
深度學習與計算機視覺[CS231N] 學習筆記(4.1):反向傳播(Backpropagation)
在學習深度學習的過程中,我們常用的一種優化引數的方法就是梯度下降法,而一般情況下,我們搭建的神經網路的結構是:輸入→權重矩陣→損失函式。如下圖所示。
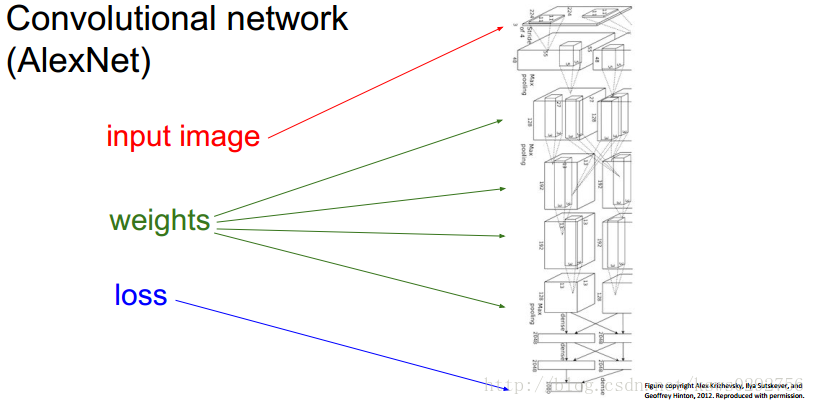
而在給定輸入的情況下,為了使我們的損失函式值達到最小,我們就需要調節權重矩陣,使之滿足條件,於是,就有了本文現在要介紹的深度學習中的一個核心方法——反向傳播。
光聽名字可能不太好理解,下面我們用一個簡單的例子來講解反向傳播是如何工作的(瞭解高數中求導的鏈式法則有助於理解該方法)。
如下圖所示,首先定義一個簡單的函式,它具有3個自變數
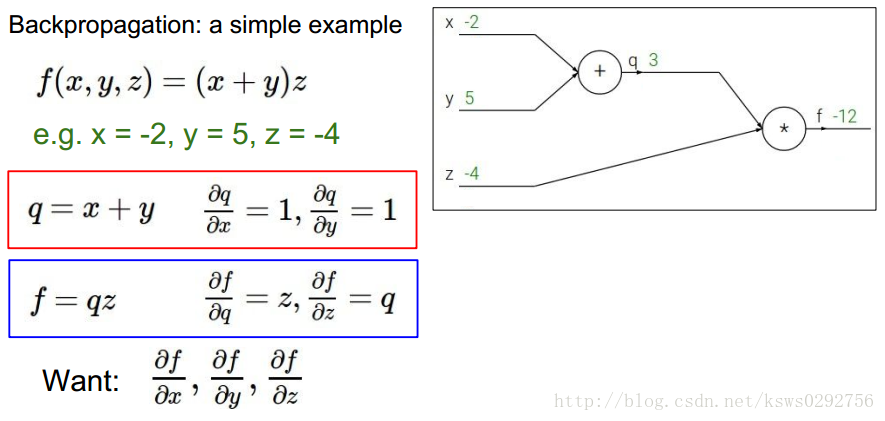
要使用反向傳播方法,我們首先獲取一組給定的樣本值,如下圖所示,假設為
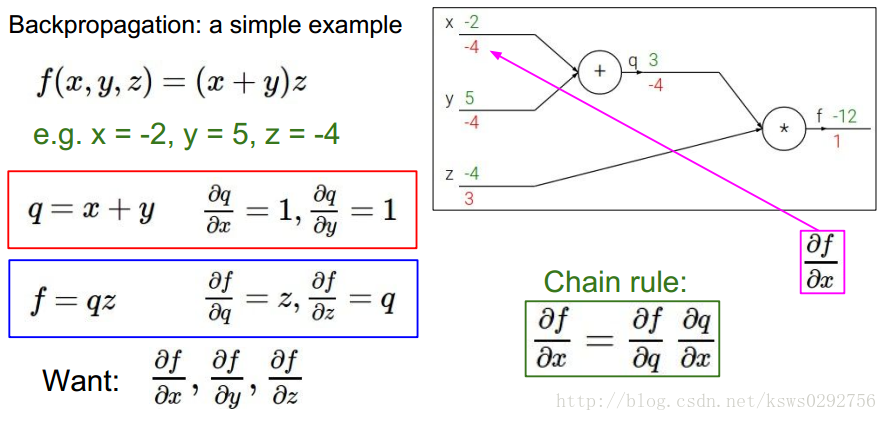
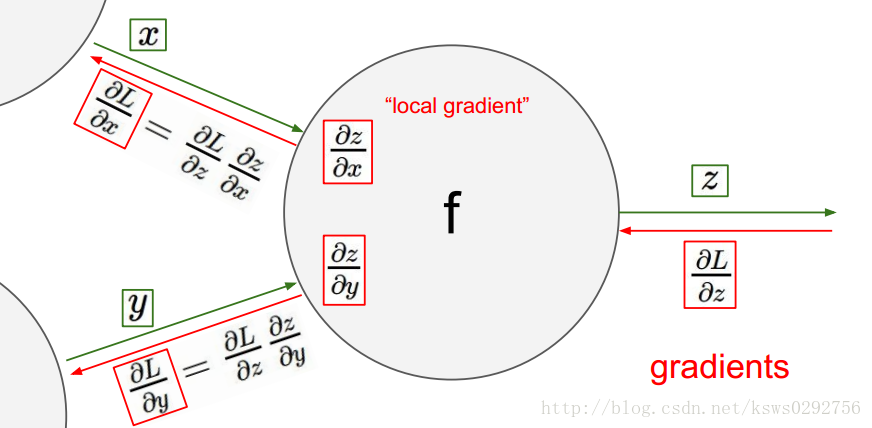
反向傳播的運算流程可以用下面這幅圖來描述,首先是順著綠色的箭頭計算出相應的變數並存儲起來,然後再順著紅色的箭頭算出我們需要的梯度值。
為了說明這種方法確實很有用,我們再列舉另一個比較複雜的函式例子。如下圖所示,我們首先給出函式的具體形式,並計算相應的中間變數和結果變數。
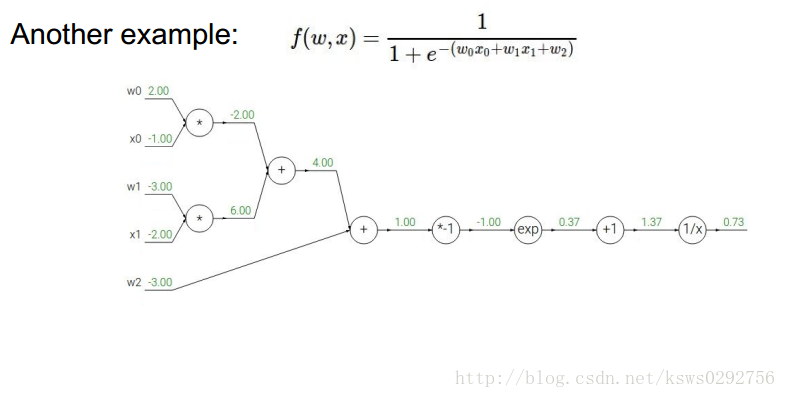
接著,我們根據反向傳播的規則和鏈式法則求出每一個變數對應的梯度值,具體如下圖所示。
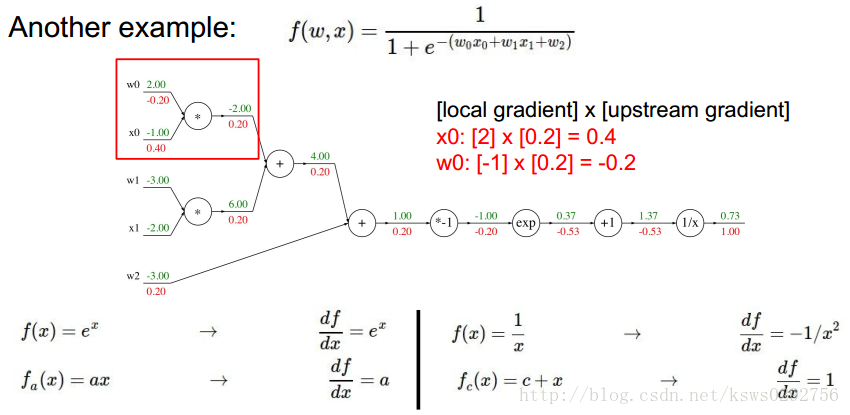
從這裡我們可以看出,如果不使用反向傳播方法而直接去計算梯度的話,過程將會變得十分麻煩,更何況實際中我們使用的函式還要更加複雜!