
DrElephant編譯安裝配置
Dr.ElePhant編譯安裝與配置
一、Dr.Elephant介紹
1.1 概念背景

Dr.Elephant被定位成一個對Hadoop和Spark任務進行效能監控和調優的工具,它能夠自動收集Hadoop平臺所有的度量標準,並對收集的資料進行分析,並將分析結果以一種簡單且易於理解的形式展示出來。Dr.Elephant的設計目的是通過它對任務的分析結果指導Hadoop/Spark開發者對其任務進行便捷的優化,從而提高開發者的效率以及 Hadoop叢集的使用效率。
在Dr.Elephant中定義了一系列的啟發式演算法(Heuristics), 這些演算法提供了對Hadoop/Spark任務進行效能分析的功能,這些啟發式演算法都是基於一定的Hadoop/Spark任務調優規則而設計的,而且這些啟發式演算法被設計成外掛式的、可配置的,我們可以很方便的在Dr.Elephant中新增自定義的啟發式演算法。通過對任務進行分析,啟發式演算法會給我們一些優化建議,基於此,我們可以對任務進行調優,從而使任務的執行更加高效。
1.2 為什麼要使用Dr.Elephant
針對Hadoop平臺優化的工具有很多,有開源的也有收費的工具。但是,大部分工具的用途是簡化Hadoop叢集的部署和管理,很少有工具能幫助Hadoop開發者優化他們的任務流程。雖然有一些可用的工具是面向這個領域的,但是,他們要不就是不夠受使用者歡迎,要不就是在擴充套件性上做的不好,不能很好的支援快速發展的Hadoop框架。Dr.Elephant能夠支援Hadoop平臺的各種框架,而且對於新框架也有很好的擴充套件性。比如最近比較火的Spark框架,Dr.Elephant能很好的支援它,這是Dr.Elephant具有高擴充套件性的體現,對於任何新的Hadoop框架,我們可以配置和使用自定義的啟發式演算法,從而對新框架的效能進行分析。Dr.Elephant的強大功能能幫助Hadoop/Spark使用者理解他們任務流的內部機制,從而幫助他們輕鬆的優化這些任務。
1.3 核心功能點
- 啟發式演算法是基於規則的,且是外掛式、可配置的,具有良好擴充套件性,能分析各種各樣的框架
- 創造性的和Azkaban排程器整合,並且支援任意一種Hadoop任務排程器,例如Oozie
- 能自動統計所有歷史任務的效能
- 能實現Job級別的任務流效能比較
- 對Hadoop和Spark任務能進行效能診斷
- 具有良好的擴充套件性,能支援新種類的任務、應用和排程器
- 提供REST API,使用者能夠通過API獲取所有資訊
1.4 Dr.Elephant工作原理
Dr.Elephant定期從Hadoop平臺的YARN資源管理中心獲取近期所有的任務,這些任務既包含成功的任務,也包含哪些失敗的任務。每個任務的元資料,例如任務計數器、配置資訊以及執行資訊都可以從Hadoop平臺的歷史任務服務端獲取到。一旦獲取到了任務的元資料,Dr.Elephant就基於這些元資料執行啟發式演算法,然後會產生一份該啟發式演算法對該任務效能的診斷報告。根據每個任務的執行情況,這份報告會為該任務標記一個待優化的嚴重性級別。嚴重性級別一共分為五級,報告會對該任務產生一個級別的定位,並通過級別來表明該任務中存在的效能問題的嚴重程度。
1.5 Dr.Elephant的一個應用場景
在LinkedIn,Hadoop平臺的開發者使用Dr.Elephant來做很多事 情。比如,監控每個任務在叢集上效能,或者用來分析理解為什麼某個任務執行效能較差以及怎麼樣去優化它們,還可以用來比較任務的多次執行情況等等。在 LinkedIn,Dr.Elephant已經成為一個標準,只有被Dr.Elephant檢查合格的任務才可以放到生產環境上執行。
1.6 任務優化分析示例
在Dr.Elephant的UI上,包含了近期所有的任務,以及這些任務的分析資料。
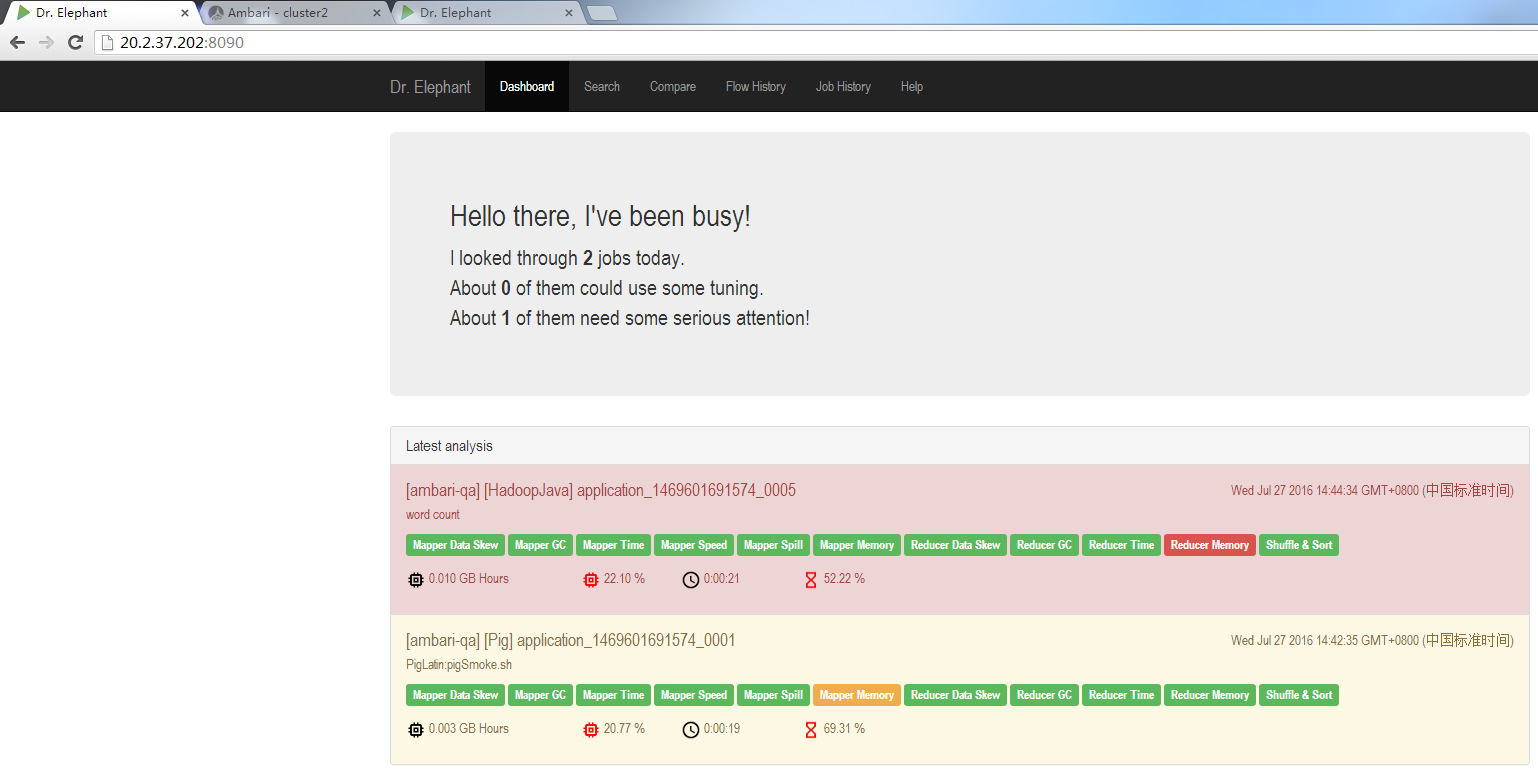
一旦一個任務執行完成,Dr.Elephant就會將它的分析資訊載入到UI中。使用者也 可以在UI的搜尋頁來搜尋某個任務。搜尋任務時,可以通過job id、任務的執行url(當用任務排程器排程任務時,是可以獲取到執行url的)、任務的發起者、任務的結束時間、任務型別來進行任務搜尋,甚至可以通過 任務分析報告中的等級來進行任務搜尋。
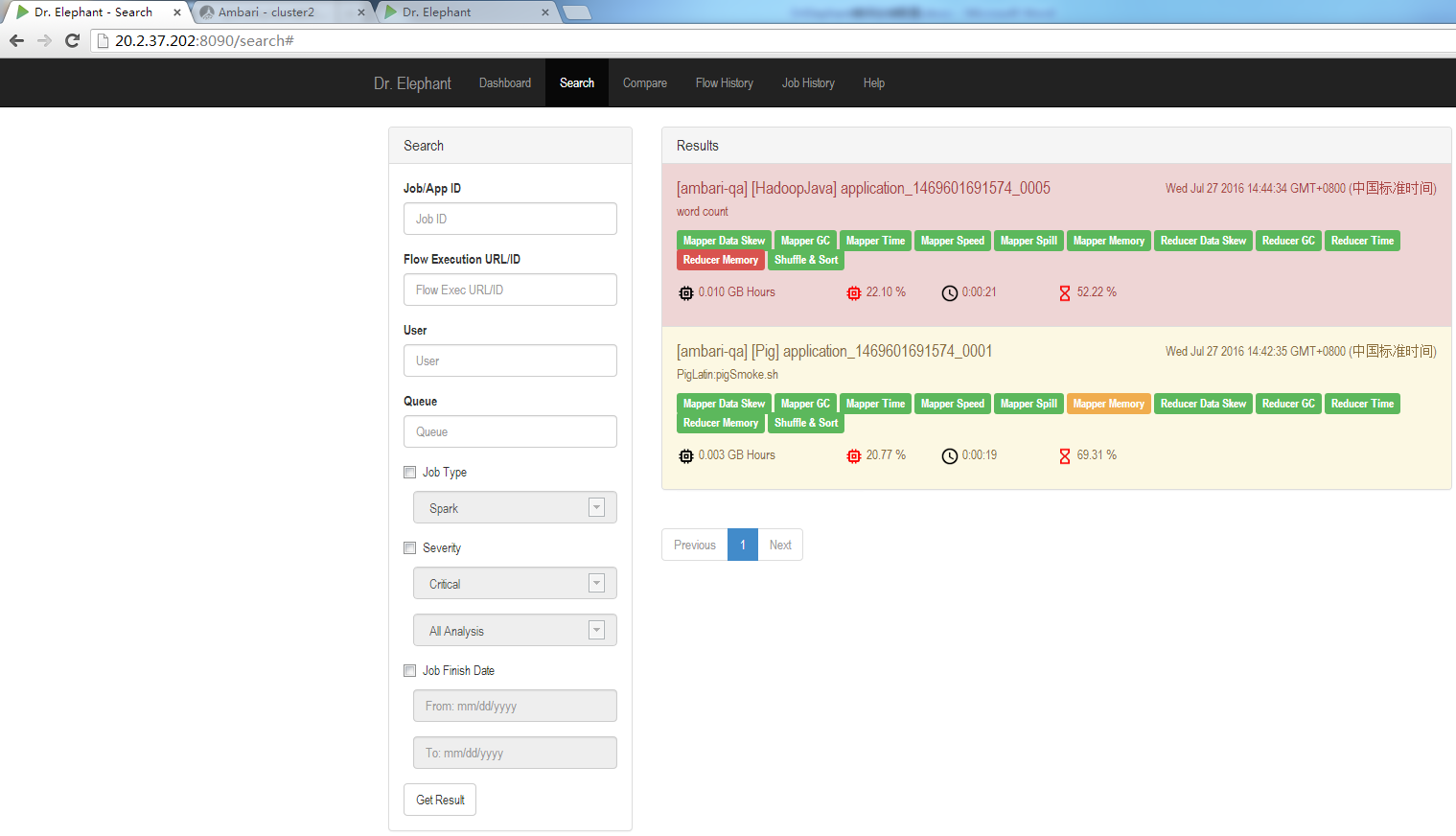
搜尋頁中展示的搜尋結果從高層面對任務的效能進行分析,通過使用不同的顏色代表不同的嚴重性等級,來表示任務和啟發式演算法的綜合情況。當UI中某個任務的顏色標記為紅色時,表明這個任務的效能問題很嚴重,亟待優化;當任務的顏色標記為綠色時,表明這個任務的執行效率很高。
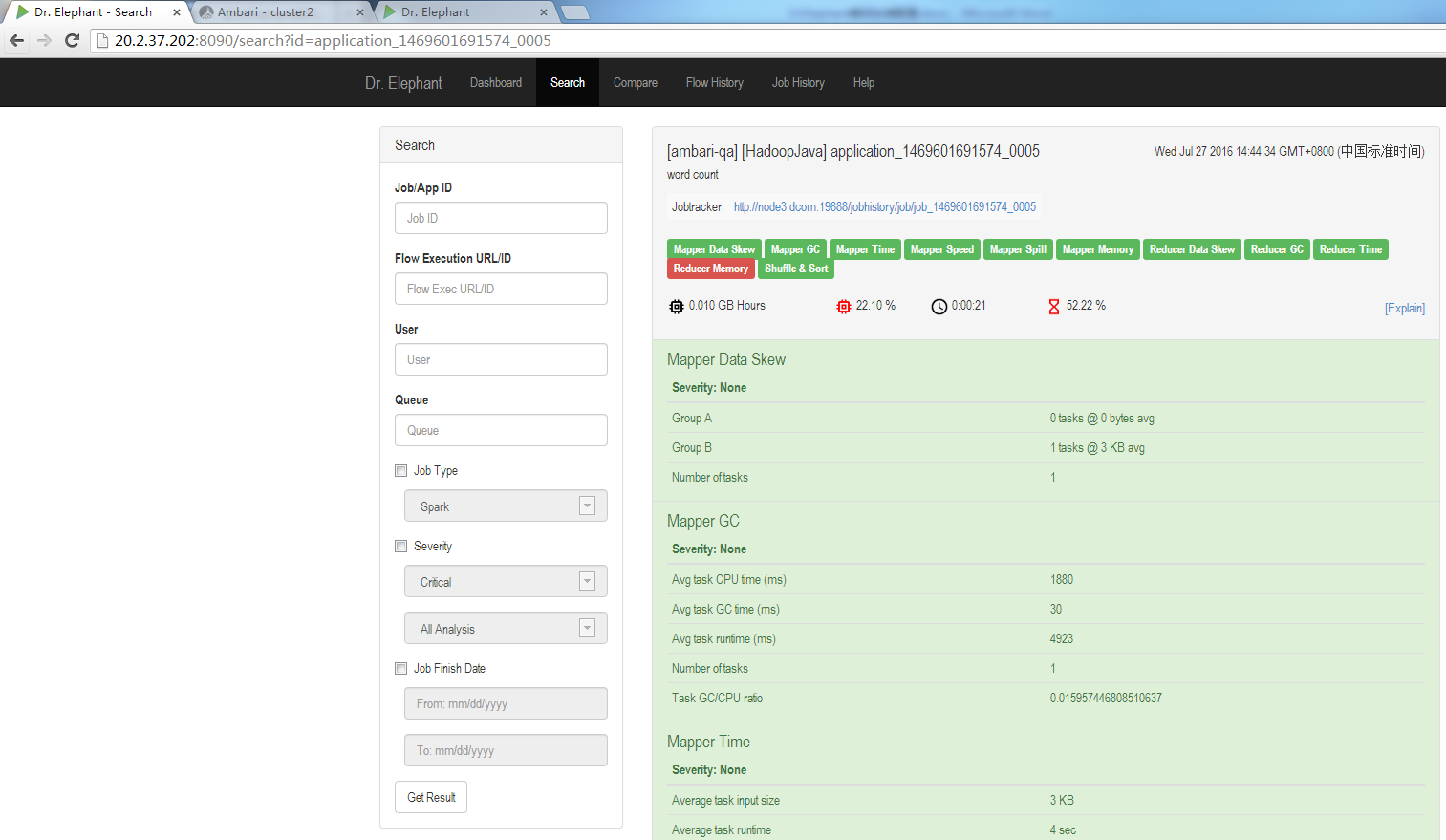
在UI中點選每個任務塊,可以得到每個任務的完整診斷報告。在診斷報告中,每個啟發式演算法都會對該任務生成一個詳細的分析。點選每個連結可以看到每個啟發式演算法對應的分析結果,這個結果提供了針對該任務在該啟發式演算法上的優化建議。
二、建立Dr.Elephant專案
2.1 獲取原始碼
從Github倉庫中獲取程式碼,dr-elephant。下文中的版本2.0.4是很早的版本,是在本地環境中測試驗證通過的版本,github上已經找不到了,本地有儲存。其他版本在編譯和部署過程中都有問題。
2.2編譯程式碼
Dr.Elephant專案基於Play框架開發,所以開發Dr.Elephant專案的第一步就是安裝Play框架。可以在下面這個連結下載到最新版本的Play框架:https://www.playframework.com/download。安裝Play框架之後,一定要將play命令新增到環境變數$PATH中。我們這裡下載的是play-2.2.6
|
export PATH=/root/play-2.2.6/:$PATH |
執行編譯指令碼,就可以對Dr.Elephant專案進行編譯。
編譯正確執行完過後會在/dist目錄下生成一個zip包,該zip檔案就是最終輸出檔案,解壓即可使用。
在執行編譯命令時,可以選擇帶一個引數選項來指明編譯的配置檔案。在這個配置檔案中,可以指定Hadoop或者Spark的版本資訊。在不指定的情況下,預設的配置是Hadoop2.3.0以及Spark1.4.0 。在配置檔案中除了可以指定以上兩個版本資訊外,還可以通過play_opts引數來指定play/sbt的選項。
|
$> ./compile.sh [./app-conf/compile.conf] $> cat compile.conf hadoop_version = 2.3.0 // The Hadoop version to compile with spark_version = 1.4.0 // The Spark version to compile with play_opts="-Dsbt.repository.config=app-conf/resolver.conf" // Other play/sbt options |
我們環境下的具體配置檔案內容為:
|
[[email protected] dr-elephant-2.0.4]# cat app-conf/compile.conf hadoop_version=2.7.1 spark_version=1.6.1 play_opts="-Dsbt.repository.config=app-conf/resolver.conf" |
resolver.conf是play中sbt和mvn解析獲取倉庫地址的配置檔案,我們環境下配置為:
|
[[email protected] dr-elephant-2.0.4]# cat app-conf/resolver.conf [repositories] local #maven2: http://repo.maven.apache.org/maven2 #maven2-ivy: http://repo.maven.apache.org/maven2, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext] #activator-launcher-local: file:////${activator.local.repository-${activator.home-${user.home}/.activator}/repository}, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext] #osc: http://maven.oschina.net/content/groups/public/ #activator-local: file:////${activator.local.repository-E:/development/Tools/typesafe-activator-1.3.9/activator-dist-1.3.9//repository}, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext] #maven-central #typesafe-releases: http://repo.typesafe.com/typesafe/releases #typesafe-ivy-releasez: http://repo.typesafe.com/typesafe/ivy-releases, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext] |
這樣配置的話,編譯過程中resolve完ivy.xml檔案後,會提示我們在local目錄下沒有對應的jar包,我們可以手動去下載然後按照對應名稱放到對應目錄下(註釋部分讓裝置自己去下的話可能太耽誤時間,另外裝置不一定能連線外網)
以上的三個引數如果沒有通過配置檔案指定,預設就會使用上面列舉出的預設值。如果想指定一個固定的倉庫,可以通過設定sbt.repository.config 為resolver檔案的位置來實現,如上面所示即可。
2.3啟動單元測試
呼叫編譯指令碼,就會執行所有的單元測試程式。
2.3.1本地部署測試Dr.Elephant
(1)Yarn和Hadoop/Spark
在本地部署Dr.Elephant之前,先要在本地安裝Hadoop和 Spark(Yarn模式),而且要確保資源管理器(Resource Manager)和歷史任務服務(Job History Service)程式的正確執行。關於Yarn上MapReduce任務的偽分散式模式可以參考偽分散式部署。
指定環境變數HADOOP_HOME:
|
$>export HADOOP_HOME=/path/to/hadoop/home $>export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop |
將Hadoop的Home目錄新增到系統環境變數,Dr.Elephant會使用到Hadoop的Classpath中的某些Class檔案。
|
$>export PATH=$HADOOP_HOME/bin:$PATH |
(2)資料庫
Dr.Elephant需要將任務資訊和任務的診斷資訊儲存在本地資料庫MySQL中。
在本地安裝啟動MySQL。可以在這個連結下載到最新版本的MySQL:https://www.mysql.com/downloads/ 。Dr.Elephant目前只支援MySQL5.5以上的版本。在MySQL中建立一個數據庫,名稱為drelephant,有關於資料庫的配置可檢視和修改app-conf目錄下的elephant.conf檔案
具體配置:
DrElephant配置mysql資料庫
|
[[email protected] dr-elephant-2.0.4]# systemctl start mariadb.service [[email protected] dr-elephant-2.0.4]# systemctl status mariadb.service ● mariadb.service - MariaDB database server Loaded: loaded (/usr/lib/systemd/system/mariadb.service; disabled; vendor preset: disabled) Active: active (running) since Wed 2016-07-27 11:08:32 CST; 10s ago Process: 20074 ExecStartPost=/usr/libexec/mariadb-wait-ready $MAINPID (code=exited, status=0/SUCCESS) Process: 19986 ExecStartPre=/usr/libexec/mariadb-prepare-db-dir %n (code=exited, status=0/SUCCESS) Main PID: 20073 (mysqld_safe) CGroup: /system.slice/mariadb.service ├─20073 /bin/sh /usr/bin/mysqld_safe --basedir=/usr └─20230 /usr/libexec/mysqld --basedir=/usr --datadir=/var/lib/mysql --plugin-dir=/usr/lib64/mysql/plugin --log-error=/var/log/mariadb/mariadb.log ... Jul 27 11:08:29 node2.dcom mariadb-prepare-db-dir[19986]: The latest information about MariaDB is available at http://mariadb.org/. Jul 27 11:08:29 node2.dcom mariadb-prepare-db-dir[19986]: You can find additional information about the MySQL part at: Jul 27 11:08:29 node2.dcom mariadb-prepare-db-dir[19986]: http://dev.mysql.com Jul 27 11:08:29 node2.dcom mariadb-prepare-db-dir[19986]: Support MariaDB development by buying support/new features from MariaDB Jul 27 11:08:29 node2.dcom mariadb-prepare-db-dir[19986]: Corporation Ab. You can contact us about this at [email protected] Jul 27 11:08:29 node2.dcom mariadb-prepare-db-dir[19986]: Alternatively consider joining our community based development effort: Jul 27 11:08:29 node2.dcom mariadb-prepare-db-dir[19986]: http://mariadb.com/kb/en/contributing-to-the-mariadb-project/ Jul 27 11:08:29 node2.dcom mysqld_safe[20073]: 160727 11:08:29 mysqld_safe Logging to '/var/log/mariadb/mariadb.log'. Jul 27 11:08:29 node2.dcom mysqld_safe[20073]: 160727 11:08:29 mysqld_safe Starting mysqld daemon with databases from /var/lib/mysql Jul 27 11:08:32 node2.dcom systemd[1]: Started MariaDB database server. [[email protected] dr-elephant-2.0.4]# mysql -u root //這裡是之前配置過無密碼登陸的 Welcome to the MariaDB monitor. Commands end with ; or \g. Your MariaDB connection id is 3 Server version: 5.5.44-MariaDB MariaDB Server Copyright (c) 2000, 2015, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MariaDB [(none)]> -> \h General information about MariaDB can be found at http://mariadb.org List of all MySQL commands: Note that all text commands must be first on line and end with ';' ? (\?) Synonym for `help'. clear (\c) Clear the current input statement. connect (\r) Reconnect to the server. Optional arguments are db and host. delimiter (\d) Set statement delimiter. edit (\e) Edit command with $EDITOR. ego (\G) Send command to mysql server, display result vertically. exit (\q) Exit mysql. Same as quit. go (\g) Send command to mysql server. help (\h) Display this help. nopager (\n) Disable pager, print to stdout. notee (\t) Don't write into outfile. pager (\P) Set PAGER [to_pager]. Print the query results via PAGER. print (\p) Print current command. prompt (\R) Change your mysql prompt. quit (\q) Quit mysql. rehash (\#) Rebuild completion hash. source (\.) Execute an SQL script file. Takes a file name as an argument. status (\s) Get status information from the server. system (\!) Execute a system shell command. tee (\T) Set outfile [to_outfile]. Append everything into given outfile. use (\u) Use another database. Takes database name as argument. charset (\C) Switch to another charset. Might be needed for processing binlog with multi-byte charsets. warnings (\W) Show warnings after every statement. nowarning (\w) Don't show warnings after every statement. For server side help, type 'help contents' MariaDB [(none)]> create database drelephant; Query OK, 1 row affected (0.01 sec) MariaDB [(none)]> print; -------------- -------------- unknown [elephant]> connect drelephant; Connection id: 5 Current database: drelephant MariaDB [drelephant]> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | drelephant | | mysql | | performance_schema | | test | +--------------------+ 5 rows in set (0.00 sec) MariaDB [drelephant]> use drelephant; Database changed MariaDB [drelephant]> show tables; +-----------------------------------+ | Tables_in_drelephant | +-----------------------------------+ | play_evolutions | | yarn_app_heuristic_result | //出現這些個表格說明drelephant安裝配置成功了 | yarn_app_heuristic_result_details | | yarn_app_result | +-----------------------------------+ 4 rows in set (0.00 sec) MariaDB [drelephant]> |
在Dr.Elephant的配置檔案app-conf/elephant.conf中可以配置資料庫的url、資料庫名稱、使用者名稱稱和密碼。
(3)使用其他資料庫
目前,Dr.Elephant預設是用MySQL資料庫。我們可以在演化檔案(evolution files)中看到MySQL的DDL宣告。如果我們希望能夠使用其他的資料庫,可以參考https://www.playframework.com/documentation/2.6.x/ScalaDatabase進行配置。
2.3.2本地安裝Dr.Elephant
完成上面的安裝前準備之後,可以開始在本地安裝Dr.Elephant。
執行Hadoop,並執行Hadoop歷史任務服務。
|
$> $HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver |
編譯Dr.Elephant專案,生成分散式部署的包。進入專案中的dist資料夾,這個資料夾包含了需要進行分散式部署的zip包。使用unzip命令將zip包解包,然後修改dr-elephant的釋出目錄。以後的描述中,我們都用DR_RELEASE來表示dr-elephant的釋出目錄。
|
$>cd dist; unzip dr-elephant*.zip;cd dr-elephant* |
建立完資料庫之後,首次執行Dr.Elephant時,需要啟動演化功能 (evolution)。啟動演化功能時,可以在elephant.conf配置檔案中引數jvm_props新增(或者將對jvm_props的註釋符去掉)-Devolutionplugin=enable -DapplyEvolutions.default=true。
|
$> vim ./app-conf/elephant.conf jvm_props=" -Devolutionplugin=enabled -DapplyEvolutions.default=true" |
啟動Dr.Elephant時,執行start.sh指令碼,並在引數中帶上應用程式的配置檔案目錄。
|
$> $DR_RELEASE/bin/start.sh $DR_RELEASE/../../app-conf |
如果需要停止Dr.Elephant,執行:
|
$> $DR_RELEASE/bin/stop.sh |
當Dr.Elephant執行成功之後,可以通過”ip:port”(localhost:8080)在瀏覽器中開啟UI。Port的值可以在app-conf目錄下的elephant.conf檔案中修改(因為ambari-server的port也是8080):
|
[[email protected] dr-elephant-2.0.4]# cat app-conf/elephant.conf # Play application server port port=8090 |
Dr.Elephant的日誌預設輸出到logs目錄下的application.log檔案中
2.4專案結構
|
app → Contains all the source files └ com.linkedin.drelepahnt → Application Daemons └ org.apache.spark → Spark Support └ controllers → Controller logic └ models → Includes models that Map to DB └ views → Page templates app-conf → Application Configurations └ elephant.conf → Port, DB, Keytab and other JVM Configurations (Overrides application.conf) └ FetcherConf.xml → Fetcher Configurations └ HeuristicConf.xml → Heuristic Configurations └ JobTypeConf.xml → JobType Configurations conf → Configurations files └ evolutions → DB Schema └ application.conf → Main configuration file └ log4j.properties → log configuration file └ routes → Routes definition images └ wiki → Contains the images used in the wiki documentation public → Public assets └ assets → Library files └ css → CSS files └ images → Image files └ js → JavaScript files scripts └ start.sh → Starts Dr. Elephant └ stop.sh → Stops Dr. Elephant test → Source folder for unit tests compile.sh → Compiles the application |
2.5 啟發式演算法
針對MapReduce和Spark,Dr.Elephant已經實現了一系列的啟發式演算法。如果想對啟發式演算法進行更深入的瞭解,請閱讀“啟發式演算法指南”部分。所有的啟發式演算法都是外掛式的,可以簡單的配置使用。
2.5.1 新增新的啟發式演算法
我們可以按照下面的步驟去新增自定義的啟發式演算法,並把它新增到Dr.Elephant中。
- 建立新的啟發式演算法,並完成測試。
- 為該啟發式演算法建立一個新的view頁,例如helpMapperSpill.scala.html。
- 在HeuristicConf.xml檔案中新增該啟發式演算法的詳情。
- HeuristicConf.xml檔案中啟發式演算法的詳情包含以下內容:
i. 應用程式型別:是mapreduce程式還是spark程式。
ii. 啟發式演算法名稱。
iii. 類名稱:類名的全稱。
iv. view頁的名稱
v. 該啟發式演算法適用的Hadoop版本號
5. 啟動Dr.Elephant,就包含了新的啟發式演算法
HeuristicConf.xm檔案示例:
|
<heuristic> <applicationtype>mapreduce</applicationtype> <heuristicname>Mapper GC</heuristicname> <classname>com.linkedin.drelephant.mapreduce.heuristics.MapperGCHeuristic</classname> <viewname>views.html.help.mapreduce.helpGC</viewname> </heuristic> |
2.5.2 配置啟發式演算法
每個啟發式演算法都有一些閾值,用來計算不同的待優化等級。我們可以在HeuristicConf.xml檔案中指定這些閾值。
下面給出一個例子,介紹如何指定啟發式演算法的閾值:
|
<heuristic> <applicationtype>mapreduce</applicationtype> <heuristicname>Mapper Data Skew</heuristicname> <classname>com.linkedin.drelephant.mapreduce.heuristics.MapperDataSkewHeuristic</classname> <viewname>views.html.help.mapreduce.helpMapperDataSkew</viewname> <params> <num_tasks_severity>10, 50, 100, 200</num_tasks_severity> <deviation_severity>2, 4, 8, 16</deviation_severity> <files_severity>1/8, 1/4, 1/2, 1</files_severity> </params> </heuristic> |
2.6 分數計算
在Dr.Elephant中,使用啟發式演算法來分析執行完成的任務,會得到一個分數。這個分數的計算方法比較簡單,可以通過將待優化等級的值乘以作業(task)數量。
|
int score =0; if (severity != Severity.NONE&& severity!= Severity.LOW) { score = severity.getValue()* tasks; } return score; |
Dr.Elephant可以計算不同任務型別的得分:
作業分數:所有作業的待優化等級數值之和
任務分數:該任務中所有的作業分數之和
任務流分數:該任務流中所有的任務分數之和
三、參考資料
相關推薦
DrElephant編譯安裝配置
Dr.ElePhant編譯安裝與配置 一、Dr.Elephant介紹 1.1 概念背景 Dr.Elephant被定位成一個對Hadoop和Spark任務進行效能監控和調優的工具,它能夠自動收集Hadoop平臺所有的度量標準,並對收集的資料進行分析,並將分析結果以一種簡單
httpd/apache編譯安裝配置詳解
apachectl 訪問 這一 block combined enable config yum 開發環境 一.httpd介紹 1.httpd是http協議的一個經典實現,也是apache組織中的一個頂級項目,其官方站點為httpd.apache.org。 2.httpd的
OpenCV編譯安裝配置總結
Linux Compilation and Installation Dependencies CMake Make Make Install
linux下編譯安裝配置php5.6.30過程
在第一次編譯安裝php5.6.30失敗後,參考了http://www.phpworld.cn/system/php/11.html的一些內容,第二次編譯安裝成功,特此記錄過程。 一、編譯安裝php5.6.30 安裝環境: # cat /etc/redhat-release CentOS
vsftpd-3.0.2原始碼編譯安裝配置指南
首先,下載vsftpd-3.0.2原始碼包. 詳細的安裝過程如下: [[email protected] vsftpd-3.0.2]# tar zxvf vsftpd-3.0.2.tar.gz [[email protected] vsftpd-
linux編譯安裝mssql客戶端和配置php連接mssql
linux 客戶端 凡是連接數據庫,必須安裝客戶端,我一般寫博客都不寫原理,但是後來發現回頭看自己寫的自己都看不懂,所以這章博客會多一點原理性的東西。數據庫的連接一般都是在客戶端上完成的,MySQL也不例外,安裝mysql時一般都會這麽安裝:#yum install mysql mysql-serve
配置網絡YUM源和第三方YUM源及編譯安裝Apache
yum ftp repo httpd 編譯安裝 配置網絡YUM源和第三方YUM源及編譯安裝Apache系統軟硬件環境平臺:VMware Workstation Pro 12.5.5 build-5234757CentOS Linux release 7.3.1611內核版本:3.10.0-
Sublime Text3 & MinGW & LLVM CLang 安裝配置C-C++編譯環境
his c/c++ 而已 rtl sha2 9.png 大寫 utf8 實的 Sublime Text是一款強大的跨平臺代碼編輯器,小巧而且豐富實用的功能是Visual Studio不能比擬的,但是編譯運行是一個軟肋,本文通過在sublime中配置g++編譯器實現程序的編譯
Linux 下編譯並安裝配置 Qt 4.53全過程
雙擊 win port 環境 簡單的 類型 http you ner 最近準備做 Nokia 的 Symbian,Maemo 下觸摸屏開發。考慮到程序的跨平臺可移植性,最終選擇使用 Qt 開發。相對來說,國內關於 Qt 相關文檔並不算很多。作者將 Linux
《net-snmp-5.7.3配置編譯安裝》
設置 bus 重命名 tree control examples password 取消 mark 先看一下系統環境 [email protected]pc:~/work/_snmp/net-snmp-5.7.3$ uname -a Linux o-pc 3.16
centos6.8服務器配置之編譯安裝PHP、配置nginx
功能 配置說明 函數 true option pcre c語言 php.ini get php version 5.6.31、nginx version: nginx/1.10.2 1、下載: wget http://cn2.php.net/distribution
Qt Creator的安裝與Qt交叉編譯的配置
wid 設置 sem arm pad name 生成 art file Qt Creator 的安裝 到Qt官網下載Qt Creator https://www.qt.io/download-open-source/ 其它舊版本點擊Achieve連接下載 或登錄h
CentOS7 編譯安裝nodejs,配置環境變量記錄
ever lis detail 遇到 ++ help 設置 代碼 contains 每次都裝,每次都查 阿裏雲備案了一個域名,續費了好多年,但是沒錢買服務器,就掛在github上。今天收到消息:域名解析服務器不在阿裏雲,要被GG。只能咬牙買了個阿裏雲乞丐版。 所有服務都裝
RedHat 7 編譯安裝Nginx 1.12並配置WEB站點
nginx WEB 一、安裝環境1、操作系統版本:Red Hat Enterprise Linux Server release 7.2 (Maipo)2、Nginx版本:nginx-1.12.2.tar.gz3、pcre版本:pcre-8.42.tar.gz4、zlib版本:zlib-1.2.11.
centos 7 編譯安裝以及配置rsync+inotify 文件實時同步操作記錄
註意 .com 操作記錄 修改 pid 指定 服務 entos 實時同步 準備工作: 服務器A 源文件服務器 服務器B 數據備份服務器 註意:服務器A修改文件 實時同步到 服務器B, 服務器A和B都需要安裝rsync,並且服務器A還需要安裝inotify 一、 安裝rs
nginx源碼編譯安裝及配置文件說明
nginx源碼安裝nginx源碼編譯安裝 安裝nginx的依賴包(pcre-devel openssl-devel) [root@anuo ~]# yum install pcre-devel openssl-devel -y 創建管理用戶 nginx [root@anuo ~]# useradd -s /s
編譯安裝Apache HTTP Server 2.4.23 以及配置HTTP/HTTPS反向代理
chan .so har 替換 quest pre and for 大小 編譯安裝Apache HTTP Server 2.4.23以及配置HTTP/HTTPS反向代理一,依賴軟件: 1.1 GCC和C++編譯器 GCC C++ Compiler 1.1.1 如果沒有安
ansible 自動化編譯安裝nginx服務、管理配置文件
lease root 嚴格 f2c 重啟 handlers nginx fig items 圖解: 說明: 系統版本:CentOS Linux release 7.4.1708 (Core) 需要先在一臺機上先裝好nginx,再配置ansible服務 1、將替換的文件放入
Apache二進制免編譯安裝和參數配置
code 參數 icons -c oba accept https 9.png main 下載http相關二進制軟件包 cd /usr/local/src/ wget http://mirrors.cnnic.cn/apache/httpd/httpd-2.4.34.tar
http協議--Apache-Httpd服務基本配置-rpm安裝-編譯安裝(HTTP2.2,HTTP2.4)
超文本標記語言 cookie信息 multiview 異步 表達 tp服務器 The 計算 改變 socket: OSI七層: 上三層:用戶空間 下四層:通信子網,內核空間 ip:主機到主機通信 M