
Redis叢集的節點通訊原理
Redis叢集搭建中,資料如何在節點分佈的原理,下面來介紹一下節點之間是如何進行通訊(節點握手)
在分散式儲存中需要提供維護節點元資料資訊的機制,所謂元資料是指:節點負責哪些資料,是否出現故障等狀態資訊。常見的元資料維護方式分為:集中式和P2P方式。Redis叢集採用P2P的Gossip(流言)協議,Gossip協議工作原理就是節點彼此不斷通訊交換資訊,一段時間後所有的節點都會知道叢集完整的資訊,這種方式類似流言傳播
節點之間通訊示意圖
叢集中的每個節點都會單獨開闢一個TCP通道,用於節點之間彼此通訊,通訊埠號在基礎埠上加10000
每個節點在固定週期內通過特定規則選擇幾個節點發送ping訊息
接收到ping訊息的節點用pong訊息作為響應
叢集中每個節點通過一定規則挑選要通訊的節點,每個節點可能知道全部節點,也可能僅知道部分節點,只要這些節點彼此可以正常通訊,最終它們會達到一致的狀態。當節點出故障、新節點加入、主從角色變化、槽資訊變更等事件發生時,通過不斷的ping/pong訊息通訊,經過一段時間後所有的節點都會知道整個叢集全部節點的最新狀態,從而達到叢集狀態同步的目的。
Gossip訊息
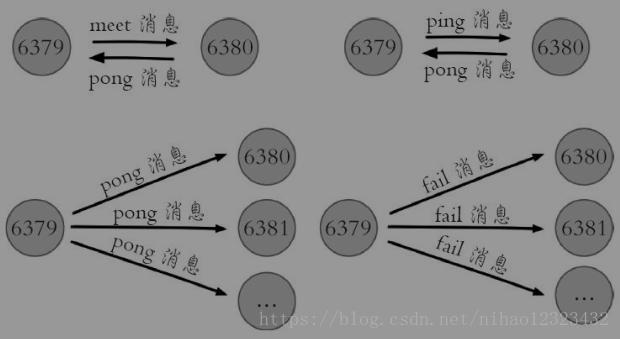
Gossip協議的主要職責就是資訊交換。資訊交換的載體就是節點彼此傳送的Gossip訊息,常用的Gossip訊息可分為:ping訊息、pong訊息、meet訊息、fail訊息
meet訊息:用於通知新節點加入。訊息傳送者通知接收者加入到當前叢集,meet訊息通訊正常完成後,接收節點會加入到叢集中並進行週期性的ping、pong訊息交換
ping訊息:叢集內交換最頻繁的訊息,叢集內每個節點每秒向多個其他節點發送ping訊息,用於檢測節點是否線上和交換彼此狀態資訊。ping訊息傳送封裝了自身節點和部分其他節點的狀態資料
pong訊息:當接收到ping、meet訊息時,作為響應訊息回覆給傳送方確認訊息正常通訊。pong訊息內部封裝了自身狀態資料。節點也可以向叢集內廣播自身的pong訊息來通知整個叢集對自身狀態進行更新
fail訊息:當節點判定叢集內另一個節點下線時,會向叢集內廣播一個fail訊息,其他節點接收到fail訊息之後把對應節點更新為下線狀態
接收節點會解析訊息內容並根據自身的識別情況做出相應處理,對應流程

解析訊息頭過程:訊息頭包含了傳送節點的資訊,如果傳送節點是新節點且訊息是meet型別,則加入到本地節點列表;如果是已知節點,則嘗試更新發送節點的狀態,如槽對映關係、主從角色等狀態
解析訊息體過程:如果訊息體的clusterMsgDataGossip陣列包含的節點是新節點,則嘗試發起與新節點的meet握手流程;如果是已知節點,則根據cluster MsgDataGossip中的flags欄位判斷該節點是否下線,用於故障轉移
節點選擇
由於內部需要頻繁地進行節點資訊交換,而ping/pong訊息會攜帶當前節點和部分其他節點的狀態資料,勢必會加重頻寬和計算的負擔。Redis叢集內節點通訊採用固定頻率(定時任務每秒執行10次)。因此節點每次選擇需要通訊的節點列表變得非常重要。通訊節點選擇過多雖然可以做到資訊及時交換但成本過高。節點選擇過少會降低叢集內所有節點彼此資訊交換頻率,從而影響故障判定、新節點發現等需求的速度。因此Redis叢集的Gossip協議需要兼顧資訊交換實時性和成本開銷,
選擇傳送訊息的節點數量
叢集內每個節點維護定時任務預設每秒執行10次,每秒會隨機選取5個節點找出最久沒有通訊的節點發送ping訊息,用於保證Gossip資訊交換的隨機性。每100毫秒都會掃描本地節點列表,如果發現節點最近一次接受pong訊息的時間大於cluster_node_timeout/2,則立刻傳送ping訊息,防止該節點資訊太長時間未更新。根據以上規則得出每個節點每秒需要傳送ping訊息的數量=1+10*num(node.pong_received>cluster_node_timeout/2),因此cluster_node_timeout引數對訊息傳送的節點數量影響非常大。當我們的頻寬資源緊張時,可以適當調大這個引數,如從預設15秒改為30秒來降低頻寬佔用率。過度調大cluster_node_timeout會影響訊息交換的頻率從而影響故障轉移、槽資訊更新、新節點發現的速度。因此需要根據業務容忍度和資源消耗進行平衡。同時整個叢集訊息總交換量也跟節點數成正比。
訊息資料量
每個ping訊息的資料量體現在訊息頭和訊息體中,其中訊息頭主要佔用空間的欄位是myslots[CLUSTER_SLOTS/8],佔用2KB,這塊空間佔用相對固定。訊息體會攜帶一定數量的其他節點資訊用於資訊交換,訊息體攜帶資料量跟叢集的節點數息息相關,更大的叢集每次訊息通訊的成本也就更高,因此對於Redis叢集來說並不是大而全的叢集更好
