
Spring data jpa 複雜動態查詢方式總結
一.Spring data jpa 簡介
首先我並不推薦使用jpa作為ORM框架,畢竟對於負責查詢的時候還是不太靈活,還是建議使用mybatis,自己寫sql比較好.但是如果公司用這個就沒辦法了,可以學習一下,對於簡單查詢還是非常好用的.
首先JPA是Java持久層API,由Sun公司開發, 希望整合ORM技術,實現天下歸一.誕生的緣由是為了整合第三方ORM框架,建立一種標準的方式,目前也是在按照這個方向發展,但是還沒能完全實現。在ORM框架中,Hibernate是一支很大的部隊,使用很廣泛,也很方便,能力也很強,同時Hibernate也是和JPA整合的比較良好,我們可以認為JPA是標準,事實上也是,JPA幾乎都是介面,實現都是Hibernate在做,巨集觀上面看,在JPA的統一之下Hibernate很良好的執行。
Spring-data-jpa,Spring與jpa的整合
Spring主要是在做第三方工具的整合 不重新造輪子.而在與第三方整合這方面,Spring做了持久化這一塊的工作,於是就有了Spring-data-**這一系列包。包括,Spring-data-jpa,Spring-data-template,Spring-data-mongodb,Spring-data-redis
Spring-data-jpa,目的少使用sql
我們都知道,在使用持久化工具的時候,一般都有一個物件來操作資料庫,在原生的Hibernate中叫做Session,在JPA中叫做EntityManager,在MyBatis中叫做SqlSession,通過這個物件來操作資料庫。我們一般按照三層結構來看的話,Service層做業務邏輯處理,Dao層和資料庫打交道,在Dao中,就存在著上面的物件。那麼ORM框架本身提供的功能有什麼呢?答案是基本的CRUD(增刪改查),所有的基礎CRUD框架都提供,我們使用起來感覺很方便,很給力,業務邏輯層面的處理ORM是沒有提供的,如果使用原生的框架,業務邏輯程式碼我們一般會自定義,會自己去寫SQL語句,然後執行。在這個時候,Spring-data-jpa的威力就體現出來了,ORM提供的能力他都提供,ORM框架沒有提供的業務邏輯功能Spring-data-jpa也提供,全方位的解決使用者的需求。使用Spring-data-jpa進行開發的過程中,常用的功能,我們幾乎不需要寫一條sql語句,至少在我看來,企業級應用基本上可以不用寫任何一條sql,當然spring-data-jpa也提供自己寫sql的方式
返回值為物件的意義
是jpa查詢表內容返回值基本上都是物件,但是僅僅需要一個欄位返回整體物件不是會有很多資料冗餘嗎,其實大多數情況對一個數據表的查詢不可能只有一次或者說這個表不僅僅是這一次會用到,如果我寫好一個返回物件的方法,之後都可以直接呼叫,一般情況下多出一點資料對網路的壓力可以忽略不計,而這樣對開發效率的提升還是很大的.如果僅僅想得到一部分欄位也可以新建一個只有想要欄位的Entity.
二.Spring data jpa 基本使用
對於配置方法和基礎的dao層寫法等不做介紹,基礎篇僅當做一個方法字典.
1.核心方法
- 查詢所有資料 findAll()
- 修改 新增資料 S save(S entity)
- 分頁查詢 Page<S> findAll(Example<S> example, Pageable pageable)
- 根據id查詢 findOne()
- 根據實體類屬性查詢: findByProperty (type Property); 例如:findByAge(int age)
- 刪除 void delete(T entity)
- 計數 查詢 long count() 或者 根據某個屬性的值查詢總數 countByAge(int age)
- 是否存在 boolean existsById(ID primaryKey)
2.查詢關鍵字
-and
And 例如:findByUsernameAndPassword(String user, Striang pwd);
-orOr 例如:findByUsernameOrAddress(String user, String addr);
-betweenBetween 例如:SalaryBetween(int max, int min);
-"<"LessThan 例如: findBySalaryLessThan(int max);
-">"GreaterThan 例如: findBySalaryGreaterThan(int min);
-is nullIsNull 例如: findByUsernameIsNull();
-is not nullIsNotNull NotNull 與 IsNotNull 等價 例如: findByUsernameIsNotNull();
-likeLike 例如: findByUsernameLike(String user);
-not likeNotLike 例如: findByUsernameNotLike(String user);
-order byOrderBy 例如: findByUsernameOrderByNameAsc(String user);直接通過name正序排序
-"!="Not 例如: findByUsernameNot(String user);
-inIn 例如: findByUsernameIn(Collection<String> userList) ,方法的引數可以是 Collection 型別,也可以是陣列或者不定長引數;
-not inNotIn 例如: findByUsernameNotIn(Collection<String> userList) ,方法的引數可以是 Collection 型別,也可以是陣列或者不定長引數;
-Top/Limit查詢方法結果的數量可以通過關鍵字來限制,first 或者 top都可以使用。top/first加數字可以指定要返回最大結果的大小 預設為1
例如:
User findFirstByOrderByLastnameAsc();
User findTopByOrderByAgeDesc();
Page<User> queryFirst10ByLastname(String lastname, Pageable pageable);
Slice<User> findTop3ByLastname(String lastname, Pageable pageable);
List<User> findFirst10ByLastname(String lastname, Sort sort);
List<User> findTop10ByLastname(String lastname, Pageable pageable);- 詳細查詢語法
| 關鍵詞 | 示例 | 對應的sql片段 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.內建方法
- Sort_排序
Sort sort =new Sort(Sort.Direction.ASC,"id");
//其中第一個引數表示是降序還是升序(此處表示升序)
//第二個引數表示你要按你的 entity(記住是entity中宣告的變數,不是資料庫中表對應的欄位)中的那個變數進行排序- PageRequest_分頁
PageRequest pageRequest = new PageRequest(index, num, sort);
//index偏移量 num查詢數量 sort排序分頁+排序實現:
DemoBean demoBean = new DemoBean();
demoBean.setAppId(appId); //查詢條件
//建立查詢引數
Example<DemoBean> example = Example.of(demoBean);
//獲取排序物件
Sort sort = new Sort(Sort.Direction.DESC, "id");
//建立分頁物件
PageRequest pageRequest = new PageRequest(index, num, sort);
//分頁查詢
return demoRepository.findAll(example, pageRequest).getContent();
- Example_例項查詢
建立一個ExampleMatcher物件,最後再用Example的of方法構造相應的Example物件並傳遞給相關查詢方法。我們看看Spring的例子。
Person person = new Person();
person.setFirstname("Dave"); //Firstname = 'Dave'
ExampleMatcher matcher = ExampleMatcher.matching()
.withMatcher("name", GenericPropertyMatchers.startsWith()) //姓名採用“開始匹配”的方式查詢
.withIgnorePaths("int"); //忽略屬性:是否關注。因為是基本型別,需要忽略掉
Example<Person> example = Example.of(person, matcher); //Example根據域物件和配置建立一個新的ExampleMatcher ExampleMatcher用於建立一個查詢物件,上面的程式碼就建立了一個查詢物件。withIgnorePaths方法用來排除某個屬性的查詢。withIncludeNullValues方法讓空值也參與查詢,就是我們設定了物件的姓,而名為空值.
1、概念定義:
上面例子中,是這樣建立“例項”的:Example<Customer> ex = Example.of(customer, matcher);我們看到,Example物件,由customer和matcher共同建立。
A、實體物件:在持久化框架中與Table對應的域物件,一個物件代表資料庫表中的一條記錄,如上例中Customer物件。在構建查詢條件時,一個實體物件代表的是查詢條件中的“數值”部分。如:要查詢名字是“Dave”的客戶,實體物件只能儲存條件值“Dave”。
B、匹配器:ExampleMatcher物件,它是匹配“實體物件”的,表示瞭如何使用“實體物件”中的“值”進行查詢,它代表的是“查詢方式”,解釋瞭如何去查的問題。如:要查詢FirstName是“Dave”的客戶,即名以“Dave"開頭的客戶,該物件就表示了“以什麼開頭的”這個查詢方式,如上例中:withMatcher("name", GenericPropertyMatchers.startsWith())
C、例項:即Example物件,代表的是完整的查詢條件。由實體物件(查詢條件值)和匹配器(查詢方式)共同建立。
再來理解“例項查詢”,顧名思義,就是通過一個例子來查詢。要查詢的是Customer物件,查詢條件也是一個Customer物件,通過一個現有的客戶物件作為例子,查詢和這個例子相匹配的物件。
2、特點及約束(侷限性):
A、支援動態查詢。即支援查詢條件個數不固定的情況,如:客戶列表中有多個過濾條件,使用者使用時在“地址”查詢框中輸入了值,就需要按地址進行過濾,如果沒有輸入值,就忽略這個過濾條件。對應的實現是,在構建查詢條件Customer物件時,將address屬性值置具體的條件值或置為null。
B、不支援過濾條件分組。即不支援過濾條件用 or(或) 來連線,所有的過濾查件,都是簡單一層的用 and(並且) 連線。
C、僅支援字串的開始/包含/結束/正則表示式匹配 和 其他屬性型別的精確匹配。查詢時,對一個要進行匹配的屬性(如:姓名 name),只能傳入一個過濾條件值,如以Customer為例,要查詢姓“劉”的客戶,“劉”這個條件值就儲存在表示條件物件的Customer物件的name屬性中,針對於“姓名”的過濾也只有這麼一個儲存過濾值的位置,沒辦法同時傳入兩個過濾值。正是由於這個限制,有些查詢是沒辦法支援的,例如要查詢某個時間段內新增的客戶,對應的屬性是 addTime,需要傳入“開始時間”和“結束時間”兩個條件值,而這種查詢方式沒有存兩個值的位置,所以就沒辦法完成這樣的查詢。
3、ExampleMatcher的使用 :
- 一些問題:
(1)Null值的處理。當某個條件值為Null,是應當忽略這個過濾條件呢,還是應當去匹配資料庫表中該欄位值是Null的記錄?
(2)基本型別的處理。如客戶Customer物件中的年齡age是int型的,當頁面不傳入條件值時,它預設是0,是有值的,那是否參與查詢呢?
(3)忽略某些屬性值。一個實體物件,有許多個屬性,是否每個屬性都參與過濾?是否可以忽略某些屬性?
(4)不同的過濾方式。同樣是作為String值,可能“姓名”希望精確匹配,“地址”希望模糊匹配,如何做到?
(5)大小寫匹配。字串匹配時,有時可能希望忽略大小寫,有時則不忽略,如何做到?
- 一些方法:
1、關於基本資料型別。
實體物件中,避免使用基本資料型別,採用包裝器型別。如果已經採用了基本型別,
而這個屬性查詢時不需要進行過濾,則把它新增到忽略列表(ignoredPaths)中。
2、Null值處理方式。
預設值是 IGNORE(忽略),即當條件值為null時,則忽略此過濾條件,一般業務也是採用這種方式就可滿足。當需要查詢資料庫表中屬性為null的記錄時,可將值設為INCLUDE,這時,對於不需要參與查詢的屬性,都必須新增到忽略列表(ignoredPaths)中,否則會出現查不到資料的情況。
3、預設配置、特殊配置。
預設建立匹配器時,字串採用的是精確匹配、不忽略大小寫,可以通過操作方法改變這種預設匹配,以滿足大多數查詢條件的需要,如將“字串匹配方式”改為CONTAINING(包含,模糊匹配),這是比較常用的情況。對於個別屬性需要特定的查詢方式,可以通過配置“屬性特定查詢方式”來滿足要求。
4、非字串屬性
如約束中所談,非字串屬性均採用精確匹配,即等於。
5、忽略大小寫的問題。
忽略大小的生效與否,是依賴於資料庫的。例如 MySql 資料庫中,預設建立表結構時,欄位是已經忽略大小寫的,所以這個配置與否,都是忽略的。如果業務需要嚴格區分大小寫,可以改變資料庫表結構屬性來實現,具體可百度。
- 一些例子:
綜合使用:
//建立查詢條件資料物件
Customer customer = new Customer();
customer.setName("zhang");
customer.setAddress("河南省");
customer.setRemark("BB");
//建立匹配器,即如何使用查詢條件
ExampleMatcher matcher = ExampleMatcher.matching() //構建物件
.withStringMatcher(StringMatcher.CONTAINING) //改變預設字串匹配方式:模糊查詢
.withIgnoreCase(true) //改變預設大小寫忽略方式:忽略大小寫
.withMatcher("address", GenericPropertyMatchers.startsWith()) //地址採用“開始匹配”的方式查詢
.withIgnorePaths("focus"); //忽略屬性:是否關注。因為是基本型別,需要忽略掉
//建立例項
Example<Customer> ex = Example.of(customer, matcher);
//查詢
List<Customer> ls = dao.findAll(ex);查詢null值:
//建立查詢條件資料物件
Customer customer = new Customer();
//建立匹配器,即如何使用查詢條件
ExampleMatcher matcher = ExampleMatcher.matching() //構建物件
.withIncludeNullValues() //改變“Null值處理方式”:包括
.withIgnorePaths("id","name","sex","age","focus","addTime","remark","customerType"); //忽略其他屬性
//建立例項
Example<Customer> ex = Example.of(customer, matcher);
//查詢
List<Customer> ls = dao.findAll(ex);三.Spring data jpa 註解
1.Repository註解
@Modifying //做update操作時需要新增
@Query // 自定義Sql
@Query(value = "SELECT * FROM USERS WHERE X = ?1", nativeQuery = true)
User findByEmailAddress(String X);
@Query("select u from User u where u.firstname = :firstname") //不加nativeQuery應使用HQL
User findByLastnameOrFirstname(@Param("lastname") String lastname);@Transactional //事務
@Async //非同步操作
2.Entity註解
@Entity //不寫@Table預設為user
@Table(name="t_user") //自定義表名
public class user {
@Id //主鍵
@GeneratedValue(strategy = GenerationType.AUTO)//採用資料庫自增方式生成主鍵
//JPA提供的四種標準用法為TABLE,SEQUENCE,IDENTITY,AUTO.
//TABLE:使用一個特定的資料庫表格來儲存主鍵。
//SEQUENCE:根據底層資料庫的序列來生成主鍵,條件是資料庫支援序列。
//IDENTITY:主鍵由資料庫自動生成(主要是自動增長型)
//AUTO:主鍵由程式控制。
@Transient //此欄位不與資料庫關聯
@Version//此欄位加上樂觀鎖
//欄位為name,不允許為空,使用者名稱唯一
@Column(name = "name", unique = true, nullable = false)
private String name;
@Temporal(TemporalType.DATE)//生成yyyy-MM-dd型別的日期
//出參時間格式化
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
//入參時,請求報文只需要傳入yyyymmddhhmmss字串進來,則自動轉換為Date型別資料
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm")
private Date createTime;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}四.繼承JpaSpecificationExecutor介面進行復雜查詢
spring data jpa 通過建立方法名來做查詢,只能做簡單的查詢,那如果我們要做複雜一些的查詢呢,多條件分頁怎麼辦,這裡,spring data jpa為我們提供了JpaSpecificationExecutor介面,只要簡單實現toPredicate方法就可以實現複雜的查詢
參考:https://www.cnblogs.com/happyday56/p/4661839.html
1.首先讓我們的介面繼承於JpaSpecificationExecutor
public interface TaskDao extends JpaSpecificationExecutor<Task>{
}2.JpaSpecificationExecutor提供了以下介面
public interface JpaSpecificationExecutor<T> {
T findOne(Specification<T> spec);
List<T> findAll(Specification<T> spec);
Page<T> findAll(Specification<T> spec, Pageable pageable);
List<T> findAll(Specification<T> spec, Sort sort);
long count(Specification<T> spec);
}
//其中Specification就是需要我們傳入查詢方法的引數,它是一個介面
public interface Specification<T> {
Predicate toPredicate(Root<T> root, CriteriaQuery<?> query, CriteriaBuilder cb);
}提供唯一的一個方法toPredicate,我們只要按照JPA 2.0 criteria api寫好查詢條件就可以了,關於JPA 2.0 criteria api的介紹和使用,歡迎參考
http://blog.csdn.net/dracotianlong/article/details/28445725
http://developer.51cto.com/art/200911/162722.htm
3.接下來我們在service bean
@Service
public class TaskService {
@Autowired TaskDao taskDao ;
/**
* 複雜查詢測試
* @param page
* @param size
* @return
*/
public Page<Task> findBySepc(int page, int size){
PageRequest pageReq = this.buildPageRequest(page, size);
Page<Task> tasks = this.taskDao.findAll(new MySpec(), pageReq);
//傳入了new MySpec() 既下面定義的匿名內部類 其中定義了查詢條件
return tasks;
}
/**
* 建立分頁排序請求
* @param page
* @param size
* @return
*/
private PageRequest buildPageRequest(int page, int size) {
Sort sort = new Sort(Direction.DESC,"createTime");
return new PageRequest(page,size, sort);
}
/**
* 建立查詢條件
*/
private class MySpec implements Specification<Task>{
@Override
public Predicate toPredicate(Root<Task> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
//1.混合條件查詢
Path<String> exp1 = root.get("taskName");
Path<Date> exp2 = root.get("createTime");
Path<String> exp3 = root.get("taskDetail");
Predicate predicate = cb.and(cb.like(exp1, "%taskName%"),cb.lessThan(exp2, new Date()));
return cb.or(predicate,cb.equal(exp3, "kkk"));
/* 類似的sql語句為:
Hibernate:
select
count(task0_.id) as col_0_0_
from
tb_task task0_
where
(
task0_.task_name like ?
)
and task0_.create_time<?
or task0_.task_detail=?
*/
//2.多表查詢
Join<Task,Project> join = root.join("project", JoinType.INNER);
Path<String> exp4 = join.get("projectName");
return cb.like(exp4, "%projectName%");
/* Hibernate:
select
count(task0_.id) as col_0_0_
from
tb_task task0_
inner join
tb_project project1_
on task0_.project_id=project1_.id
where
project1_.project_name like ?*/
return null ;
}
}
}4.實體類task程式碼如下
@Entity
@Table(name = "tb_task")
public class Task {
private Long id ;
private String taskName ;
private Date createTime ;
private Project project;
private String taskDetail ;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
@Column(name = "task_name")
public String getTaskName() {
return taskName;
}
public void setTaskName(String taskName) {
this.taskName = taskName;
}
@Column(name = "create_time")
@DateTimeFormat(pattern = "yyyy-MM-dd hh:mm:ss")
public Date getCreateTime() {
return createTime;
}
public void setCreateTime(Date createTime) {
this.createTime = createTime;
}
@Column(name = "task_detail")
public String getTaskDetail() {
return taskDetail;
}
public void setTaskDetail(String taskDetail) {
this.taskDetail = taskDetail;
}
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "project_id")
public Project getProject() {
return project;
}
public void setProject(Project project) {
this.project = project;
}
}通過重寫toPredicate方法,返回一個查詢 Predicate,spring data jpa會幫我們進行查詢。
也許你覺得,每次都要寫一個類來實現Specification很麻煩,那或許你可以這麼寫
public class TaskSpec {
public static Specification<Task> method1(){
return new Specification<Task>(){
@Override
public Predicate toPredicate(Root<Task> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
return null;
}
};
}
public static Specification<Task> method2(){
return new Specification<Task>(){
@Override
public Predicate toPredicate(Root<Task> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
return null;
}
};
}
}那麼用的時候,我們就這麼用
Page<Task> tasks = this.taskDao.findAll(TaskSpec.method1(), pageReq);
五.Spring data jpa + QueryDSL 進行復雜查詢
- QueryDSL僅僅是一個通用的查詢框架,專注於通過Java API構建型別安全的SQL查詢。
- Querydsl可以通過一組通用的查詢API為使用者構建出適合不同型別ORM框架或者是SQL的查詢語句,也就是說QueryDSL是基於各種ORM框架以及SQL之上的一個通用的查詢框架。
- 藉助QueryDSL可以在任何支援的ORM框架或者SQL平臺上以一種通用的API方式來構建查詢。目前QueryDSL支援的平臺包括JPA,JDO,SQL,Java Collections,RDF,Lucene,Hibernate Search。
P.s.配置可以根據官網介紹來配置
1 實體類
城市類:
@Entity
@Table(name = "t_city", schema = "test", catalog = "")
public class TCity {
//省略JPA註解標識
private int id;
private String name;
private String state;
private String country;
private String map;
}旅館類:
@Entity
@Table(name = "t_hotel", schema = "test", catalog = "")
public class THotel {
//省略JPA註解標識
private int id;
private String name;
private String address;
private Integer city;//儲存著城市的id主鍵
}2 單表動態分頁查詢
Spring Data JPA中提供了QueryDslPredicateExecutor介面,用於支援QueryDSL的查詢操作
public interface tCityRepository extends JpaRepository<TCity, Integer>, QueryDslPredicateExecutor<TCity> {
}這樣的話單表動態查詢就可以參考如下程式碼:
//查找出Id小於3,並且名稱帶有`shanghai`的記錄.
//動態條件
QTCity qtCity = QTCity.tCity; //SDL實體類
//該Predicate為querydsl下的類,支援巢狀組裝複雜查詢條件
Predicate predicate = qtCity.id.longValue().lt(3).and(qtCity.name.like("shanghai"));
//分頁排序
Sort sort = new Sort(new Sort.Order(Sort.Direction.ASC,"id"));
PageRequest pageRequest = new PageRequest(0,10,sort);
//查詢結果
Page<TCity> tCityPage = tCityRepository.findAll(predicate,pageRequest);3 多表動態查詢
QueryDSL對多表查詢提供了一個很好地封裝,看下面程式碼:
/**
* 關聯查詢示例,查詢出城市和對應的旅店
* @param predicate 查詢條件
* @return 查詢實體
*/
@Override
public List<Tuple> findCityAndHotel(Predicate predicate) {
JPAQueryFactory queryFactory = new JPAQueryFactory(em);
JPAQuery<Tuple> jpaQuery = queryFactory.select(QTCity.tCity,QTHotel.tHotel)
.from(QTCity.tCity)
.leftJoin(QTHotel.tHotel)
.on(QTHotel.tHotel.city.longValue().eq(QTCity.tCity.id.longValue()));
//新增查詢條件
jpaQuery.where(predicate);
//拿到結果
return jpaQuery.fetch();
}城市表左連線旅店表,當該旅店屬於這個城市時查詢出兩者的詳細欄位,存放到一個Tuple的多元組中.相比原生sql,簡單清晰了很多.
那麼該怎麼呼叫這個方法呢?
@Test
public void findByLeftJoin(){
QTCity qtCity = QTCity.tCity;
QTHotel qtHotel = QTHotel.tHotel;
//查詢條件
Predicate predicate = qtCity.name.like("shanghai");
//呼叫
List<Tuple> result = tCityRepository.findCityAndHotel(predicate);
//對多元組取出資料,這個和select時的資料相匹配
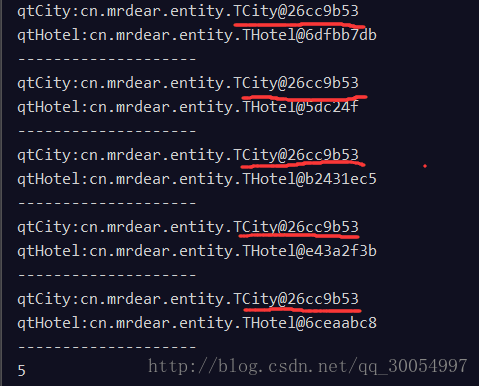
for (Tuple row : result) {
System.out.println("qtCity:"+row.get(qtCity));
System.out.println("qtHotel:"+row.get(qtHotel));
System.out.println("--------------------");
}
System.out.println(result);
}這樣做的話避免了返回Object[]陣列,下面是自動生成的sql語句:
select
tcity0_.id as id1_0_0_,
thotel1_.id as id1_1_1_,
tcity0_.country as country2_0_0_,
tcity0_.map as map3_0_0_,
tcity0_.name as name4_0_0_,
tcity0_.state as state5_0_0_,
thotel1_.address as address2_1_1_,
thotel1_.city as city3_1_1_,
thotel1_.name as name4_1_1_
from
t_city tcity0_
left outer join
t_hotel thotel1_
on (
cast(thotel1_.city as signed)=cast(tcity0_.id as signed)
)
where
tcity0_.name like ? escape '!'4 多表動態分頁查詢
分頁查詢對於queryDSL無論什麼樣的sql只需要寫一遍,會自動轉換為相應的count查詢,也就避免了文章開始的問題4,下面程式碼是對上面的查詢加上分頁功能:
@Override
public QueryResults<Tuple> findCityAndHotelPage(Predicate predicate,Pageable pageable) {
JPAQueryFactory queryFactory = new JPAQueryFactory(em);
JPAQuery<Tuple> jpaQuery = queryFactory.select(QTCity.tCity.id,QTHotel.tHotel)
.from(QTCity.tCity)
.leftJoin(QTHotel.tHotel)
.on(QTHotel.tHotel.city.longValue().eq(QTCity.tCity.id.longValue()))
.where(predicate)
.offset(pageable.getOffset())
.limit(pageable.getPageSize());
//拿到分頁結果
return jpaQuery.fetchResults();
}和上面不同之處在於這裡使用了offset和limit限制查詢結果.並且返回一個QueryResults,該類會自動實現count查詢和結果查詢,並進行封裝.
呼叫形式如下:
@Test
public void findByLeftJoinPage(){
QTCity qtCity = QTCity.tCity;
QTHotel qtHotel = QTHotel.tHotel;
//條件
Predicate predicate = qtCity.name.like("shanghai");
//分頁
PageRequest pageRequest = new PageRequest(0,10);
//呼叫查詢
QueryResults<Tuple> result = tCityRepository.findCityAndHotelPage(predicate,pageRequest);
//結果取出
for (Tuple row : result.getResults()) {
System.out.println("qtCity:"+row.get(qtCity));
System.out.println("qtHotel:"+row.get(qtHotel));
System.out.println("--------------------");
}
//取出count查詢總數
System.out.println(result.getTotal());
}生成的原生count查詢sql,當該count查詢結果為0的話,則直接返回,並不會再進行具體資料查詢:
select
count(tcity0_.id) as col_0_0_
from
t_city tcity0_
left outer join
t_hotel thotel1_
on (
cast(thotel1_.city as signed)=cast(tcity0_.id as signed)
)
where
tcity0_.name like ? escape '!'生成的原生查詢sql:
select
tcity0_.id as id1_0_0_,
thotel1_.id as id1_1_1_,
tcity0_.country as country2_0_0_,
tcity0_.map as map3_0_0_,
tcity0_.name as name4_0_0_,
tcity0_.state as state5_0_0_,
thotel1_.address as address2_1_1_,
thotel1_.city as city3_1_1_,
thotel1_.name as name4_1_1_
from
t_city tcity0_
left outer join
t_hotel thotel1_
on (
cast(thotel1_.city as signed)=cast(tcity0_.id as signed)
)
where
tcity0_.name like ? escape '!' limit ?檢視列印,可以發現對應的city也都是同一個物件,hotel是不同的物件.
5 改造
有了上面的經驗,改造就變得相當容易了.
首先前面的一堆sql可以寫成如下形式,無非是多了一些select和left join
JPAQueryFactory factory = new JPAQueryFactory(entityManager);
factory.select($.pcardCardOrder)
.select($.pcardVcardMake.vcardMakeDes)
.select($.pcardVtype.cardnumRuleId,$.pcardVtype.vtypeNm)
.select($.pcardCardbin)
.leftJoin($.pcardVcardMake).on($.pcardCardOrder.makeId.eq($.pcardVcardMake.vcardMakeId))
//......省略查詢條件使用Predicate代替,放在service拼接,或者寫一個生產條件的工廠都可以.
jpaQuery.where(predicate);最後的分頁處理就和之前的一樣了
jpaQuery.offset(pageable.getOffset())
.limit(pageable.getPageSize());
return jpaQuery.fetchResults();寫在最後:
個人認為jpa的意義就在於少用原生sql 為了方便開發 封裝已經是在所難免了. 推薦多使用簡單查詢,需要使用動態查詢的時候推薦使用JpaSpecificationExecutor個人認為比較好用.
雖然我還是喜歡原生的寫法...
另外很多時候簡單的條件可以在server層進行判斷呼叫不同的Dao層方法就可以。
P.s.參考資料