
一個案例看機器學習建模基本過程
machine learning for credit scoring
Banks play a crucial role in market economies. They decide who can get finance and on what terms and can make or break investment decisions. For markets and society to function, individuals and companies need access to credit.
Credit scoring algorithms, which make a guess at the probability of default, are the method banks use to determine whether or not a loan should be granted. This competition requires participants to improve on the state of the art in credit scoring, by predicting the probability that somebody will experience financial distress in the next two years.
Attribute Information:
| Variable Name | Description | Type |
|---|---|---|
| SeriousDlqin2yrs | Person experienced 90 days past due delinquency or worse | Y/N |
| RevolvingUtilizationOfUnsecuredLines | Total balance on credit divided by the sum of credit limits | percentage |
| age | Age of borrower in years | integer |
| NumberOfTime30-59DaysPastDueNotWorse | Number of times borrower has been 30-59 days past due | integer |
| DebtRatio | Monthly debt payments | percentage |
| MonthlyIncome | Monthly income | real |
| NumberOfOpenCreditLinesAndLoans | Number of Open loans | integer |
| NumberOfTimes90DaysLate | Number of times borrower has been 90 days or more past due. | integer |
| NumberRealEstateLoansOrLines | Number of mortgage and real estate loans | integer |
| NumberOfTime60-89DaysPastDueNotWorse | Number of times borrower has been 60-89 days past due | integer |
| NumberOfDependents | Number of dependents in family | integer |
將資料讀進pandas
import pandas as pd
pd.set_option('display.max_columns', 500)
import zipfile
with zipfile.ZipFile('KaggleCredit2.csv.zip', 'r') as z:
f = z.open('KaggleCredit2.csv')
data = pd.read_csv(f, index_col=0)
data.head()| SeriousDlqin2yrs | RevolvingUtilizationOfUnsecuredLines | age | NumberOfTime30-59DaysPastDueNotWorse | DebtRatio | MonthlyIncome | NumberOfOpenCreditLinesAndLoans | NumberOfTimes90DaysLate | NumberRealEstateLoansOrLines | NumberOfTime60-89DaysPastDueNotWorse | NumberOfDependents | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0.766127 | 45.0 | 2.0 | 0.802982 | 9120.0 | 13.0 | 0.0 | 6.0 | 0.0 | 2.0 |
| 1 | 0 | 0.957151 | 40.0 | 0.0 | 0.121876 | 2600.0 | 4.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 2 | 0 | 0.658180 | 38.0 | 1.0 | 0.085113 | 3042.0 | 2.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0 | 0.233810 | 30.0 | 0.0 | 0.036050 | 3300.0 | 5.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0 | 0.907239 | 49.0 | 1.0 | 0.024926 | 63588.0 | 7.0 | 0.0 | 1.0 | 0.0 | 0.0 |
data.shape(108648, 11)
去除異常值
data.isnull().sum(axis=0)SeriousDlqin2yrs 0
RevolvingUtilizationOfUnsecuredLines 0
age 0
NumberOfTime30-59DaysPastDueNotWorse 0
DebtRatio 0
MonthlyIncome 0
NumberOfOpenCreditLinesAndLoans 0
NumberOfTimes90DaysLate 0
NumberRealEstateLoansOrLines 0
NumberOfTime60-89DaysPastDueNotWorse 0
NumberOfDependents 0
dtype: int64
data.dropna(inplace=True)
data.shape(108648, 11)
建立X 和 y
y = data['SeriousDlqin2yrs']
X = data.drop('SeriousDlqin2yrs', axis=1)import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
sns.countplot(x='SeriousDlqin2yrs',data=data)<matplotlib.axes._subplots.AxesSubplot at 0x7f0c07606dd0>
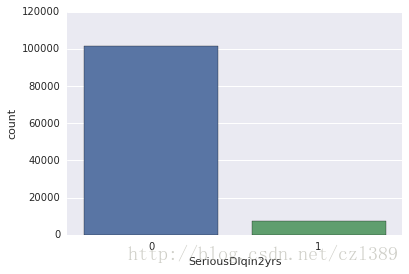
label為1的樣本偏少,可見樣本失衡
練習1:資料集準備
把資料切分成訓練集和測試集
切分資料集
# Added version check for recent scikit-learn 0.18 checks
from distutils.version import LooseVersion as Version
from sklearn import __version__ as sklearn_version
if Version(sklearn_version) < '0.18':
from sklearn.cross_validation import train_test_split
else:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=0)對連續值特徵做幅度縮放
from sklearn.preprocessing import StandardScaler
stdsc=StandardScaler()
X_train_std=stdsc.fit_transform(X_train)
X_test_std=stdsc.transform(X_test)練習2:用多種機器學習方法建模
使用logistic regression建模,並且輸出一下係數,分析重要度。
使用決策樹/SVM/KNN…等sklearn分類演算法進行分類,嘗試瞭解引數含義,調整不同的引數。
logistic regression
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(penalty='l1',C=1000.0, random_state=0)
lr.fit(X_train_std, y_train)
lrLogisticRegression(C=1000.0, class_weight=None, dual=False,
fit_intercept=True, intercept_scaling=1, max_iter=100,
multi_class='ovr', n_jobs=1, penalty='l1', random_state=0,
solver='liblinear', tol=0.0001, verbose=0, warm_start=False)
print '訓練集準確度:%f'%lr.score(X_train_std,y_train)訓練集準確度:0.933126
邏輯迴歸模型的係數
import numpy as np
feat_labels=data.columns[1:]
coefs=lr.coef_
indices=np.argsort(coefs[0])[::-1]
for f in range(X_train.shape[1]):
print '%2d) %-*s %f'%(f,30,feat_labels[indices[f]],coefs[0,indices[f]]) 0) NumberOfTime30-59DaysPastDueNotWorse 1.728817
1) NumberOfTimes90DaysLate 1.689074
2) DebtRatio 0.312097
3) NumberOfDependents 0.116383
4) RevolvingUtilizationOfUnsecuredLines -0.014289
5) NumberOfOpenCreditLinesAndLoans -0.091914
6) MonthlyIncome -0.115238
7) NumberRealEstateLoansOrLines -0.196420
8) age -0.364304
9) NumberOfTime60-89DaysPastDueNotWorse -3.247956
我的理解是權重絕對值大的特徵標籤比較重要
決策樹
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy', max_depth=3, random_state=0)
tree.fit(X_train_std, y_train)DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=3,
max_features=None, max_leaf_nodes=None,
min_impurity_split=1e-07, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=0, splitter='best')
print '訓練集準確度:%f'%tree.score(X_train_std,y_train)訓練集準確度:0.934217
SVM(支援向量機)
太耗時間了,只取了“NumberOfTime60-89DaysPastDueNotWorse”這一項特徵標籤
X_train_std=pd.DataFrame(X_train_std,columns=feat_labels)
X_test_std=pd.DataFrame(X_test_std,columns=feat_labels)
X_train_std[['NumberOfTime60-89DaysPastDueNotWorse']].head()| NumberOfTime60-89DaysPastDueNotWorse | |
|---|---|
| 0 | -0.054381 |
| 1 | -0.054381 |
| 2 | -0.054381 |
| 3 | -0.054381 |
| 4 | -0.054381 |
from sklearn.svm import SVC
svm = SVC()
svm.fit(X_train_std[['NumberOfTime60-89DaysPastDueNotWorse']], y_train)SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
print '訓練集準確度:%f'%svm.score(X_train_std[['NumberOfTime60-89DaysPastDueNotWorse']],y_train)訓練集準確度:0.932876
KNN
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5, p=2, metric='minkowski')
knn.fit(X_train, y_train)KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights='uniform')
練習3:在測試集上預測
在測試集上進行預測,計算準確度
logistic regression
y_pred_lr=lr.predict(X_test)
print('錯誤分類數: %d' % (y_test != y_pred_lr).sum())
print '測試集準確度:%f'%lr.score(X_test_std,y_test)錯誤分類數: 2171
測試集準確度:0.933886
決策樹
y_pred_tree=tree.predict(X_test)
print('錯誤分類數: %d' % (y_test != y_pred_tree).sum())
print '測試集準確度:%f'%tree.score(X_test_std,y_test)錯誤分類數: 2498
訓練集準確度:0.935021
SVM
y_pred_svm=svm.predict(X_test[['DebtRatio']])
print('錯誤分類數: %d' % (y_test != y_pred_svm).sum())
print '測試集準確度:%f'%svm.score(X_test_std[['NumberOfTime60-89DaysPastDueNotWorse']],y_test)錯誤分類數: 4619
訓練集準確度:0.934100
KNN
y_pred_knn=knn.predict(X_test)
print('錯誤分類數: %d' % (y_test != y_pred_knn).sum())
print '測試集準確度:%f'%knn.score(X_test,y_test)錯誤分類數: 2213
訓練集準確度:0.932106
練習4:評估標準
檢視sklearn的官方說明,瞭解混淆矩陣等評估標準,並對此例進行評估。
y的類別
class_names=np.unique(data['SeriousDlqin2yrs'].values)
class_namesarray([0, 1])
4種方法的confusion matrix
from sklearn.metrics import confusion_matrix
cnf_matrix_lr=confusion_matrix(y_test, y_pred_lr)
cnf_matrix_lrarray([[30424, 0],
[ 2171, 0]])
cnf_matrix_tree=confusion_matrix(y_test, y_pred_tree)
cnf_matrix_treearray([[29346, 1078],
[ 1420, 751]])
cnf_matrix_svm=confusion_matrix(y_test, y_pred_svm)
cnf_matrix_svmarray([[27661, 2763],
[ 1856, 315]])
cnf_matrix_knn=confusion_matrix(y_test, y_pred_knn)
cnf_matrix_knnarray([[30351, 73],
[ 2140, 31]])
一個繪製混淆矩陣的函式
import itertools
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')視覺化
以logistic regression 為例
np.set_printoptions(precision=2)
# Plot non-normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix_lr, classes=class_names,
title='Confusion matrix, without normalization')
# Plot normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix_lr, classes=class_names, normalize=True,
title='Normalized confusion matrix')
plt.show()Confusion matrix, without normalization
[[30424 0]
[ 2171 0]]
Normalized confusion matrix
[[ 1. 0.]
[ 1. 0.]]
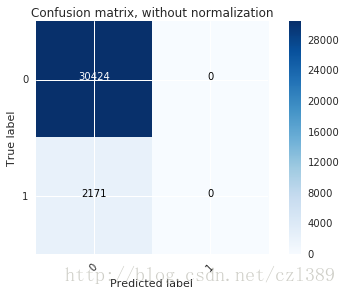
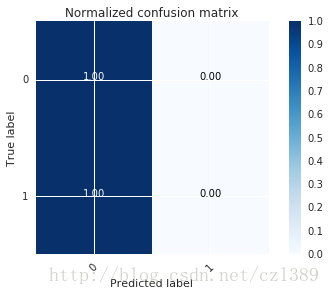
可見,真實標籤為“0”的分類準確率很高。
真實標籤為“1”的分類準確率很低。
練習5:調整模型引數
銀行通常會有更嚴格的要求,因為fraud帶來的後果通常比較嚴重,一般我們會調整模型的標準。
比如在logistic regression當中,一般我們的概率判定邊界為0.5,但是我們可以把閾值設定低一些,來提高模型的“敏感度”,試試看把閾值設定為0.3,再看看這個時候的混淆矩陣等評估指標。
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(penalty='l2',C=1000.0, random_state=0,class_weight={1:0.3,0:0.7})
lr.fit(X_train, y_train)
lrLogisticRegression(C=1000.0, class_weight={0: 0.7, 1: 0.3}, dual=False,
fit_intercept=True, intercept_scaling=1, max_iter=100,
multi_class='ovr', n_jobs=1, penalty='l2', random_state=0,
solver='liblinear', tol=0.0001, verbose=0, warm_start=False)
y_pred_lr=lr.predict(X_test)
print('錯誤分類數: %d' % (y_test != y_pred_lr).sum())
print '訓練集準確度:%f'%lr.score(X_test,y_test)錯誤分類數: 2169
訓練集準確度:0.933456
from sklearn.metrics import confusion_matrix
cnf_matrix_lr=confusion_matrix(y_test, y_pred_lr)
cnf_matrix_lrarray([[30410, 14],
[ 2155, 16]])
練習6:特徵選擇、重新建模
嘗試對不同特徵的重要度進行排序,通過特徵選擇的方式,對特徵進行篩選。並重新建模,觀察此時的模型準確率等評估指標。
用隨機森林的方法進行特徵篩選
from sklearn.ensemble import RandomForestClassifier
feat_labels = data.columns[1:]
forest=RandomForestClassifier(n_estimators=10000,random_state=0,n_jobs=-1)
forest.fit(X_train,y_train)
importances=forest.feature_importances_import numpy as np
feat_labels=data.columns[1:]
indices=np.argsort(importances)[::-1]
for f in range(X_train.shape[1]):
print '%2d) %-*s %f'%(f,30,feat_labels[indices[f]],importances[indices[f]]) 0) NumberOfDependents 0.188808
1) NumberOfTime60-89DaysPastDueNotWorse 0.173198
2) NumberRealEstateLoansOrLines 0.165334
3) NumberOfTimes90DaysLate 0.122311
4) NumberOfOpenCreditLinesAndLoans 0.089278
5) MonthlyIncome 0.087939
6) DebtRatio 0.051493
7) NumberOfTime30-59DaysPastDueNotWorse 0.045888
8) age 0.043824
9) RevolvingUtilizationOfUnsecuredLines 0.031928
選取4個特徵,建立邏輯迴歸模型
X_train_4feat=X_train_std[['NumberOfDependents','NumberOfTime60-89DaysPastDueNotWorse','NumberRealEstateLoansOrLines','NumberOfTimes90DaysLate']]
X_test_4feat=X_test_std[['NumberOfDependents','NumberOfTime60-89DaysPastDueNotWorse','NumberRealEstateLoansOrLines','NumberOfTimes90DaysLate']]from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(penalty='l1',C=1000.0, random_state=0)
lr.fit(X_train_4feat, y_train)
lrLogisticRegression(C=1000.0, class_weight=None, dual=False,
fit_intercept=True, intercept_scaling=1, max_iter=100,
multi_class='ovr', n_jobs=1, penalty='l1', random_state=0,
solver='liblinear', tol=0.0001, verbose=0, warm_start=False)
print '訓練集準確度:%f'%lr.score(X_train_4feat,y_train)訓練集準確度:0.933086
y_pred_lr=lr.predict(X_test_4feat)
print('錯誤分類數: %d' % (y_test != y_pred_lr).sum())
print '測試集準確度:%f'%lr.score(X_test_4feat,y_test)錯誤分類數: 2161
測試集準確度:0.933701
cnf_matrix_lr=confusion_matrix(y_test, y_pred_lr)
cnf_matrix_lrarray([[30381, 43],
[ 2118, 53]])
從最後的結果看,雖然經過特徵選擇和模型引數調整,但依然未能解決混淆矩陣指標太差的問題。