
Linux核心記憶體管理架構
記憶體管理子系統可能是linux核心中最為複雜的一個子系統,其支援的功能需求眾多,如頁面對映、頁面分配、頁面回收、頁面交換、冷熱頁面、緊急頁面、頁面碎片管理、頁面快取、頁面統計等,而且對效能也有很高的要求。本文從記憶體管理硬體架構、地址空間劃分和記憶體管理軟體架構三個方面入手,嘗試對記憶體管理的軟硬體架構做一些巨集觀上的分析總結。
記憶體管理硬體架構
因為記憶體管理是核心最為核心的一個功能,針對記憶體管理效能優化,除了軟體優化,硬體架構也做了很多的優化設計。下圖是一個目前主流處理器上的儲存器層次結構設計方案。

從圖中可以看出,對於讀寫記憶體,硬體設計了3條優化路徑。
1)首先L1 cache支援虛擬地址定址,保證CPU出來的虛擬地址(VA)不需要轉換成實體地址(PA)就可以用來直接查詢L1 cache,提高cache查詢效率。當然用VA查詢cache,有安全等缺陷,這需要CPU做一些特別的設計來進行彌補,具體可以閱讀《
2)如果L1 cache沒有命中,這就需要進行地址轉換,把VA轉換成PA。linux的記憶體對映管理是通過頁表來實現的,但是頁表是放在記憶體中的,如果每次地址轉換過程都需要訪問一次記憶體,其效率是十分低下的。這裡CPU通過TLB硬體單元來加速地址轉換。
3)獲得PA後,在L2 cache中再查詢快取資料。L2 cache一般比L1 cache大一個數量級,其查詢命中率也更高。如果命中獲得資料,則可避免去訪問記憶體,提高訪問效率。
可見,為了優化記憶體訪問效率,現代處理器引入多級cache、TLB等硬體模組(如下圖是一款8核MIPS處理器硬體框圖)。每個硬體模組內部還有大量的設計細節,這裡不再深入,如有興趣可以閱讀《

記憶體對映空間劃分
根據不同的記憶體使用方式和使用場景需要,核心把記憶體對映地址空間劃分成多個部分,每個劃分空間都有自己的起止地址、分配介面和使用場景。下圖是一個常見的32位地址空間劃分結構(點選見大圖)。

- DMA記憶體動態分配地址空間:一些DMA裝置因為其自身定址能力的限制,不能訪問所有記憶體空間。如早期的ISA裝置只能在24位地址空間執行DMA,即只能訪問前16MB記憶體。所以需要劃分出DMA記憶體動態分配空間,即DMA zone。其分配通過加上GFP_ATOMIC控制符的kmalloc介面來申請。
- 直接記憶體動態分配地址空間:因為訪問效率等原因,核心對記憶體採用簡單的線性對映,但是因為32位CPU的定址能力(4G大小)和核心地址空間起始的設定(3G開始),會導致核心的地址空間資源不足,當記憶體大於1GB時,就無法直接對映所有記憶體。無法直接對映的地址空間部分,即highmem zone。在DMA zone和highmem zone中間的區域即normal zone,主要用於核心的動態記憶體分配。其分配通過kmalloc介面來申請。
- 高階記憶體動態分配地址空間:高階記憶體分配的記憶體是虛擬地址連續而實體地址不連續的記憶體,一般用於核心動態載入的模組和驅動,因為核心可能運行了很久,記憶體頁面碎片情況嚴重,如果要申請大的連續地址的記憶體頁會比較困難,容易導致分配失敗。根據應用需要,高階記憶體分配提供多個介面:
- vmalloc:指定分配大小,page位置和虛擬地址隱式分配;
- vmap:指定page位置陣列,虛擬地址隱式分配;
- ioremap:指定實體地址和大小,虛擬地址隱式分配。
- 持久對映地址空間:核心上下文切換會伴隨著TLB重新整理,這會導致效能下降。但一些使用高階記憶體的模組對效能也有很高要求。持久對映空間在核心上下文切換時,其TLB不重新整理,所以它們對映的高階地址空間定址效率較高。其分配通過kmap介面來申請。kmap與vmap的區別是:vmap可以對映一組page,即page不連續,但虛擬地址連續,而kmap只能對映一個page到虛擬地址空間。kmap主要用於fs、net等對高階記憶體訪問有較高效能要求的模組中。
- 固定對映地址空間:持久對映的問題是可能會休眠,在中斷上下文、自旋鎖臨界區等不能阻塞的場景中不可用。為了解決這個問題,核心又劃分出固定對映,其介面不會休眠。固定對映空間通過kmap_atomic介面來對映。kmap_atomic的使用場景與kmap較為相似,主要用於mm、fs、net等對高階記憶體訪問有較高效能要求而且不能休眠的模組中。
不同的CPU體系架構在地址空間劃分上不盡相同,但為了保證CPU體系差異對外部模組不可見,記憶體地址空間的分配介面的語義是一致的。
因為64位CPU一般都不需要高階記憶體(當然也可以支援),在地址空間劃分上與32位CPU的差異較大,下圖是一個MIPS64 CPU的核心地址空間劃分示例。
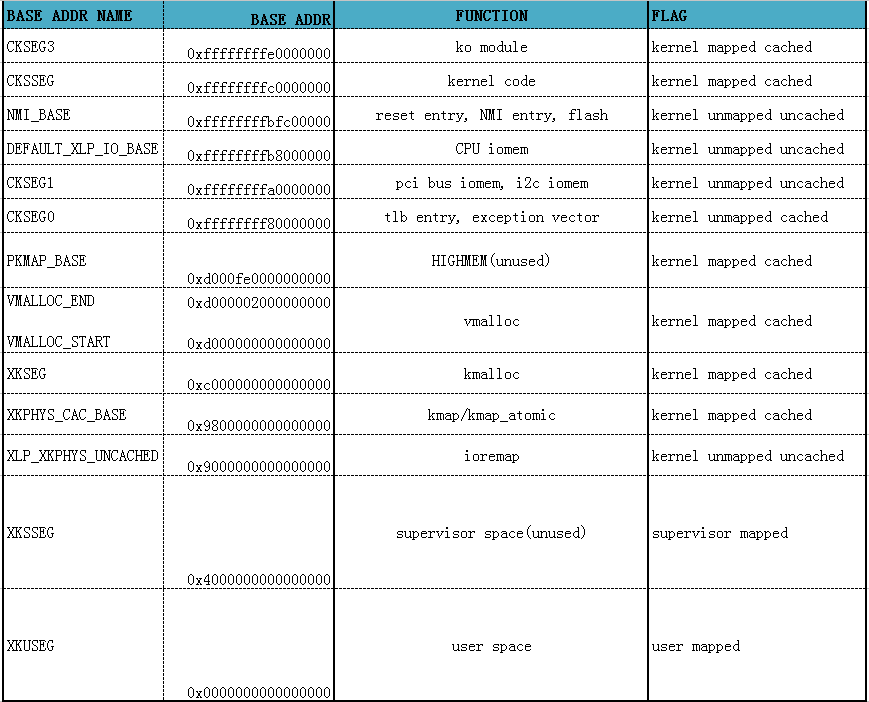
記憶體管理軟體架構
核心記憶體管理的核心工作就是記憶體的分配回收管理,其內部分為2個體系:頁管理和物件管理。頁管理體系是一個兩級的層次結構,物件管理體系是一個三級的層次結構,分配成本和操作對CPU cache和TLB的負面影響,從上而下逐漸升高。
- 頁管理層次結構:由冷熱快取、夥伴系統組成的兩級結構。負責記憶體頁的快取、分配、回收。
- 物件管理層次結構:由per-cpu快取記憶體、slab快取、夥伴系統組成的三級結構。負責物件的快取、分配、回收。這裡的物件指小於一頁大小的記憶體塊。
除了記憶體分配,記憶體釋放也是按照此層次結構操作。如釋放物件,先釋放到per-cpu快取,再釋放到slab快取,最後再釋放到夥伴系統。

框圖中有三個主要模組,即夥伴系統、slab分配器和per-cpu(冷熱)快取。他們的對比分析如下。

--完--