
資料庫的隔離級別以及鎖的關係的思考
前言
1.樂觀鎖和悲觀鎖 與 資料庫的隔離級別的關係 或者兩者使用的場景是什麼?
我在網上所能找到的答案,幫助個人的理解。
答案一:事務隔離級別是併發控制的整體解決方案,其實際上是綜合利用各種型別的鎖和行版本控制,來解決併發問題。鎖是資料庫併發控制的內部機制,是基礎。對使用者來說,只有當事務隔離級別無法解決一些併發問題和需求時,才有必要在語句中手動設定鎖。
那麼事務隔離級別無法解決哪些併發問題呢?
先來看看事務的隔離級別:
事務隔離級別
為了解決多個事務併發會引發的問題,進行併發控制。資料庫系統提供了四種事務隔離級別供使用者選擇。
- Read Uncommitted 讀未提交:不允許第一類更新丟失。允許髒讀,不隔離事務。
- Read Committed 讀已提交:不允許髒讀,允許不可重複讀。
- Repeatable Read 可重複讀:不允許不可重複讀。但可能出現幻讀。
- Serializable 序列化:所有的增刪改查序列執行。
讀未提交
事務讀不阻塞其他事務讀和寫,事務寫阻塞其他事務寫但不阻塞讀。
可以通過寫操作加“持續-X鎖”實現。
讀已提交
事務讀不會阻塞其他事務讀和寫,事務寫會阻塞其他事務讀和寫。
可以通過寫操作加“持續-X”鎖,讀操作加“臨時-S鎖”實現。
可重複讀
事務讀會阻塞其他事務事務寫但不阻塞讀,事務寫會阻塞其他事務讀和寫。
可以通過寫操作加“持續-X”鎖,讀操作加“持續-S鎖”實現。
序列化
“行級鎖”做不到,需使用“表級鎖”。
可序列化
如果一個並行排程的結果等價於某一個序列排程的結果,那麼這個並行排程是可序列化的。
區分事務隔離級別是為了解決髒讀、不可重複讀和幻讀三個問題的。
| 事務隔離級別 | 回滾覆蓋 | 髒讀 | 不可重複讀 | 提交覆蓋 | 幻讀 |
|---|---|---|---|---|---|
| 讀未提交 | x | 可能發生 | 可能發生 | 可能發生 | 可能發生 |
| 讀已提交 | x | x | 可能發生 | 可能發生 | 可能發生 |
| 可重複讀 | x | x | x | x | 可能發生 |
| 序列化 | x | x | x | x | x |
既然事務的隔離級別可以做到這些。還需要悲觀鎖幹什麼呢?
我的理解是:(理解有錯誤的,請大家指正)
Mysql預設使用的隔離級別是:可重複讀
MSSQL預設使用的隔離級別是:讀已提交
如果在MSSQL使用預設使用的隔離級別時讀已提交的同事也想開發過程中想解決:不可重複讀,提交覆蓋和幻讀等問題就可以使用悲觀鎖實現。
MYSQL同理。
儘管悲觀鎖能夠防止丟失更新和不可重複讀這類問題,但是它非常影響併發效能,因此應該謹慎使用。
樂觀鎖不能解決髒讀的問題,因此仍需要資料庫至少啟用“讀已提交”的事務隔離級別
三、常用的解決方案
2.悲觀鎖和共享鎖、排它鎖有是什麼關係呢?
共享鎖和排它鎖是悲觀鎖的不同的實現,它倆都屬於悲觀鎖的範疇。即悲觀鎖由共享鎖和排它鎖來實現的。
從讀寫角度,分共享鎖(S鎖,Shared Lock)和排他鎖(X鎖,Exclusive Lock),也叫讀鎖(Read Lock)和寫鎖(Write Lock)。理解:
持有S鎖的事務只讀不可寫。如果事務A對資料D加上S鎖後,其它事務只能對D加上S鎖而不能加X鎖。
持有X鎖的事務可讀可寫。如果事務A對資料D加上X鎖後,其它事務不能再對D加鎖,直到A對D的鎖解除
注:要使用悲觀鎖,我們必須關閉mysql資料庫的自動提交屬性,因為MySQL預設使用autocommit模式,也就是說,當你執行一個更新操作後,MySQL會立刻將結果進行提交。我們可以使用命令設定MySQL為非autocommit模式:set autocommit=0;設定完autocommit後,我們就可以執行我們的正常業務了。
開始事務使用begin;/begin work;/start transaction; (三者選一就可以);
提交事務使用commit;/commit work;
兩種鎖的具體實現如下:
- 共享鎖:悲觀鎖都是由資料庫實現的,那共享鎖在mysql中是通過什麼命令來呼叫呢。通過在執行語句後面加上lock in share mode 就代表對某些資源加上共享鎖了。
比如,我這裡通過mysql開啟兩個查詢編輯器,在其中開啟一個事務,並不執行commit語句。city表DDL如下
-
CREATE TABLE `city` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `state` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=18 DEFAULT CHARSET=utf8;

begin;
SELECT * from city where id = "1" lock in share mode;然後在另一個查詢視窗中,對id為1的資料進行更新
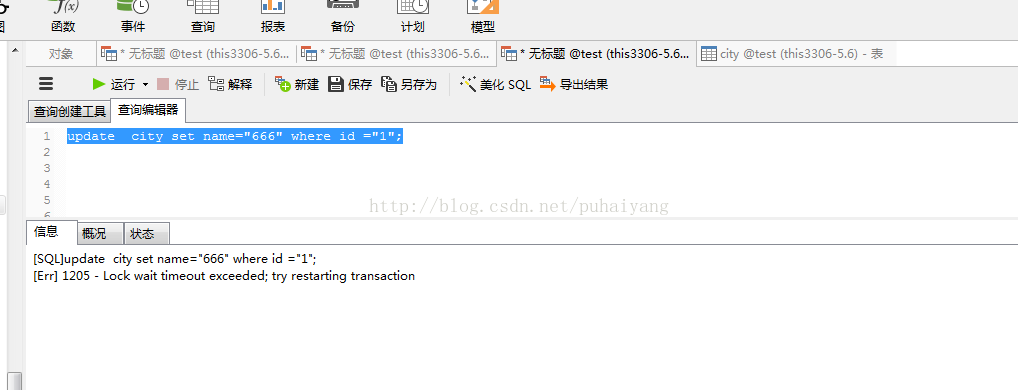
update city set name="666" where id ="1";
此時,操作介面進入了卡頓狀態,過幾秒後,也提示錯誤資訊
[SQL]update city set name="666" where id ="1";
[Err] 1205 - Lock wait timeout exceeded; try restarting transaction
那麼證明,對於id=1的記錄加鎖成功了。在上一條記錄還沒有commit之前,這條id=1的記錄被鎖住了,只有在上一個事務釋放掉鎖後才能進行操作,或用共享鎖才能對此資料進行操作。
如果在上面一條記錄加上commit;
begin;
SELECT * from city where id = "1" lock in share mode;
commit;則 update city set name="666" where id ="1";可以執行成功!
再實驗一下:

update city set name="666" where id ="1" lock in share mode;
[Err] 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'lock in share mode' at line 1
加上共享鎖後,也提示錯誤資訊了,通過查詢資料才知道,對於update,insert,delete語句會自動加排它鎖的原因
於是,我又試了試SELECT * from city where id = "1" lock in share mode;
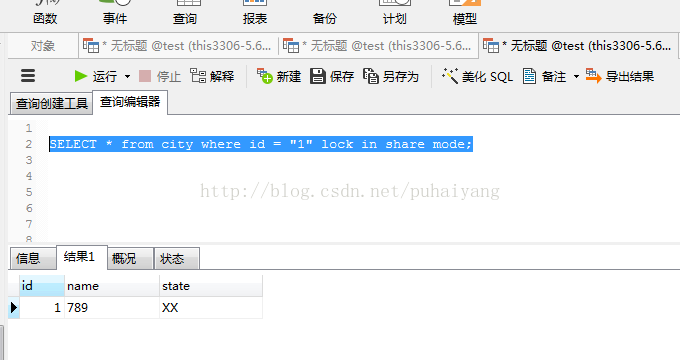
這下成功了。
- 排他鎖。排它鎖與共享鎖相對應,就是指對於多個不同的事務,對同一個資源只能有一把鎖。
與共享鎖型別,在需要執行的語句後面加上for update就可以了。
排他鎖的實現如下:
- 使用場景舉例:以MySQL InnoDB為例
商品t_items表中有一個欄位status,status為1代表商品未被下單,status為2代表商品已經被下單(此時該商品無法再次下單),那麼我們對某個商品下單時必須確保該商品status為1。假設商品的id為1。
如果不採用鎖,那麼操作方法如下:
//1.查詢出商品資訊
select status from t_items where id=1;
//2.根據商品資訊生成訂單,並插入訂單表 t_orders
insert into t_orders (id,goods_id) values (null,1);
//3.修改商品status為2
update t_items set status=2;但是上面這種場景在高併發訪問的情況下很可能會出現問題。例如當第一步操作中,查詢出來的商品status為1。但是當我們執行第三步Update操作的時候,有可能出現其他人先一步對商品下單把t_items中的status修改為2了,但是我們並不知道資料已經被修改了,這樣就可能造成同一個商品被下單2次,使得資料不一致。所以說這種方式是不安全的。
- 使用悲觀鎖來解決問題
在上面的場景中,商品資訊從查詢出來到修改,中間有一個處理訂單的過程,使用悲觀鎖的原理就是,當我們在查詢出t_items資訊後就把當前的資料鎖定,直到我們修改完畢後再解鎖。那麼在這個過程中,因為t_items被鎖定了,就不會出現有第三者來對其進行修改了。需要注意的是,要使用悲觀鎖,我們必須關閉mysql資料庫的自動提交屬性,因為MySQL預設使用autocommit模式,也就是說,當你執行一個更新操作後,MySQL會立刻將結果進行提交。我們可以使用命令設定MySQL為非autocommit模式:set autocommit=0;
設定完autocommit後,我們就可以執行我們的正常業務了。具體如下:
//0.開始事務
begin;/begin work;/start transaction; (三者選一就可以)
//1.查詢出商品資訊
select status from t_items where id=1 for update;
//2.根據商品資訊生成訂單
insert into t_orders (id,goods_id) values (null,1);
//3.修改商品status為2
update t_items set status=2;
//4.提交事務
commit;/commit work;上面的begin/commit為事務的開始和結束,因為在前一步我們關閉了mysql的autocommit,所以需要手動控制事務的提交。
上面的第一步我們執行了一次查詢操作:select status from t_items where id=1 for update;與普通查詢不一樣的是,我們使用了select…for update的方式,這樣就通過資料庫實現了悲觀鎖。此時在t_items表中,id為1的那條資料就被我們鎖定了,其它的事務必須等本次事務提交之後才能執行。這樣我們可以保證當前的資料不會被其它事務修改(其他事務不能讀也不能修改當前的資料)。需要注意的是,在事務中,只有SELECT ... FOR UPDATE 或LOCK IN SHARE MODE 操作同一個資料時才會等待其它事務結束後才執行,一般SELECT ... 則不受此影響。拿上面的例項來說,當我執行select status from t_items where id=1 for update;後。我在另外的事務中如果再次執行select status from t_items where id=1 for update;則第二個事務會一直等待第一個事務的提交,此時第二個查詢處於阻塞的狀態,但是如果我是在第二個事務中執行select status from t_items where id=1;則能正常查詢出資料,不會受第一個事務的影響。
- Row Lock與Table Lock
使用select…for update會把資料給鎖住,不過我們需要注意一些鎖的級別,MySQL InnoDB預設Row-Level Lock,所以只有「明確」地指定主鍵或者索引,MySQL 才會執行Row lock (只鎖住被選取的資料) ,否則MySQL 將會執行Table Lock (將整個資料表單給鎖住。舉例如下:
1、select * from t_items where id=1 for update;
這條語句明確指定主鍵(id=1),並且有此資料(id=1的資料存在),則採用row lock。只鎖定當前這條資料。
2、select * from t_items where id=3 for update;
這條語句明確指定主鍵,但是卻查無此資料,此時不會產生lock(沒有元資料,又去lock誰呢?)。
3、select * from t_items where name='手機' for update;
這條語句沒有指定資料的主鍵,那麼此時產生table lock,即在當前事務提交前整張資料表的所有欄位將無法被查詢。
4、select * from t_items where id>0 for update; 或者select * from t_items where id<>1 for update;(注:<>在SQL中表示不等於)
上述兩條語句的主鍵都不明確,也會產生table lock。
5、select * from t_items where status=1 for update;(假設為status欄位添加了索引)
這條語句明確指定了索引,並且有此資料,則產生row lock。
6、select * from t_items where status=3 for update;(假設為status欄位添加了索引)
這條語句明確指定索引,但是根據索引查無此資料,也就不會產生lock。
感謝這三位博主做的貢獻!