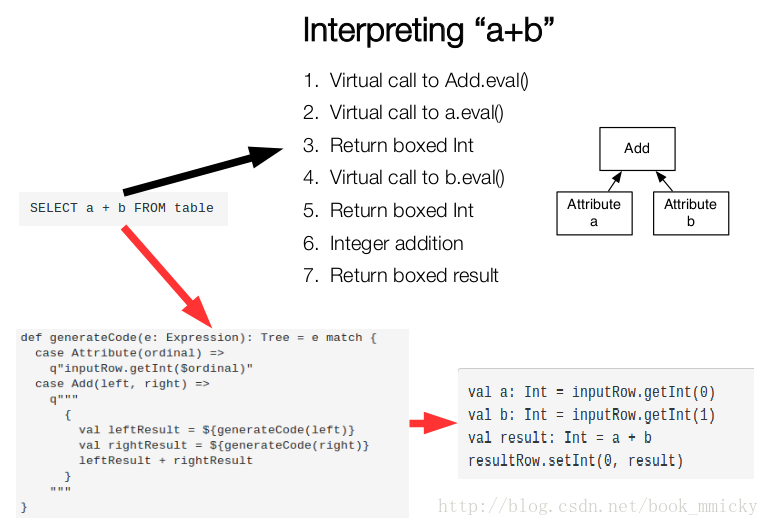
C:scala程式碼優化 另外,sparkSQL在使用Scala編寫程式碼的時候,儘量避免低效的、容易GC的程式碼;儘管增加了編寫程式碼的難度,但對於使用者來說,還是使用統一的介面,沒受到使用上的困難。下圖是一個scala程式碼優化的示意圖:
- 增加了JDBC/ODBC Server(ThriftServer),使用者可以在應用程式中連線到SparkSQL並使用其中的表和快取表。
- 增加了對JSON檔案的支援
- 增加了對parquet檔案的本地優化
- 增加了支援將python、scala、java的lambda函式註冊成UDF,並能在SQL中直接引用
- 引入了動態位元組碼生成技術(bytecode generation,即CG),明顯地提升了複雜表示式求值查詢的速率。
- 統一API介面,如sql()、SchemaRDD生成等。
- ......
第一節:為什麼sparkSQL 為本篇,介紹sparkSQL的發展歷程和效能 第二節:sparkSQL架構 介紹catalyst,然後介紹sqlContext、hiveContext的執行架構及區別 第三節:sparkSQL元件之解析 介紹sparkSQL執行架構中的各個元件的功能和實現 第四節:深入瞭解sparkSQL之執行 使用hive/console更深入瞭解各種計劃是如何生成的 第五節:測試環境之搭建 介紹後面章節將使用的環境搭建和測試資料 第六節:sparkSQL之基礎應用 介紹sqlContext的RDD、Json、parquet使用以及hiveContext使用 第七節:ThriftServer和CLI 介紹TriftServer和CLI的使用,以及如何使用JDBC訪問sparkSQL資料 第八節:sparkSQL之綜合應用 介紹sparkSQL和MLlib、sparkSQL和GraphX結合使用 第九節:sparkSQL之調優 介紹CG、壓縮、序化器、快取之使用 第十節:總結 至於與hive的相容性、具體的SQL語法以後有機會再介紹。 本篇為第一節,為什麼sparkSQL? 1:sparkSQL的發展歷程。 A:hive and shark sparkSQL的前身是shark。在hadoop發展過程中,為了給熟悉RDBMS但又不理解MapReduce的技術人員提供快速上手的工具,hive應運而生,是當時唯一執行在hadoop上的SQL-on-Hadoop工具。但是,MapReduce計算過程中大量的中間磁碟落地過程消耗了大量的I/O,降低的執行效率,為了提高SQL-on-Hadoop的效率,大量的SQL-on-Hadoop工具開始產生,其中表現較為突出的是:
- MapR的Drill
- Cloudera的Impala
- Shark
B:Shark和sparkSQL 但是,隨著Spark的發展,對於野心勃勃的Spark團隊來說,Shark對於hive的太多依賴(如採用hive的語法解析器、查詢優化器等等),制約了Spark的One Stack rule them all的既定方針,制約了spark各個元件的相互整合,所以提出了sparkSQL專案。SparkSQL拋棄原有Shark的程式碼,汲取了Shark的一些優點,如記憶體列儲存(In-Memory Columnar Storage)、Hive相容性等,重新開發了SparkSQL程式碼;由於擺脫了對hive的依賴性,SparkSQL無論在資料相容、效能優化、元件擴充套件方面都得到了極大的方便,真可謂“退一步, 海闊天空”。
- 資料相容方面 不但相容hive,還可以從RDD、parquet檔案、JSON檔案中獲取資料,未來版本甚至支援獲取RDBMS資料以及cassandra等NOSQL資料
- 效能優化方面 除了採取In-Memory Columnar Storage、byte-code generation等優化技術外、將會引進Cost Model對查詢進行動態評估、獲取最佳物理計劃等等
- 元件擴充套件方面 無論是SQL的語法解析器、分析器還是優化器都可以重新定義,進行擴充套件
其中sparkSQL作為Spark生態的一員繼續發展,而不再受限於hive,只是相容hive;而hive on spark是一個hive的發展計劃,該計劃將spark作為hive的底層引擎之一,也就是說,hive將不再受限於一個引擎,可以採用map-reduce、Tez、spark等引擎。 2:sparkSQL的效能 shark的出現,使得SQL-on-Hadoop的效能比hive有了10-100倍的提高:
那麼,擺脫了hive的限制,sparkSQL的效能又有怎麼樣的表現呢?雖然沒有shark相對於hive那樣矚目地效能提升,但也表現得非常優異:
為什麼sparkSQL的效能會得到怎麼大的提升呢?主要sparkSQL在下面幾點做了優化: A:記憶體列儲存(In-Memory Columnar Storage) sparkSQL的表資料在記憶體中儲存不是採用原生態的JVM物件儲存方式,而是採用記憶體列儲存,如下圖所示。
該儲存方式無論在空間佔用量和讀取吞吐率上都佔有很大優勢。 對於原生態的JVM物件儲存方式,每個物件通常要增加12-16位元組的額外開銷,對於一個270MB的TPC-H lineitem table資料,使用這種方式讀入記憶體,要使用970MB左右的記憶體空間(通常是2~5倍於原生資料空間);另外,使用這種方式,每個資料記錄產生一個JVM物件,如果是大小為200B的資料記錄,32G的堆疊將產生1.6億個物件,這麼多的物件,對於GC來說,可能要消耗幾分鐘的時間來處理(JVM的垃圾收集時間與堆疊中的物件數量呈線性相關)。顯然這種記憶體儲存方式對於基於記憶體計算的spark來說,很昂貴也負擔不起。 對於記憶體列儲存來說,將所有原生資料型別的列採用原生陣列來儲存,將Hive支援的複雜資料型別(如array、map等)先序化後並接成一個位元組陣列來儲存。這樣,每個列建立一個JVM物件,從而導致可以快速的GC和緊湊的資料儲存;額外的,還可以使用低廉CPU開銷的高效壓縮方法(如字典編碼、行長度編碼等壓縮方法)降低記憶體開銷;更有趣的是,對於分析查詢中頻繁使用的聚合特定列,效能會得到很大的提高,原因就是這些列的資料放在一起,更容易讀入記憶體進行計算。 B:位元組碼生成技術(bytecode generation,即CG) 在資料庫查詢中有一個昂貴的操作是查詢語句中的表示式,主要是由於JVM的記憶體模型引起的。比如如下一個查詢:
SELECT a + b FROM table- 呼叫虛擬函式Add.eval(),需要確認Add兩邊的資料型別
- 呼叫虛擬函式a.eval(),需要確認a的資料型別
- 確定a的資料型別是Int,裝箱
- 呼叫虛擬函式b.eval(),需要確認b的資料型別
- 確定b的資料型別是Int,裝箱
- 呼叫Int型別的Add
- 返回裝箱後的計算結果
然後,通過呼叫,最終呼叫:
最終實現效果類似如下虛擬碼:
val a: Int = inputRow.getInt(0)
val b: Int = inputRow.getInt(1)
val result: Int = a + b
resultRow.setInt(0, result)C:scala程式碼優化 另外,sparkSQL在使用Scala編寫程式碼的時候,儘量避免低效的、容易GC的程式碼;儘管增加了編寫程式碼的難度,但對於使用者來說,還是使用統一的介面,沒受到使用上的困難。下圖是一個scala程式碼優化的示意圖: