
CISCO學習筆記(七)動態路由協議-RIP
一、首先來看一下靜態路由協議個動態路由協議的區別:
靜態路由:這種路由由網路管理員手動輸入路由器命令管理。缺點:需要手工指定,網路過大無法使用。
動態路由:這種路由由網路路由協議根據拓撲或流量改變而自動調整。缺點:容易佔用網路頻寬。
當路由器數量少的時候建議使用靜態路由,當路由器數量多的時候建議使用動態路由。
二、路由協議分為兩種也叫做自治系統:
自治系統是通用管理域中的網路的集合
內部閘道器協議在自治系統中工作
外部閘道器協議連線不同的自治系統
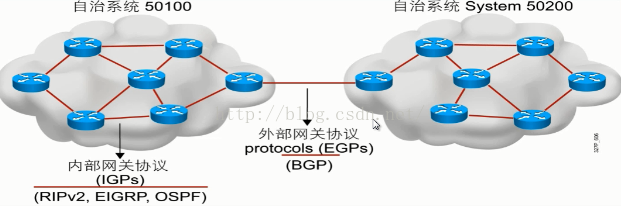
1.內部閘道器路由協議:RIP\EIGRP\OSPF
而我們通常所說的AS就是指的一組或者一片由管理員來管理的路由器。(比如上圖中的左半個區域)
2.外部閘道器路由協議:BGP
三、內部動態路由協議的型別
1.距離向量 RIP、IGRP
2.高階距離向量EIGRP(cisco私有的)
3.鏈路狀態 OSPF IS.IS
距離向量:
“距離”表示有多遠,經過幾臺路由器,經過幾跳。
“向量”表示在哪個方向上,從哪個介面轉發出去。
距離向量路由協議會隔一定時間將路由表裡的所有路由傳給自己的鄰居。週期的。
四、RIP的工作原理:
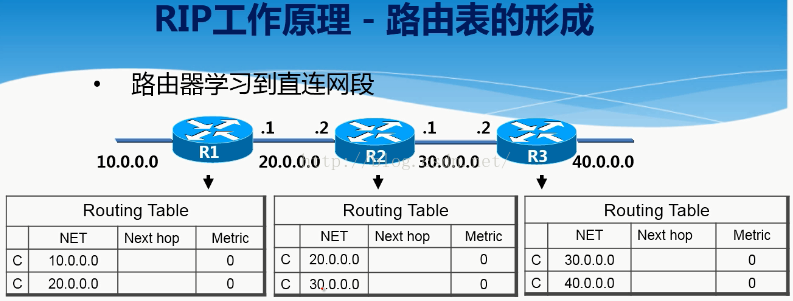
1.首先路由器會先學習到自身所在的直連網段的路由資訊。
2.當執行RIP動態路由協議的時候,路由器會每隔30秒向鄰居(指的是直接相連的路由器)傳送路由表。
但是在傳送之前,會把路由資訊的Metric值+1之後傳給鄰居。
For example:net next metric
10.0.0.0 0+1
20.0.0.0 0+1
Metric叫做度量值,是衡量一條路由好壞的一個引數。
如果是相同路由的情況下,必須要傳過來的metric值比自己的小才可以學習,否則是不學習的。比如R1傳給R2的“20.0.0.0 metric 1”的這條路由,R2自己的路由表裡面有一條20.0.0.0的路由,且metric值為0,明顯比R1傳過來的小,所以是不學習這條路由的。Metric值越小,優先順序就越高。而R1同時傳過來的10.0.0.0的路由在R2裡面是沒有的,所以它會學習過來。
那麼接下來,輪到R2傳給鄰居路由了,R1和R3會同時收到R2傳過來的路由資訊。當然傳出之前metric值還是會加1. Net next metric
C 20.0.0.0 0+1
C 30.0.0.0 0+1
R 10.0.0.0 20.0.0.1 1
那麼同樣的因為R2傳給R1的20.0.0.0的metric值是1比R1本身的20.0.0.0的metric值大,所以R1也是不學的。所以只會把自身沒有的30.0.0.0 加入到自己的路由表裡面。即:“R 30.0.0.0 20.0.0.2 1”
當R2傳給R3的時候,同樣30.0.0.0的路由不學習,而只學習“R20.0.0.0 30.0.0.0 1”這條路由。
當R3的週期更新時間到了以後,也會把自己的路由資訊metric值加1之後傳給鄰居R2。那麼R2就學到了“R 40.0.0.0 30.0.0.0 1”這條路由。
最後到下一個30秒的更新週期的時候,R1又會把自己的路由資訊傳給鄰居R2,而因為三個網段的路由資訊R2都有,且三個網段的metric值都大,分別為“1 1 2”所以R2不學,然後R2傳給R1的時候,R1就學到了“R 40.0.0.0 20.0.0.2 2”的路由。
R3也同理如此。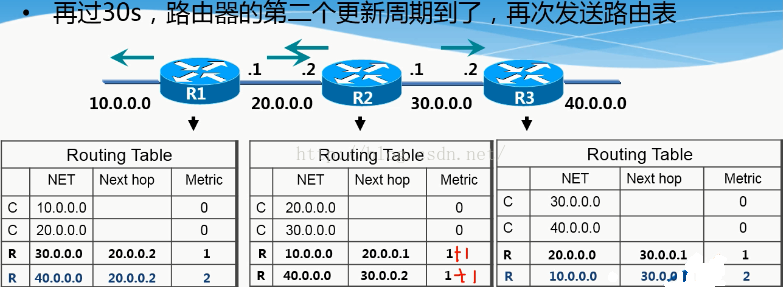
傳送路線圖:
第一個30秒:R1傳到R2
R2傳到R1、R2傳到R3
R3傳到R2
第二個30秒:R1傳到R2
R2傳到R1、R2傳到R3 到這裡三臺路由器的路由表就一樣了。
RIP路由的缺點:
1.計數至無窮大然後出現路由環路。
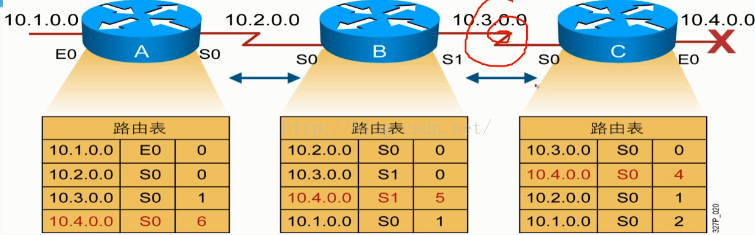
當10.4.0.0的鏈路down掉的時候,C的路由週期更新時間30秒到了,就會表示為disable。但是這個時候的B的路由週期更新時間還沒有到30秒,這個時候,B路由就會發送自己的更新路由給C,而C因為標記了disable,就沒有了10.4.0.0的這條路由資訊,所以當B傳給C的時候,它就會學到這條原本是已經down掉的路由資訊。然後當C的路由週期更新時間到的時候,就又會傳路由給B,這樣就會形成一個環路,B不停的給C傳,C又不停的給B傳,而它們的metric值因為在每次傳之前都會加1,所以會慢慢的越來越大,至無窮大。
為了解決這樣的問題:
1.設定路由的最大跳數:為路由跳數作限制。所以RIP的最大跳數是15跳,16跳就不可達了。
所以RIP路由只支援15臺路由器,超過15臺路由器,就不可用了。
(因為會在第15臺路由上的路由表的metric值標記為16,表示後續不可達。這樣就不會出現路由環路了。)
2.水平分割:從一個介面學到的路由,不會再把這條路由從這個介面轉發出去。
比如,B從C學到的路由10.4.0.0的路由是從S1口接收進來,那麼就不會再把這條路由從S1口轉發給C。
這樣也不會造成路由環路。
3.路由毒化和毒性反轉:路由器將已經斷開的路由的距離通告為無窮大。當C發現10.4.0.0的路由down了也就是中毒了,就會在自己的路由表裡面標記這條路由為infinite(無限大),然後立刻用更新包將這條標記的資訊轉發給B,B這時候就會在自己的路由表裡面也標記為is impossible down,然後會忽視水平分割,轉發給C這條標記為is possible down的路由資訊。這樣也會防止路由環路。
4.抑制計時器:路由器為網路中的“可能有故障”狀態保留條目,以便為其他路由器重新計算拓撲更改留出時間。當C發現10.4.0.0這條鏈路down掉的時候,立刻會向B傳送一條不可達的資訊,當B收到這跳資訊的時候,會開啟抑制計時器,也就是180秒,實際上也只是用到60秒,那麼在這60秒內,如果收到一條關於10.4.0.0的次優先順序的路由,那麼B是不學習的。(如果原來自己的路由表裡面10.4.0.0的metric值是3跳,而收到的關於10.4.0.0的路由metric值4跳還比自己本身的大,是不學的。如果這條新學到的關於10.4.0.0的路由的metric值是2,比自己原來的這條路由metric值3還小,那麼就會學習這條小的,而替換掉自己原來的那條路由。)那麼當然,如果在這抑制計時器的60秒,這條10.4.0.0的路由又恢復了,那麼繼續啟用這條路由。
5.觸發更新:路由表發生變化時,路由器傳送更新。預設的埠S1和S0觸發更新是開啟的,當發現10.4.0.0的這條鏈路down掉的時候,是不會等待30秒等週期更新時間的,而會立刻傳送一個更新包給B。這樣也可以有效的來抑制路由環路。
路由協議的版本:
RIP v1:
-傳送路由更新時不攜帶子網掩碼,屬於有類路由協議,不支援子網劃分。
-傳送路由更新時,目標地址為廣播地址:255.255.255.255
-在主網邊界的自動彙總是無法關閉的。
RIP v2:
-傳送路由更新是攜帶子網掩碼,屬於無類路由協議,支援子網劃分。
-傳送路由更新時,目標地址為組播地址:224.0.0.9
-可以關閉主網邊界的路由自動彙總。
RIP在主網邊界會自動彙總:
所以如果是做過子網劃分的網路在學習路由的時候,學的都是主網段路由。
比如:應該學到23.1.1.0/24的路由,到最後檢視路由表的時候卻是23.0.0.0/8主網段路由。那其實這是
彙總之後的路由。
主網邊界:分兩種情況
1.比如後邊這張圖,路由器左邊是C類地址,右邊是A類地址,那麼這個路由器就是主網邊界路由。
也就是說兩邊地址型別不一樣的主網邊界。
2.兩邊地址不連續的也是主網邊界。如圖:R2左邊的是12網段,右邊的是23網段。
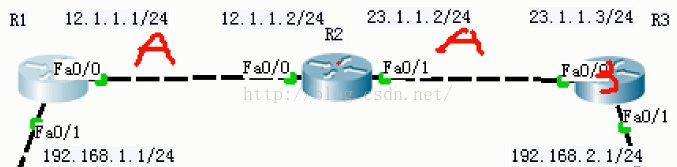
如果4個網段的IP地址都是
連續的話,那麼它是不會自動彙總的。

120就是RIP的管理距離值,而靜態路由的管理距離值是1。
跳數metric值1就是值到達23.0.0.0的網段只需用經過1跳就可以到達。
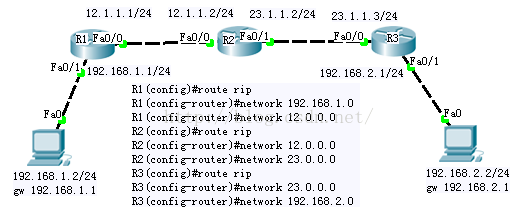
開啟動態路由命令:
R1(config)#route rip
進行網段通告命令:
R1(router-router)#network192.168.1.0
R1(config-router)#network 12.0.0.0
檢視路由表:
R1#show ip route
清除路由表:
R1#clear ip route * “*”代表所有
Debug看到的結果是動態的。由於會佔用路由器資源,所以慎用。
抓取資料包命令:
R1#debug ip rip
關閉抓取資料包命令:
R1#undebug all
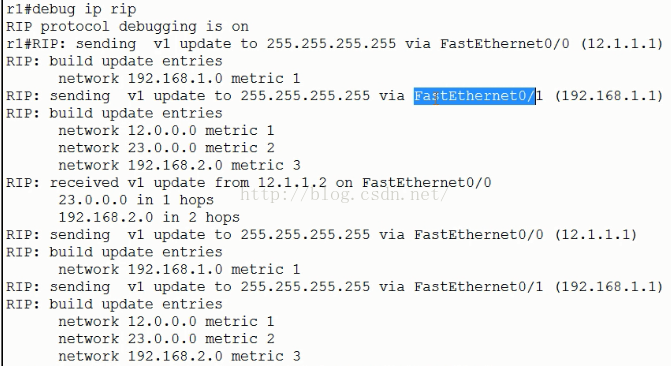
右圖就是抓取的實時動態更新包的資訊:
Sending v1 update to255.255.255.255 via Fastethernet0/0 (12.1.1.1)
意思是:rip的v1版本傳送了一個廣播更新包,出介面是f0/0,出介面地址是12.1.1.1。
255.255.255.255 表示廣播
RIP:build update entries 構建更新條目
Network 192.168.1.0 metric 1 通告192.168.1.0網段,跳數是1跳。
RIP: reveived v1update from 12.1.1.2 on Fastethernet0/0 從12.1.1.2接收到一個更新包,12.1.1.2的出介面是f0/0.
23.0.0.0 in 1 hops 23網段過來經過1跳,也就是“1 hops”
192.168.2.0 in 2 hops 192.168.2.0網段過來經過2跳,也就是“2 hops” “hops”---啤酒花的意思。
------------------------------------------------------------------------------------------------------------------------------------------------------------------
檢視當前路由協議狀態:
R1#show ip protocols
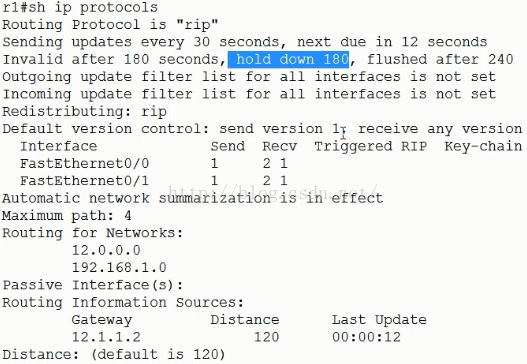
“RIP”當前路由協議
“invalid after 180 seconds”無效計時器180秒
“hold down 180”抑制計時器180秒,
“flushed after 240”重新整理計時器240秒,240秒後重新整理路由資訊。
“Automatic network summarization is in effect”邊界路由自動彙總已經起作用
“Maximum”支援4條等價負載均衡(最大可以達到16條)
當發現鏈路down了,不會立刻丟棄路由資訊而會等待180秒,如果到180秒鏈路還是沒有恢復,那麼會再等待60秒,如果在這60秒內鏈路恢復了,那就繼續正常使用,如果60秒以後還沒有恢復,那麼就到了180+60=240秒了,這個時候路由資訊就被重新整理丟棄了。
基於rip v2版本的路由框架:
如果將兩個計算機的ip地址都換成同一主網的ip地址。
那麼172.16.1.2是ping不通172.16.2.2的,而且如果在R2上面分別ping172.16.1.2和ping172.16.2.2,開debug就可以看到,實際上R2轉發出去的更新包是一左一右的,也就是一個發左邊,一個發右邊。這樣就會造成丟包的現象
“!.!.!”。因為,無論是172.16.1.2還是172.16.2.2它們到主網邊界進行路由彙總的時候,都是一條主網路由“172.16.0.0”而這個時候讓R2在去轉發ping的資料包,會不確定往左邊還有右邊發,最後為了實現負載均衡,就會左邊發一個右邊再發一個的重複來完成。
那麼如何來讓它們完全不丟包呢?
1.首先就需要將現在使用路由協議rip v1版本更換成rip v2版本。
2.然後關閉主網邊界的路由自動彙總功能。(rip v1版本無法關閉主網邊界的路由自動彙總)
3.最後就可以再去ping,得到的結果就是“!!!!!”也就完全ping通,而不會丟包
因為,當關閉主網邊界路由的自動彙總以後,在R1、R2、R3的路由表裡面的路由資訊,就會出現有掩碼的路由條目,這樣按地址轉發,當然就能準確找到目標地址。

開啟動態路由RIP:
R1(config)#router rip
更改RIP版本:
R1(config-router)#version 2 (只有rip v2的版本才可以關閉主網邊界自動彙總,而預設開啟的rip路由是v1)
關閉自動主網邊界自動彙總:
R1(config-router)#noauto-summary
路由通告:
R1(router-router)#network192.168.1.0 (如果是子網劃分的路由條目,要通告主類路由“172.16.0.0/12.0.0.0“)
產看當前路由協議資訊:
R1#show ip protocols
開啟debug:關閉debug:
R1#debug ip rip R1#undebug all
清除路由表:
R1#clear ip route *