
資料探勘十大演算法----EM演算法(最大期望演算法)
概念
在統計計算中,最大期望(EM)演算法是在概率(probabilistic)模型中尋找引數最大似然估計或者最大後驗估計的演算法,其中概率模型依賴於無法觀測的隱藏變數(Latent Variable)。
最大期望經常用在機器學習和計算機視覺的資料聚類(Data Clustering)領域。
可以有一些比較形象的比喻說法把這個演算法講清楚。
比如說食堂的大師傅炒了一份菜,要等分成兩份給兩個人吃,顯然沒有必要拿來天平一點一點的精確的去稱分量,最簡單的辦法是先隨意的把菜分到兩個碗中,然後觀察是否一樣多,把比較多的那一份取出一點放到另一個碗中,這個過程一直迭代地執行下去,直到大家看不出兩個碗所容納的菜有什麼分量上的不同為止。(來自百度百科)
EM演算法就是這樣,假設我們估計知道A和B兩個引數,在開始狀態下二者都是未知的,並且知道了A的資訊就可以得到B的資訊,反過來知道了B也就得到了A。可以考慮首先賦予A某種初值,以此得到B的估計值,然後從B的當前值出發,重新估計A的取值,這個過程一直持續到收斂為止。
EM演算法還是許多非監督聚類演算法的基礎(如Cheeseman et al. 1988),而且它是用於學習部分可觀察馬爾可夫模型(Partially Observable Markov Model)的廣泛使用的Baum-Welch前向後向演算法的基礎。
估計k個高斯分佈的均值
介紹EM演算法最方便的方法是通過一個例子。
考慮資料D
每個例項使用一個兩步驟過程形成。
首先了隨機選擇k個正態分佈其中之一。
其次隨機變數xi按照此選擇的分佈生成。
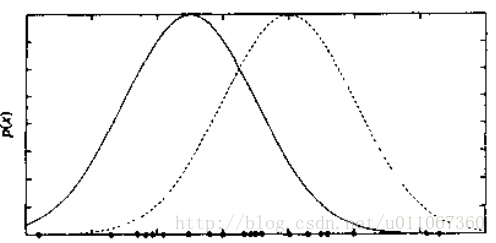
這一過程不斷重複,生成一組資料點如圖所示。為使討論簡單化,我們考慮一個簡單情形,即單個正態分佈的選擇基於統一的概率進行選擇,並且k個正態分佈有相同的方差σ2,且σ2已知。
學習任務是輸出一個假設h=<μ1…μk>,它描述了k個分佈中每一個分佈的均值。我們希望對這些均值找到一個極大似然假設,即一個使P(D|h)最大化的假設h。
注意到,當給定從一個正態分佈中抽取的資料例項x
其中我們可以證明極大似然假設是使m個訓練例項上的誤差平方和最小化的假設。
使用當表述一下式,可以得到:
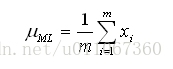
然而,在這裡我們的問題涉及到k個不同正態分佈的混合,而且我們不能知道哪個例項是哪個分佈產生的。因此這是一個涉及隱藏變數的典型例子。
EM演算法步驟
在上圖的例子中,可把每個例項的完整描述看作是三元組<xi,zi1, zi2>,其中xi是第i個例項的觀測值,zi1和zi2表示兩個正態分佈中哪個被用於產生值xi。
確切地講,zij在xi由第j個正態分佈產生時值為1,否則為0。這裡xi是例項的描述中已觀察到的變數,zi1和zi2是隱藏變數。如果zi1和zi2的值可知,就可以用式一來解決均值μ1和μ2。因為它們未知,因此我們只能用EM演算法。
EM演算法應用於我們的k均值問題,目的是搜尋一個極大似然假設,方法是根據當前假設<μ1…μk>不斷地再估計隱藏變數zij的期望值。然後用這些隱藏變數的期望值重新計算極大似然假設。這裡首先描述這一例項化的EM演算法,以後將給出EM演算法的一般形式。
為了估計上圖中的兩個均值,EM演算法首先將假設初始化為h=<μ1,μ2>,其中μ1和μ2為任意的初始值。然後重複以下的兩個步驟以重估計h,直到該過程收斂到一個穩定的h值。
步驟1:計算每個隱藏變數zij的期望值E[zij],假定當前假設h=<μ1,μ2>成立。
步驟2:計算一個新的極大似然假設h´=<μ1´,μ2´>,假定由每個隱藏變數zij所取的值為第1步中得到的期望值E[zij],然後將假設h=<μ1,μ2>替換為新的假設h´=<μ1´,μ2´>,然後迴圈。
現在考察第一步是如何實現的。步驟1要計算每個zij的期望值。此E[zij]正是例項xi由第j個正態分佈生成的概率:
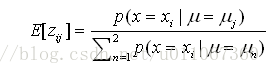
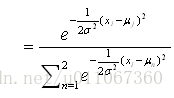
因此第一步可由將當前值<μ1,μ2>和已知的xi代入到上式中實現。
在第二步,使用第1步中得到的E[zij]來匯出一新的極大似然假設h´=<μ1´,μ2´>。如後面將討論到的,這時的極大似然假設為:
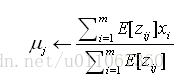
注意此表示式類似於公式一中的樣本均值,它用於從單個正態分佈中估計μ。新的表示式只是對μj的加權樣本均值,每個例項的權重為其由第j個正態分佈產生的期望值。
上面估計k個正態分佈均值的演算法描述了EM方法的要點:即當前的假設用於估計未知變數,而這些變數的期望值再被用於改進假設。
可以證明,在此演算法第一次迴圈中,EM演算法能使似然性P(D|h)增加,除非它已達到區域性的最大。因此該演算法收斂到對於<μ1,μ2>的一個局部極大可能性假設。
EM演算法的一般表述
上面的EM演算法針對的是估計混合正態分佈均值的問題。更一般地,EM演算法可用於許多問題框架,其中需要估計一組描述基準概率分佈的引數θ,只給定了由此分佈產生的全部資料中能觀察到的一部分。
在上面的二均值問題中,感興趣的引數為θ=<μ1,μ2>,而全部資料為三元組<xi,zi1, zi2>,而只有xi可觀察到,一般地令X=<x1, …,xm>代表在同樣的例項中已經觀察到的資料,並令Y=X∪Z代表全體資料。注意到未觀察到的Z可被看作一隨機變數,它的概率分佈依賴於未知引數θ和已知資料X。類似地,Y是一隨機變數,因為它是由隨機變數Z來定義的。在後續部分,將描述EM演算法的一般形式。使用h來代表引數θ的假設值,而h´代表在EM演算法的每次迭代中修改的假設。
EM演算法通過搜尋使E[lnP(Y|h´)]最大的h´來尋找極大似然假設h´。此期望值是在Y所遵循的概率分佈上計算,此分佈由未知引數θ確定。考慮此表示式究竟意味了什麼。
首先P(Y|h´)是給定假設h´下全部資料Y的似然性。其合理性在於我們要尋找一個h´使該量的某函式值最大化。
其次使該量的對數lnP(Y|h´)最大化也使P(Y|h´)最大化,如已經介紹過的那樣。
第三,引入期望值E[lnP(Y|h´)]是因為全部資料Y本身也是一隨機變數。
已知全部資料Y是觀察到的X和未觀察到的Z的合併,我們必須在未觀察到的Z的可能值上取平均,並以相應的概率為權值。換言之,要在隨機變數Y遵循的概率分佈上取期望值E[lnP(Y|h´)]。該分佈由完全已知的X值加上Z服從的分佈來確定。
Y遵從的概率分佈是什麼?一般來說不能知道此分佈,因為它是由待估計的θ引數確定的。然而,EM演算法使用其當前的假設h代替實際引數θ,以估計Y的分佈。現定義一函式Q(h´|h),它將E[lnP(Y|h´)]作為h´的一個函式給出,在θ=h和全部資料Y的觀察到的部分X的假定之下。
將Q函式寫成Q(h´|h)是為了表示其定義是在當前假設h等於θ的假定下。在EM演算法的一般形式裡,它重複以下兩個步驟直至收斂。
步驟1:估計(E)步驟:使用當前假設h和觀察到的資料X來估計Y上的概率分佈以計算Q(h´|h)。

步驟2:最大化(M)步驟:將假設h替換為使Q函式最大化的假設h´:
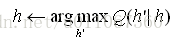
當函式Q連續時,EM演算法收斂到似然函式P(Y|h´)的一個不動點。若此似然函式有單個的最大值時,EM演算法可以收斂到這個對h´的全域性的極大似然估計。否則,它只保證收斂到一個區域性最大值。因此,EM與其他最優化方法有同樣的侷限性,如之前討論的梯度下降,線性搜尋和變形梯度等。
總結來說,EM演算法就是通過迭代地最大化完整資料的對數似然函式的期望,來最大化不完整資料的對數似然函式。