
MongoDB:Too many open files
本篇文章記錄一次MongoDB叢集故障的解決過程
2016-3-14早上,剛開完早會,運營組的同事QQ發來訊息,線上環境MongoDB叢集的一個節點down了,讓我上去看一下。當時沒把他當回事,因為之前叢集也出現過這樣的現象,最簡單的解決方法就是把mongod.conf配置檔案中配置dbpath目錄下的檔案全部刪除,然後重啟mongod,想當然照做
魯莽的第一次嘗試
按照官方的說明,當replica set的節點落後於主節點很多資料或者一個節點新加入一個叢集時,就應該利用mongodb的initial sync特性來同步叢集的資料,並給出了兩種解決方法:
- Restart the mongod with an empty data directory and let MongoDB’s normal initial syncing feature restore the data. This is the more simple option but may take longer to replace the data.See Procedures.
- Restart the machine with a copy of a recent data directory from another member in the replica set. This procedure can replace the data more quickly but requires more manual steps.See Sync by Copying Data Files from Another Member.
簡單說,第一種方法簡單粗暴,直接刪除dbpath下的全部檔案,當做是第一次加入replica set的節點,優點是操作簡單,缺點是如果資料太多將是一個非常漫長的過程
檢視日誌後再次嘗試
好景不長,很快這個節點又down了,我開始變得緊張,難道initial sync對我們的場景沒用?我嘗試在網上搜索:“mongodb replica set member always STARTUP2”,沒用找到答案,網上求助無望之後我決定檢視mongodb的日誌,期望從這裡可以找到一點有用的資訊,當我開啟日誌的一瞬間,有點被驚到了:
2016-03-14T10:23:40.921+0800 [initandlisten] ERROR: Out of file descriptors. Waiting one second before trying to accept more connections.
2016-03-14T10:23:41.921+0800 [initandlisten] Listener: accept() returns -1 errno:24 Too many open files
2016-03-14T10:23:41.921+0800 [initandlisten] ERROR: Out of file descriptors. Waiting one second before trying to accept more connections.
2016-03-14T10:23:42.922+0800 [initandlisten] Listener: accept() returns -1 errno:24 Too many open files
2016-03-14T10:23:42.922+0800 [initandlisten] ERROR: Out of file descriptors. Waiting one second before trying to accept more connections.
2016-03-14T10:23:43.922+0800 [initandlisten] Listener: accept() returns -1 errno:24 Too many open files
一堆的ERROR,但有一個好訊息就是:“錯誤訊息只有一種”,我又在網上搜索:“Too many open files”,這次搜到了問題:《Mongod give error “too many opens file” 》,其中一位熱心人士給了一個連結:《UNIX ulimit Settings》,我感覺自己找到了答案,按照這上面的說明一定可以解決我的問題的,但是有一個問題,我的replica set有三個節點,為什麼只有這個節點掛掉了?我打開了另外兩個節點的日誌,同樣找到了“Too many open files”的錯誤日誌。難道“Too many open files”不是造成這個節點down掉的根本原因?如果不是,那又是什麼原因?如果是,那就慘了,估計很快另外的兩個節點也可能down掉。
根據《UNIX ulimit Settings》的說明,我先是通過ulimit -n和ulimit -u修改限制,進行第二次嘗試,此時已經是晚上了,看著故障節點上的日誌已經沒有了“Too many open files”的錯誤日誌了,這次必定成功,只是時間的問題了,很滿足的就下班回家了
還是沒有解決
2016-3-15早上8點30多到公司,按照我的習慣是會先瀏覽瀏覽網頁或者部落格看看書什麼的,但有一件事是一定不會忘的,確認一下mongodb叢集是不是恢復了。拖動一下滑鼠,螢幕亮起來了,一看日誌,我去,怎麼直到昨晚21點多久沒有了?看著日誌裡面的最後幾行,我很煩
2016-03-16T21:15:19.322+0800 [SyncSourceFeedbackThread] Socket say send() errno:32 Broken pipe 20.10.4.12:27017
2016-03-16T21:15:19.323+0800 [SyncSourceFeedbackThread] SyncSourceFeedback error sending update: socket exception [SEND_ERROR] for 20.10.4.12:27017
2016-03-16T21:15:19.323+0800 [SyncSourceFeedbackThread] replset setting syncSourceFeedback to node12:27017
2016-03-16T21:15:19.599+0800 [rsSync] replication oplog stream went back in time. previous timestamp: 56e93336:30 newest timestamp: 56e8eaf7:1. attempting to sync directly from primary.
2016-03-16T21:15:19.599+0800 [rsSync] SEVERE: Invalid access at address: 0x98
2016-03-16T21:15:19.613+0800 [rsSync] SEVERE: Got signal: 11 (Segmentation fault).
“SyncSourceFeedback error sending update: socket exception [SEND_ERROR] for”,什麼鬼啊?偶然的網路不好導致的?一定是了,我就又無腦的刪除dbpath下的檔案等著mongodb的initial sync,但日誌裡面一直會列印:
replset info node13:27017 just heartbeated us, but our heartbeat failed: , not changing state
2016-03-17T12:38:16.264+0800 [rsHealthPoll] DBClientCursor::init call() failed
2016-03-17T12:38:16.264+0800 [rsHealthPoll] replset info node13:27017 just heartbeated us, but our heartbeat failed: , not changing state
Primary反覆更換,剛選舉出來的Primary節點很快又因為通訊不正常切換到另外的節點上。我到故障節點外的兩個節點上檢視日誌,還有“Too many open files”的錯誤日誌,並且很快了又一個節點down掉的,我才想起來昨天只改了故障節點的ulimit值。迅速按照《UNIX ulimit Settings》的方法修改:
touch /etc/security/limits.d/99-mongodb.conf
寫入下面的內容:
# Default limit for number of user’s processes to prevent
# accidental fork bombs.
# See rhbz #432903 for reasoning.
#
# * soft nproc 4096
# root soft nproc unlimited
* soft nofile 64000
* hard nofile 64000
* soft fsize unlimited
* hard fsize unlimited
* soft cpu unlimited
* hard cpu unlimited
* soft nproc 64000
* hard nproc 64000
重啟mongod(mongod –config /etc/mongod.conf),之前的兩個節點很快恢復,再檢視日誌沒有錯誤提示了
從中午12:40左右,重啟了故障節點,經過一系列的資料拷貝,過程非常艱辛
正確的解決方法
更新時間: 2016-07-19
同樣的問題還是出現了,原因是上次的解決方案並沒有應用到新的環境中,之前的方法雖然解決了問題,但一看就覺得很山寨,下面是我目前覺得更好更規範的解決方案
我們目前的部署環境中均使用root使用者執行以下命令來啟動mongodb
mongod --config /etc/mongod.conf實際系統安裝的mongodb包含一個service檔案“/usr/lib/systemd/system/mongod.service”,該檔案中定義了mongodb服務相關的資訊,如下:
[Unit]
Description=High-performance, schema-free document-oriented database
After=syslog.target network.target
[Service]
Type=forking
User=mongodb
EnvironmentFile=/etc/sysconfig/mongod
ExecStart=/usr/bin/mongod $OPTIONS run
PrivateTmp=true
LimitNOFILE=64000
TimeoutStartSec=180
[Install]
WantedBy=multi-user.target
所以,只要我們通過systemctl start mongod的方式啟動mongodb即可解決上面的問題
前面提過,目前的環境是root使用者啟動的,這導致mongodb相關的目錄的owner均是root,具體包含:
/var/lib/mongodb
/var/log/mongodb
/var/run/mongodb
我們需要按照下面的步驟執行就可以解決問題:
1. 修改mongodb專案目錄所屬者為mongodb:mongodb
chown -R mongodb:mongodb /var/lib/mongodb/
chown -R mongodb:mongodb /var/log/mongodb/
chown -R mongodb:mongodb /var/run/mongodb/
- 重啟mongodb服務
systemctl start mongod看到啟動成功的提示資訊即可,可以通過“cat /proc/$pid/limits”來驗證重啟後是否生效
曙光
下午16點左右,建立所有進行到90%我的視線已經捨不得移開那黑黑的螢幕了,總共2億多條記錄的表,我就盯著它建立了剩餘10%的索引,終於等到索引建立完成,激動的在主節點上敲下命令
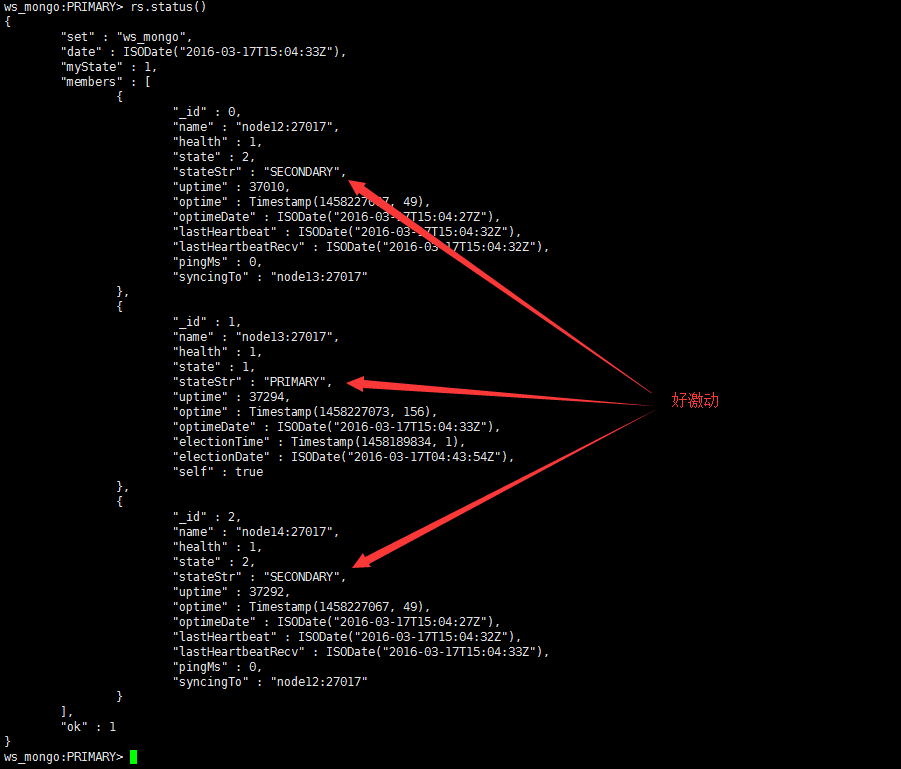
rs.state()
看著故障節點的uptime在向當前時間移動了,激動的一直在那上鍵回車,看著時間一點一點的接近當前時間真的很過癮,就像你跟你的女神表白了,等著她的回覆一樣,期待,害怕。當uptime更新到當前時間時,就差“stateStr”了,你倒是變成”Secondary”啊,還是那“STARTUP2”幹什麼呢?
繼續等待
沒關係,你一時半會還沒反應過來我可以等啊,但我再看故障節點時,他竟然又開始建立索引,後來確認了一下,在資料最多的那張表上,一共建立了4個索引,我現在還在等著他慢慢的建立索引呢,截個圖給大家看看(這是第3個索引,還剩一個僅timestamp一個key的索引)
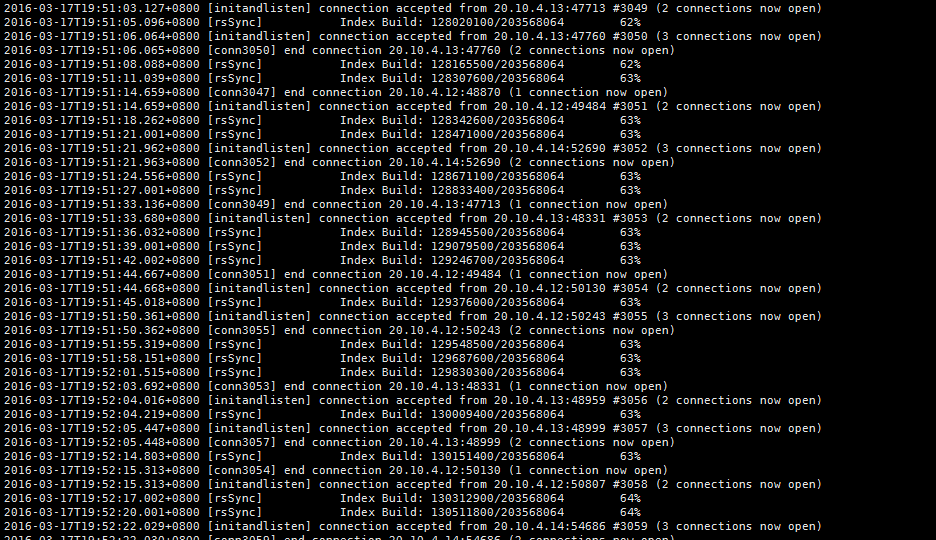
希望他早日康復,我就可以下班了
現在是2016-03-17 23:00,他恢復了(本次恢復從2016-03-17 12:40開始,歷時將近11個小時,另外透露一下資料庫共計473GB,最大的一個表2億多條記錄)
總結
有時候我們的軟體會出現一些奇奇怪怪的現象,就像這次:
- replica set的節點down
- 日誌出現“Too many open files”,“Out of file descriptors”
- 通訊不穩定,叢集反覆選舉Primary節點等等
很嚇人,但幕後黑手只有一個作業系統限制了每個程序/使用者所能開啟的檔案控制代碼數。軟體不會無緣無故的不工作,也不會無緣無故的奇怪