
Java集合詳解5:深入理解LinkedHashMap和LRU緩存
今天我們來深入探索一下LinkedHashMap的底層原理,並且使用linkedhashmap來實現LRU緩存。
具體代碼在我的GitHub中可以找到
https://github.com/h2pl/MyTech
文章首發於我的個人博客:
https://h2pl.github.io/2018/05/11/collection5
更多關於Java後端學習的內容請到我的CSDN博客上查看:https://blog.csdn.net/a724888
摘要:
HashMap和雙向鏈表合二為一即是LinkedHashMap。所謂LinkedHashMap,其落腳點在HashMap,因此更準確地說,它是一個將所有Entry節點鏈入一個雙向鏈表的HashMap。
由於LinkedHashMap是HashMap的子類,所以LinkedHashMap自然會擁有HashMap的所有特性。比如,LinkedHashMap的元素存取過程基本與HashMap基本類似,只是在細節實現上稍有不同。當然,這是由LinkedHashMap本身的特性所決定的,因為它額外維護了一個雙向鏈表用於保持叠代順序。
此外,LinkedHashMap可以很好的支持LRU算法,筆者在第七節便在LinkedHashMap的基礎上實現了一個能夠很好支持LRU的結構。
友情提示:
本文所有關於 LinkedHashMap 的源碼都是基於 JDK 1.6 的,不同 JDK 版本之間也許會有些許差異,但不影響我們對 LinkedHashMap 的數據結構、原理等整體的把握和了解。後面會講解1.8對於LinkedHashMap的改動。
由於 LinkedHashMap 是 HashMap 的子類,所以其具有HashMap的所有特性,這一點在源碼共用上體現的尤為突出。因此,讀者在閱讀本文之前,最好對 HashMap 有一個較為深入的了解和回顧,否則很可能會導致事倍功半。可以參考我之前關於hashmap的文章。
LinkedHashMap 概述
筆者曾提到,HashMap 是 Java Collection Framework 的重要成員,也是Map族(如下圖所示)中我們最為常用的一種。不過遺憾的是,HashMap是無序的,也就是說,叠代HashMap所得到的元素順序並不是它們最初放置到HashMap的順序。
HashMap的這一缺點往往會造成諸多不便,因為在有些場景中,我們確需要用到一個可以保持插入順序的Map。慶幸的是,JDK為我們解決了這個問題,它為HashMap提供了一個子類 —— LinkedHashMap。雖然LinkedHashMap增加了時間和空間上的開銷,但是它通過維護一個額外的雙向鏈表保證了叠代順序。
特別地,該叠代順序可以是插入順序,也可以是訪問順序。因此,根據鏈表中元素的順序可以將LinkedHashMap分為:保持插入順序的LinkedHashMap和保持訪問順序的LinkedHashMap,其中LinkedHashMap的默認實現是按插入順序排序的。
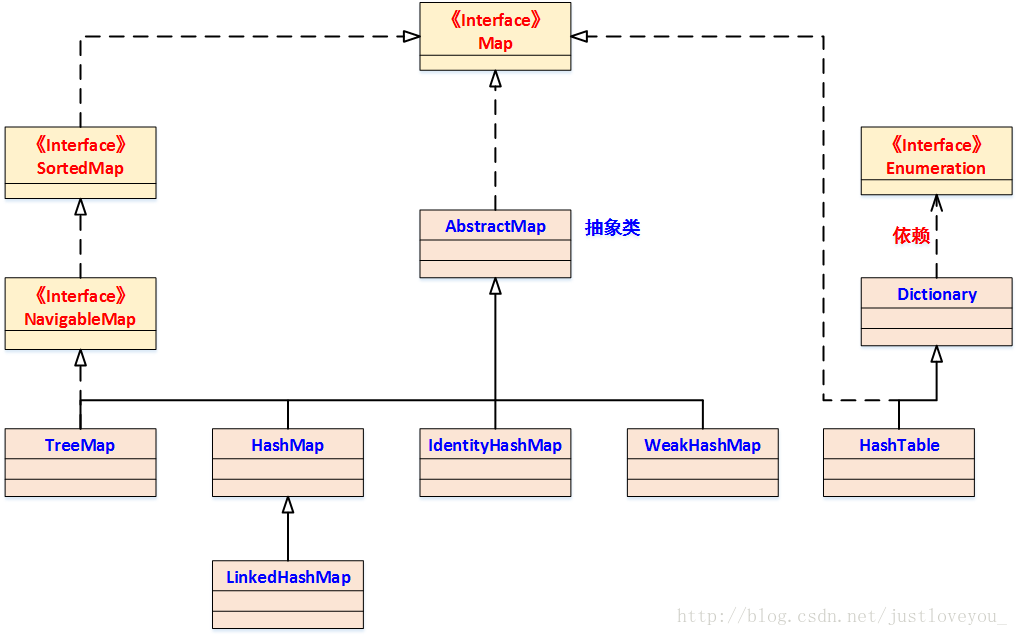
本質上,HashMap和雙向鏈表合二為一即是LinkedHashMap。所謂LinkedHashMap,其落腳點在HashMap,因此更準確地說,它是一個將所有Entry節點鏈入一個雙向鏈表雙向鏈表的HashMap。
在LinkedHashMapMap中,所有put進來的Entry都保存在如下面第一個圖所示的哈希表中,但由於它又額外定義了一個以head為頭結點的雙向鏈表(如下面第二個圖所示),因此對於每次put進來Entry,除了將其保存到哈希表中對應的位置上之外,還會將其插入到雙向鏈表的尾部。
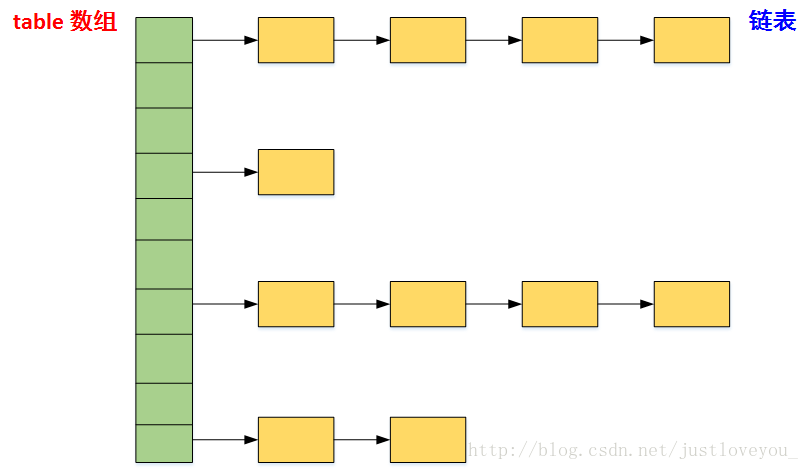
更直觀地,下圖很好地還原了LinkedHashMap的原貌:HashMap和雙向鏈表的密切配合和分工合作造就了LinkedHashMap。特別需要註意的是,next用於維護HashMap各個桶中的Entry鏈,before、after用於維護LinkedHashMap的雙向鏈表,雖然它們的作用對象都是Entry,但是各自分離,是兩碼事兒。
[
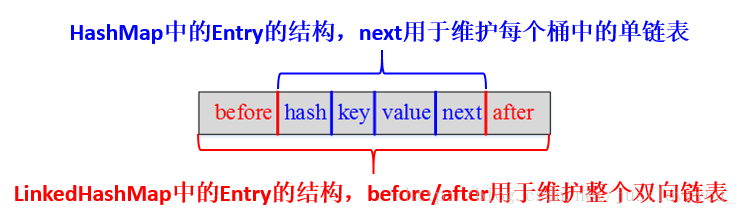
](https://img-blog.csdn.net/20170512160734275?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvanVzdGxvdmV5b3Vf/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast) 其中,HashMap與LinkedHashMap的Entry結構示意圖如下圖所示:
特別地,由於LinkedHashMap是HashMap的子類,所以LinkedHashMap自然會擁有HashMap的所有特性。比如,==LinkedHashMap也最多只允許一條Entry的鍵為Null(多條會覆蓋),但允許多條Entry的值為Null。== 此外,LinkedHashMap 也是 Map 的一個非同步的實現。此外,LinkedHashMap還可以用來實現LRU (Least recently used, 最近最少使用)算法,這個問題會在下文的特別談到。
LinkedHashMap 在 JDK 中的定義
類結構定義
LinkedHashMap繼承於HashMap,其在JDK中的定義為:
public class LinkedHashMap<K,V> extends HashMap<K,V>
implements Map<K,V> {
?
...
}
成員變量定義
與HashMap相比,LinkedHashMap增加了兩個屬性用於保證叠代順序,分別是 雙向鏈表頭結點header 和 標誌位accessOrder (值為true時,表示按照訪問順序叠代;值為false時,表示按照插入順序叠代)。
/**
* The head of the doubly linked list.
*/
private transient Entry<K,V> header; // 雙向鏈表的表頭元素
?
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
private final boolean accessOrder; //true表示按照訪問順序叠代,false時表示按照插入順序(默認)
成員方法定義
從下圖我們可以看出,LinkedHashMap中並增加沒有額外方法。也就是說,LinkedHashMap與HashMap在操作上大致相同,只是在實現細節上略有不同罷了。

基本元素 Entry
LinkedHashMap采用的hash算法和HashMap相同,但是它重新定義了Entry。LinkedHashMap中的Entry增加了兩個指針 before 和 after,它們分別用於維護雙向鏈接列表。特別需要註意的是,next用於維護HashMap各個桶中Entry的連接順序,before、after用於維護Entry插入的先後順序的,源代碼如下:
private static class Entry<K,V> extends HashMap.Entry<K,V> {
?
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
?
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
}
形象地,HashMap與LinkedHashMap的Entry結構示意圖如下圖所示:
LinkedHashMap 的構造函數
LinkedHashMap 一共提供了五個構造函數,它們都是在HashMap的構造函數的基礎上實現的,除了默認空參數構造方法,下面這個構造函數包含了大部分其他構造方法使用的參數,就不一一列舉了。
LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
該構造函數意在構造一個指定初始容量和指定負載因子的具有指定叠代順序的LinkedHashMap,其源碼如下:
/**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor); // 調用HashMap對應的構造函數
this.accessOrder = accessOrder; // 叠代順序的默認值,false插入順序
}
初始容量 和負載因子是影響HashMap性能的兩個重要參數。同樣地,它們也是影響LinkedHashMap性能的兩個重要參數。此外,LinkedHashMap 增加了雙向鏈表頭結點 header和標誌位 accessOrder兩個屬性用於保證叠代順序。
LinkedHashMap(Map<? extends K, ? extends V> m)
該構造函數意在構造一個與指定 Map 具有相同映射的 LinkedHashMap,其 初始容量不小於 16 (具體依賴於指定Map的大小),負載因子是 0.75,是 Java Collection Framework 規範推薦提供的,其源碼如下:
/**
* Constructs an insertion-ordered <tt>LinkedHashMap</tt> instance with
* the same mappings as the specified map. The <tt>LinkedHashMap</tt>
* instance is created with a default load factor (0.75) and an initial
* capacity sufficient to hold the mappings in the specified map.
*
* @param m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
*/
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m); // 調用HashMap對應的構造函數
accessOrder = false; // 叠代順序的默認值
}
init 方法
從上面的五種構造函數我們可以看出,無論采用何種方式創建LinkedHashMap,其都會調用HashMap相應的構造函數。事實上,不管調用HashMap的哪個構造函數,HashMap的構造函數都會在最後調用一個init()方法進行初始化,只不過這個方法在HashMap中是一個空實現,而在LinkedHashMap中重寫了它用於初始化它所維護的雙向鏈表。例如,HashMap的參數為空的構造函數以及init方法的源碼如下:
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
/**
* Initialization hook for subclasses. This method is called
* in all constructors and pseudo-constructors (clone, readObject)
* after HashMap has been initialized but before any entries have
* been inserted. (In the absence of this method, readObject would
* require explicit knowledge of subclasses.)
*/
void init() {
}
在LinkedHashMap中,它重寫了init方法以便初始化雙向列表,源碼如下:
/**
* Called by superclass constructors and pseudoconstructors (clone,
* readObject) before any entries are inserted into the map. Initializes
* the chain.
*/
void init() {
header = new Entry<K,V>(-1, null, null, null);
header.before = header.after = header;
}
因此,我們在創建LinkedHashMap的同時就會不知不覺地對雙向鏈表進行初始化。
LinkedHashMap 的數據結構
本質上,LinkedHashMap = HashMap + 雙向鏈表,也就是說,HashMap和雙向鏈表合二為一即是LinkedHashMap。
也可以這樣理解,LinkedHashMap 在不對HashMap做任何改變的基礎上,給HashMap的任意兩個節點間加了兩條連線(before指針和after指針),使這些節點形成一個雙向鏈表。
在LinkedHashMapMap中,所有put進來的Entry都保存在HashMap中,但由於它又額外定義了一個以head為頭結點的空的雙向鏈表,因此對於每次put進來Entry還會將其插入到雙向鏈表的尾部。
LinkedHashMap 的快速存取
我們知道,在HashMap中最常用的兩個操作就是:put(Key,Value) 和 get(Key)。同樣地,在 LinkedHashMap 中最常用的也是這兩個操作。
對於put(Key,Value)方法而言,LinkedHashMap完全繼承了HashMap的 put(Key,Value) 方法,只是對put(Key,Value)方法所調用的recordAccess方法和addEntry方法進行了重寫;對於get(Key)方法而言,LinkedHashMap則直接對它進行了重寫。
下面我們結合JDK源碼看 LinkedHashMap 的存取實現。
LinkedHashMap 的存儲實現 : put(key, vlaue)
上面談到,LinkedHashMap沒有對 put(key,vlaue) 方法進行任何直接的修改,完全繼承了HashMap的 put(Key,Value) 方法,其源碼如下:
public V put(K key, V value) {
//當key為null時,調用putForNullKey方法,並將該鍵值對保存到table的第一個位置
if (key == null)
return putForNullKey(value);
//根據key的hashCode計算hash值
int hash = hash(key.hashCode());
//計算該鍵值對在數組中的存儲位置(哪個桶)
int i = indexFor(hash, table.length);
//在table的第i個桶上進行叠代,尋找 key 保存的位置
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//判斷該條鏈上是否存在hash值相同且key值相等的映射,若存在,則直接覆蓋 value,並返回舊value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this); // LinkedHashMap重寫了Entry中的recordAccess方法--- (1)
return oldValue; // 返回舊值
}
}
modCount++; //修改次數增加1,快速失敗機制
//原Map中無該映射,將該添加至該鏈的鏈頭
addEntry(hash, key, value, i); // LinkedHashMap重寫了HashMap中的createEntry方法 ---- (2)
return null;
}
上述源碼反映了LinkedHashMap與HashMap保存數據的過程。特別地,在LinkedHashMap中,它對addEntry方法和Entry的recordAccess方法進行了重寫。下面我們對比地看一下LinkedHashMap 和HashMap的addEntry方法的具體實現:
/**
* This override alters behavior of superclass put method. It causes newly
* allocated entry to get inserted at the end of the linked list and
* removes the eldest entry if appropriate.
*
* LinkedHashMap中的addEntry方法
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
//創建新的Entry,並插入到LinkedHashMap中
createEntry(hash, key, value, bucketIndex); // 重寫了HashMap中的createEntry方法
//雙向鏈表的第一個有效節點(header後的那個節點)為最近最少使用的節點,這個是用來支持LRU算法
Entry<K,V> eldest = header.after;
//如果有必要,則刪除掉該近期最少使用的節點,
//這要看對removeEldestEntry的覆寫,由於默認為false,因此默認是不做任何處理的。
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
//擴容到原來的2倍
if (size >= threshold)
resize(2 * table.length);
}
}
-------------------------------我是分割線------------------------------------
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*
* HashMap中的addEntry方法
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
//獲取bucketIndex處的Entry
Entry<K,V> e = table[bucketIndex];
//將新創建的 Entry 放入 bucketIndex 索引處,並讓新的 Entry 指向原來的 Entry
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//若HashMap中元素的個數超過極限了,則容量擴大兩倍
if (size++ >= threshold)
resize(2 * table.length);
}
由於LinkedHashMap本身維護了插入的先後順序,因此其可以用來做緩存,14~19行的操作就是用來支持LRU算法的,這裏暫時不用去關心它。此外,在LinkedHashMap的addEntry方法中,它重寫了HashMap中的createEntry方法,我們接著看一下createEntry方法:
void createEntry(int hash, K key, V value, int bucketIndex) {
// 向哈希表中插入Entry,這點與HashMap中相同
//創建新的Entry並將其鏈入到數組對應桶的鏈表的頭結點處,
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
//在每次向哈希表插入Entry的同時,都會將其插入到雙向鏈表的尾部,
//這樣就按照Entry插入LinkedHashMap的先後順序來叠代元素(LinkedHashMap根據雙向鏈表重寫了叠代器)
//同時,新put進來的Entry是最近訪問的Entry,把其放在鏈表末尾 ,也符合LRU算法的實現
e.addBefore(header);
size++;
}
由以上源碼我們可以知道,在LinkedHashMap中向哈希表中插入新Entry的同時,還會通過Entry的addBefore方法將其鏈入到雙向鏈表中。其中,addBefore方法本質上是一個雙向鏈表的插入操作,其源碼如下:
//在雙向鏈表中,將當前的Entry插入到existingEntry(header)的前面
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
到此為止,我們分析了在LinkedHashMap中put一條鍵值對的完整過程。總的來說,相比HashMap而言,LinkedHashMap在向哈希表添加一個鍵值對的同時,也會將其鏈入到它所維護的雙向鏈表中,以便設定叠代順序。
LinkedHashMap 的擴容操作 : resize()
在HashMap中,我們知道隨著HashMap中元素的數量越來越多,發生碰撞的概率將越來越大,所產生的子鏈長度就會越來越長,這樣勢必會影響HashMap的存取速度。
為了保證HashMap的效率,系統必須要在某個臨界點進行擴容處理,該臨界點就是HashMap中元素的數量在數值上等於threshold(table數組長度*加載因子)。
但是,不得不說,擴容是一個非常耗時的過程,因為它需要重新計算這些元素在新table數組中的位置並進行復制處理。所以,如果我們能夠提前預知HashMap中元素的個數,那麽在構造HashMap時預設元素的個數能夠有效的提高HashMap的性能。
同樣的問題也存在於LinkedHashMap中,因為LinkedHashMap本來就是一個HashMap,只是它還將所有Entry節點鏈入到了一個雙向鏈表中。LinkedHashMap完全繼承了HashMap的resize()方法,只是對它所調用的transfer方法進行了重寫。我們先看resize()方法源碼:
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
// 若 oldCapacity 已達到最大值,直接將 threshold 設為 Integer.MAX_VALUE
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return; // 直接返回
}
// 否則,創建一個更大的數組
Entry[] newTable = new Entry[newCapacity];
//將每條Entry重新哈希到新的數組中
transfer(newTable); //LinkedHashMap對它所調用的transfer方法進行了重寫
table = newTable;
threshold = (int)(newCapacity * loadFactor); // 重新設定 threshold
}
從上面代碼中我們可以看出,Map擴容操作的核心在於重哈希。所謂重哈希是指重新計算原HashMap中的元素在新table數組中的位置並進行復制處理的過程。鑒於性能和LinkedHashMap自身特點的考量,LinkedHashMap對重哈希過程(transfer方法)進行了重寫,源碼如下:
/**
* Transfers all entries to new table array. This method is called
* by superclass resize. It is overridden for performance, as it is
* faster to iterate using our linked list.
*/
void transfer(HashMap.Entry[] newTable) {
int newCapacity = newTable.length;
// 與HashMap相比,借助於雙向鏈表的特點進行重哈希使得代碼更加簡潔
for (Entry<K,V> e = header.after; e != header; e = e.after) {
int index = indexFor(e.hash, newCapacity); // 計算每個Entry所在的桶
// 將其鏈入桶中的鏈表
e.next = newTable[index];
newTable[index] = e;
}
}
如上述源碼所示,LinkedHashMap借助於自身維護的雙向鏈表輕松地實現了重哈希操作。
LinkedHashMap 的讀取實現 :get(Object key)
相對於LinkedHashMap的存儲而言,讀取就顯得比較簡單了。LinkedHashMap中重寫了HashMap中的get方法,源碼如下:
public V get(Object key) {
// 根據key獲取對應的Entry,若沒有這樣的Entry,則返回null
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null) // 若不存在這樣的Entry,直接返回
return null;
e.recordAccess(this);
return e.value;
}
/**
* Returns the entry associated with the specified key in the
* HashMap. Returns null if the HashMap contains no mapping
* for the key.
*
* HashMap 中的方法
*
*/
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
在LinkedHashMap的get方法中,通過HashMap中的getEntry方法獲取Entry對象。註意這裏的recordAccess方法,如果鏈表中元素的排序規則是按照插入的先後順序排序的話,該方法什麽也不做;如果鏈表中元素的排序規則是按照訪問的先後順序排序的話,則將e移到鏈表的末尾處,筆者會在後文專門闡述這個問題。
另外,同樣地,調用LinkedHashMap的get(Object key)方法後,若返回值是 NULL,則也存在如下兩種可能:
該 key 對應的值就是 null; HashMap 中不存在該 key。
LinkedHashMap 存取小結
LinkedHashMap的存取過程基本與HashMap基本類似,只是在細節實現上稍有不同,這是由LinkedHashMap本身的特性所決定的,因為它要額外維護一個雙向鏈表用於保持叠代順序。
在put操作上,雖然LinkedHashMap完全繼承了HashMap的put操作,但是在細節上還是做了一定的調整,比如,在LinkedHashMap中向哈希表中插入新Entry的同時,還會通過Entry的addBefore方法將其鏈入到雙向鏈表中。
在擴容操作上,雖然LinkedHashMap完全繼承了HashMap的resize操作,但是鑒於性能和LinkedHashMap自身特點的考量,LinkedHashMap對其中的重哈希過程(transfer方法)進行了重寫。
在讀取操作上,LinkedHashMap中重寫了HashMap中的get方法,通過HashMap中的getEntry方法獲取Entry對象。在此基礎上,進一步獲取指定鍵對應的值。
LinkedHashMap 與 LRU(Least recently used,最近最少使用)算法
到此為止,我們已經分析完了LinkedHashMap的存取實現,這與HashMap大體相同。LinkedHashMap區別於HashMap最大的一個不同點是,前者是有序的,而後者是無序的。為此,LinkedHashMap增加了兩個屬性用於保證順序,分別是雙向鏈表頭結點header和標誌位accessOrder。
我們知道,header是LinkedHashMap所維護的雙向鏈表的頭結點,而accessOrder用於決定具體的叠代順序。實際上,accessOrder標誌位的作用可不像我們描述的這樣簡單,我們接下來仔細分析一波~
我們知道,當accessOrder標誌位為true時,表示雙向鏈表中的元素按照訪問的先後順序排列,可以看到,雖然Entry插入鏈表的順序依然是按照其put到LinkedHashMap中的順序,但put和get方法均有調用recordAccess方法(put方法在key相同時會調用)。
recordAccess方法判斷accessOrder是否為true,如果是,則將當前訪問的Entry(put進來的Entry或get出來的Entry)移到雙向鏈表的尾部(key不相同時,put新Entry時,會調用addEntry,它會調用createEntry,該方法同樣將新插入的元素放入到雙向鏈表的尾部,既符合插入的先後順序,又符合訪問的先後順序,因為這時該Entry也被訪問了);
當標誌位accessOrder的值為false時,表示雙向鏈表中的元素按照Entry插入LinkedHashMap到中的先後順序排序,即每次put到LinkedHashMap中的Entry都放在雙向鏈表的尾部,這樣遍歷雙向鏈表時,Entry的輸出順序便和插入的順序一致,這也是默認的雙向鏈表的存儲順序。
因此,當標誌位accessOrder的值為false時,雖然也會調用recordAccess方法,但不做任何操作。
put操作與標誌位accessOrder
/ 將key/value添加到LinkedHashMap中
public V put(K key, V value) {
// 若key為null,則將該鍵值對添加到table[0]中。
if (key == null)
return putForNullKey(value);
// 若key不為null,則計算該key的哈希值,然後將其添加到該哈希值對應的鏈表中。
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 若key對已經存在,則用新的value取代舊的value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 若key不存在,則將key/value鍵值對添加到table中
modCount++;
//將key/value鍵值對添加到table[i]處
addEntry(hash, key, value, i);
return null;
}
從上述源碼我們可以看到,當要put進來的Entry的key在哈希表中已經在存在時,會調用Entry的recordAccess方法;當該key不存在時,則會調用addEntry方法將新的Entry插入到對應桶的單鏈表的頭部。我們先來看recordAccess方法:
/**
* This method is invoked by the superclass whenever the value
* of a pre-existing entry is read by Map.get or modified by Map.set.
* If the enclosing Map is access-ordered, it moves the entry
* to the end of the list; otherwise, it does nothing.
*/
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//如果鏈表中元素按照訪問順序排序(accessOrder=true),則將當前訪問的Entry移到雙向循環鏈表的尾部,
//如果是按照插入的先後順序排序(accessOrder=true),則不做任何事情。
if (lm.accessOrder) {
lm.modCount++;
//移除當前訪問的Entry
remove();
//將當前訪問的Entry插入到鏈表的尾部
addBefore(lm.header);
}
}
LinkedHashMap重寫了HashMap中的recordAccess方法(HashMap中該方法為空),當調用父類的put方法時,在發現key已經存在時,會調用該方法;當調用自己的get方法時,也會調用到該方法。
該方法提供了LRU算法的實現,它將最近使用的Entry放到雙向循環鏈表的尾部。也就是說,當accessOrder為true時,get方法和put方法都會調用recordAccess方法使得最近使用的Entry移到雙向鏈表的末尾;當accessOrder為默認值false時,從源碼中可以看出recordAccess方法什麽也不會做。我們反過頭來,再看一下addEntry方法:
/**
* This override alters behavior of superclass put method. It causes newly
* allocated entry to get inserted at the end of the linked list and
* removes the eldest entry if appropriate.
*
* LinkedHashMap中的addEntry方法
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
//創建新的Entry,並插入到LinkedHashMap中
createEntry(hash, key, value, bucketIndex); // 重寫了HashMap中的createEntry方法
//雙向鏈表的第一個有效節點(header後的那個節點)為最近最少使用的節點,這是用來支持LRU算法的
Entry<K,V> eldest = header.after;
//如果有必要,則刪除掉該近期最少使用的節點,
//這要看對removeEldestEntry的覆寫,由於默認為false,因此默認是不做任何處理的。
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
//擴容到原來的2倍
if (size >= threshold)
resize(2 * table.length);
}
}
void createEntry(int hash, K key, V value, int bucketIndex) {
// 向哈希表中插入Entry,這點與HashMap中相同
//創建新的Entry並將其鏈入到數組對應桶的鏈表的頭結點處,
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
//在每次向哈希表插入Entry的同時,都會將其插入到雙向鏈表的尾部,
//這樣就按照Entry插入LinkedHashMap的先後順序來叠代元素(LinkedHashMap根據雙向鏈表重寫了叠代器)
//同時,新put進來的Entry是最近訪問的Entry,把其放在鏈表末尾 ,也符合LRU算法的實現
e.addBefore(header);
size++;
}
同樣是將新的Entry鏈入到table中對應桶中的單鏈表中,但可以在createEntry方法中看出,同時也會把新put進來的Entry插入到了雙向鏈表的尾部。 從插入順序的層面來說,新的Entry插入到雙向鏈表的尾部可以實現按照插入的先後順序來叠代Entry,而從訪問順序的層面來說,新put進來的Entry又是最近訪問的Entry,也應該將其放在雙向鏈表的尾部。在上面的addEntry方法中還調用了removeEldestEntry方法,該方法源碼如下:
/**
* Returns <tt>true</tt> if this map should remove its eldest entry.
* This method is invoked by <tt>put</tt> and <tt>putAll</tt> after
* inserting a new entry into the map. It provides the implementor
* with the opportunity to remove the eldest entry each time a new one
* is added. This is useful if the map represents a cache: it allows
* the map to reduce memory consumption by deleting stale entries.
*
* <p>Sample use: this override will allow the map to grow up to 100
* entries and then delete the eldest entry each time a new entry is
* added, maintaining a steady state of 100 entries.
* <pre>
* private static final int MAX_ENTRIES = 100;
*
* protected boolean removeEldestEntry(Map.Entry eldest) {
* return size() > MAX_ENTRIES;
* }
* </pre>
*
* <p>This method typically does not modify the map in any way,
* instead allowing the map to modify itself as directed by its
* return value. It <i>is</i> permitted for this method to modify
* the map directly, but if it does so, it <i>must</i> return
* <tt>false</tt> (indicating that the map should not attempt any
* further modification). The effects of returning <tt>true</tt>
* after modifying the map from within this method are unspecified.
*
* <p>This implementation merely returns <tt>false</tt> (so that this
* map acts like a normal map - the eldest element is never removed).
*
* @param eldest The least recently inserted entry in the map, or if
* this is an access-ordered map, the least recently accessed
* entry. This is the entry that will be removed it this
* method returns <tt>true</tt>. If the map was empty prior
* to the <tt>put</tt> or <tt>putAll</tt> invocation resulting
* in this invocation, this will be the entry that was just
* inserted; in other words, if the map contains a single
* entry, the eldest entry is also the newest.
* @return <tt>true</tt> if the eldest entry should be removed
* from the map; <tt>false</tt> if it should be retained.
*/
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
}
該方法是用來被重寫的,一般地,如果用LinkedHashmap實現LRU算法,就要重寫該方法。比如可以將該方法覆寫為如果設定的內存已滿,則返回true,這樣當再次向LinkedHashMap中putEntry時,在調用的addEntry方法中便會將近期最少使用的節點刪除掉(header後的那個節點)。在第七節,筆者便重寫了該方法並實現了一個名副其實的LRU結構。
get操作與標誌位accessOrder
public V get(Object key) {
// 根據key獲取對應的Entry,若沒有這樣的Entry,則返回null
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null) // 若不存在這樣的Entry,直接返回
return null;
e.recordAccess(this);
return e.value;
}
在LinkedHashMap中進行讀取操作時,一樣也會調用recordAccess方法。上面筆者已經表述的很清楚了,此不贅述。
LinkedListMap與LRU小結
使用LinkedHashMap實現LRU的必要前提是將accessOrder標誌位設為true以便開啟按訪問順序排序的模式。我們可以看到,無論是put方法還是get方法,都會導致目標Entry成為最近訪問的Entry,因此就把該Entry加入到了雙向鏈表的末尾:get方法通過調用recordAccess方法來實現;
put方法在覆蓋已有key的情況下,也是通過調用recordAccess方法來實現,在插入新的Entry時,則是通過createEntry中的addBefore方法來實現。這樣,我們便把最近使用的Entry放入到了雙向鏈表的後面。多次操作後,雙向鏈表前面的Entry便是最近沒有使用的,這樣當節點個數滿的時候,刪除最前面的Entry(head後面的那個Entry)即可,因為它就是最近最少使用的Entry。
使用LinkedHashMap實現LRU算法
如下所示,筆者使用LinkedHashMap實現一個符合LRU算法的數據結構,該結構最多可以緩存6個元素,但元素多余六個時,會自動刪除最近最久沒有被使用的元素,如下所示:
public class LRU<K,V> extends LinkedHashMap<K, V> implements Map<K, V>{
private static final long serialVersionUID = 1L;
public LRU(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor, accessOrder);
}
/**
* @description 重寫LinkedHashMap中的removeEldestEntry方法,當LRU中元素多余6個時,
* 刪除最不經常使用的元素
* @author rico
* @created 2017年5月12日 上午11:32:51
* @param eldest
* @return
* @see java.util.LinkedHashMap#removeEldestEntry(java.util.Map.Entry)
*/
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
// TODO Auto-generated method stub
if(size() > 6){
return true;
}
return false;
}
public static void main(String[] args) {
LRU<Character, Integer> lru = new LRU<Character, Integer>(
16, 0.75f, true);
String s = "abcdefghijkl";
for (int i = 0; i < s.length(); i++) {
lru.put(s.charAt(i), i);
}
System.out.println("LRU中key為h的Entry的值為: " + lru.get(‘h‘));
System.out.println("LRU的大小 :" + lru.size());
System.out.println("LRU :" + lru);
}
}
下圖是程序的運行結果: 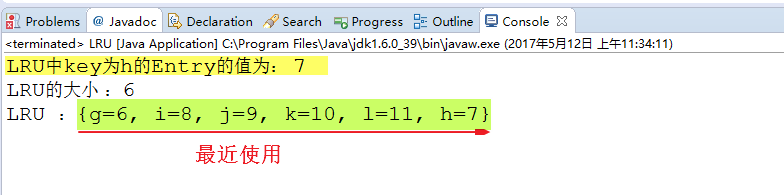
LinkedHashMap 有序性原理分析
如前文所述,LinkedHashMap 增加了雙向鏈表頭結點header 和 標誌位accessOrder兩個屬性用於保證叠代順序。但是要想真正實現其有序性,還差臨門一腳,那就是重寫HashMap 的叠代器,其源碼實現如下:
private abstract class LinkedHashIterator<T> implements Iterator<T> {
Entry<K,V> nextEntry = header.after;
Entry<K,V> lastReturned = null;
/**
* The modCount value that the iterator believes that the backing
* List should have. If this expectation is violated, the iterator
* has detected concurrent modification.
*/
int expectedModCount = modCount;
public boolean hasNext() { // 根據雙向列表判斷
return nextEntry != header;
}
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
LinkedHashMap.this.remove(lastReturned.key);
lastReturned = null;
expectedModCount = modCount;
}
Entry<K,V> nextEntry() { // 叠代輸出雙向鏈表各節點
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == header)
throw new NoSuchElementException();
Entry<K,V> e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}
}
// Key 叠代器,KeySet
private class KeyIterator extends LinkedHashIterator<K> {
public K next() { return nextEntry().getKey(); }
}
// Value 叠代器,Values(Collection)
private class ValueIterator extends LinkedHashIterator<V> {
public V next() { return nextEntry().value; }
}
// Entry 叠代器,EntrySet
private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() { return nextEntry(); }
}
從上述代碼中我們可以知道,LinkedHashMap重寫了HashMap 的叠代器,它使用其維護的雙向鏈表進行叠代輸出。
JDK1.8的改動
原文是基於JDK1.6的實現,實際上JDK1.8對其進行了改動。 首先它刪除了addentry,createenrty等方法(事實上是hashmap的改動影響了它而已)。
linkedhashmap同樣使用了大部分hashmap的增刪改查方法。 新版本linkedhashmap主要是通過對hashmap內置幾個方法重寫來實現lru的。
hashmap不提供實現:
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
linkedhashmap的實現:
處理元素被訪問後的情況
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
處理元素插入後的情況
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
處理元素被刪除後的情況
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
}
另外1.8的hashmap在鏈表長度超過8時自動轉為紅黑樹,會按順序插入鏈表中的元素,可以自定義比較器來定義節點的插入順序。
1.8的linkedhashmap同樣會使用這一特性,當變為紅黑樹以後,節點的先後順序同樣是插入紅黑樹的順序,其雙向鏈表的性質沒有改表,只是原來hashmap的鏈表變成了紅黑樹而已,在此不要混淆。
總結
本文從linkedhashmap的數據結構,以及源碼分析,到最後的LRU緩存實現,比較深入地剖析了linkedhashmap的底層原理。 總結以下幾點:
1 linkedhashmap在hashmap的數組加鏈表結構的基礎上,將所有節點連成了一個雙向鏈表。
2 當主動傳入的accessOrder參數為false時, get方法使用時不會把元素放到雙向鏈表尾部。
3 當主動傳入的accessOrder參數為true時,使用put方法新加入的元素,如果遇到了哈希沖突,並且對key值相同的元素進行了替換,就會被放在雙向鏈表的尾部,當元素超過上限且removeEldestEntry方法返回true時,直接刪除最早元素以便新元素插入。如果沒有沖突直接放入,同樣加入到鏈表尾部。使用get方法時會把get到的元素放入雙向鏈表尾部。
4 linkedhashmap的擴容比hashmap來的方便,因為hashmap需要將原來的每個鏈表的元素分別在新數組進行反向插入鏈化,而linkedhashmap的元素都連在一個鏈表上,可以直接叠代然後插入。
Java集合詳解5:深入理解LinkedHashMap和LRU緩存