
Spark學習(二) 之叢集搭建(standalone、HA-standalone、 spark on yarn)
Spark standalone
(一) 安裝過程
1、上傳並解壓縮
tar -zxvf spark-2.3.0-bin-hadoop2.7.tgz -C apps/
2、進入spark/conf修改配置檔案
cp slaves.template slaves
cp spark-env.sh.template spark-env.sh
3、修改 slaves檔案,在其中新增從節點
node02
node03
node04
4、修改 spark-env.sh檔案
# export JAVA_HOME=/opt/software/jdk1.8.0_151 # centOS 7 需要引入JAVA_HOME SPARK_MASTER_IP=node01 master所在節點 SPARK_MASTER_PORT=7077 master資源通訊埠 SPARK_WORKER_CORES=2 worker管理的核數 SPARK_WORKER_MEMORY=800m worker管理的記憶體 SPARK_WORKER_INSTANCES=1 每個節點啟動worker的個數 SPARK_WORKER_DIR=/var/zgl/spark worker的工作目錄 # SPARK_MASTER_WEBUI_PORT=8888 WebUI的埠號,預設為8080,與tomcat衝突
5、進入 sbin 目錄,做如下修改,防止這兩個命令與 hadoop 命令衝突
mv start-all.sh start-spark.sh
mv stop-all.sh stop-spark.sh
6、將配置好的spark安裝包傳送到其他節點和客戶端節點
# scp -r spark-2.3.0 node02:`pwd`
# scp -r spark-2.3.0 node03:`pwd`
# scp -r spark-2.3.0 node04:`pwd`
# scp -r spark-2.3.0 client:`pwd`
7、在 node01 和 client 節點上配置 spark 的環境變數,配置到 ~/.bashrc 中
vim ~/.bashrc
export SPARK_HOME=/opt/zgl/spark-1.6.3
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
(二)啟動
1、先啟動zookeeper叢集
所有zookeeper節點啟動
zkServer.sh start
2、在node01啟動HDFS叢集
start-dfs.sh
3、在 node01 上啟動叢集
start-spark.sh
4、jps 檢查叢集是否啟動
(三)驗證
1、在客戶端提交 spark 提供的 SparkPi 程式(該程式通過概率計算 π 的值)
- 注意提交命令一行寫完,不要換行
任務很可能會因為記憶體不足導致失敗
spark-submit master的url 執行器所使用的記憶體 執行的程式的全類名 程式jar包所在的位置 提供一個引數(引數越大,計算的π值越精準)
spark-submit --master spark://node01:7077 --executor-memory 500m
--class org.apache.spark.examples.SparkPi
/opt/software/spark-2.3.0/lib/spark-examples-2.3.0-hadoop2.6.0.jar
50
2、可以在 node01:8080 WEBUI頁面檢視任務
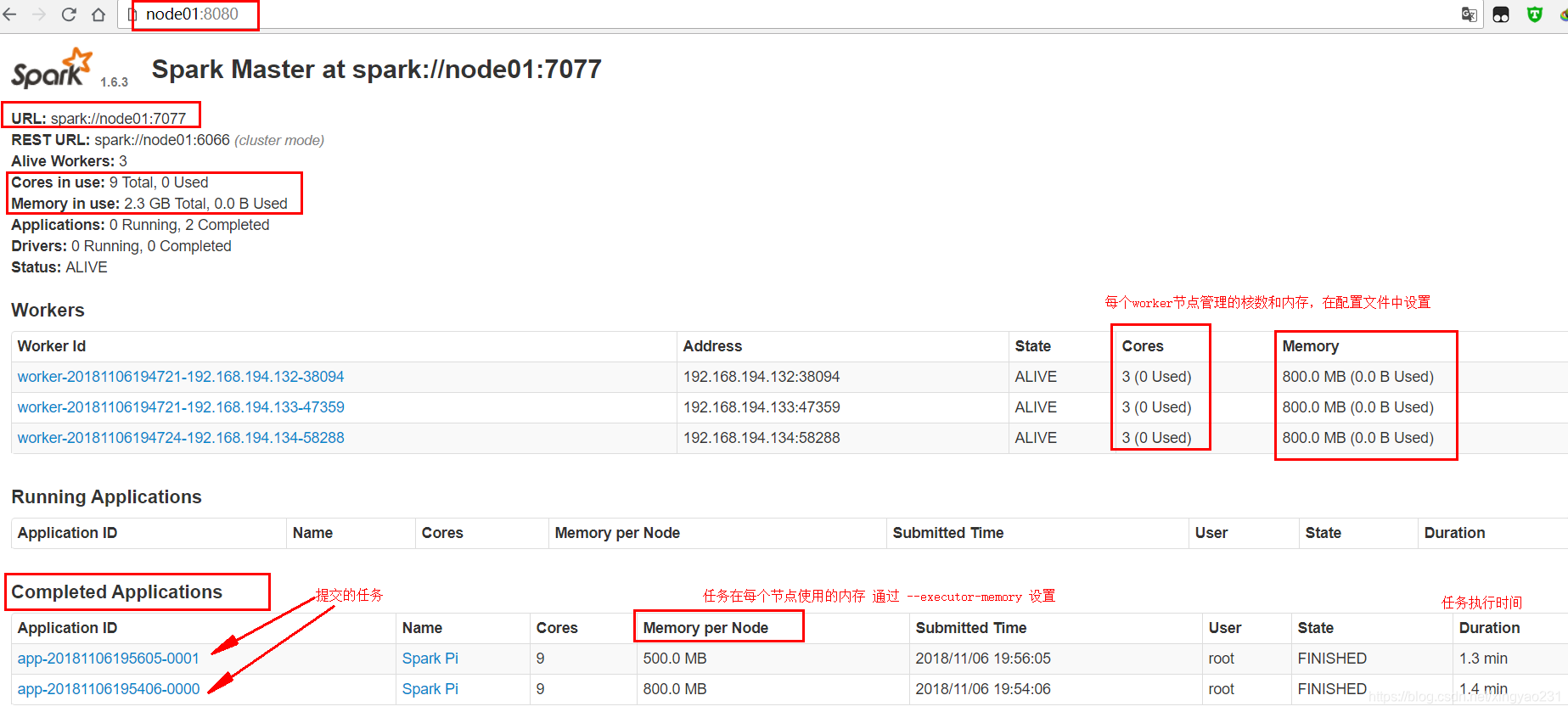
Spark standalone HA
同 HDFS 的 NameNode,YARN 的 ResourceManager 一樣,spark standalone 的 master 也存在單點故障問題,於是同樣也就有了基於 zookeeper 監控的高可用模式(spark standalone 還有一種高可用模式是基於本地檔案系統,主master掛掉後需要手動切換)
主備切換
- spark standalone HA 模式中,master(active) 會將元資料同步到 zookeeper 中,元資料中有 worker,driver 和 application 的資訊
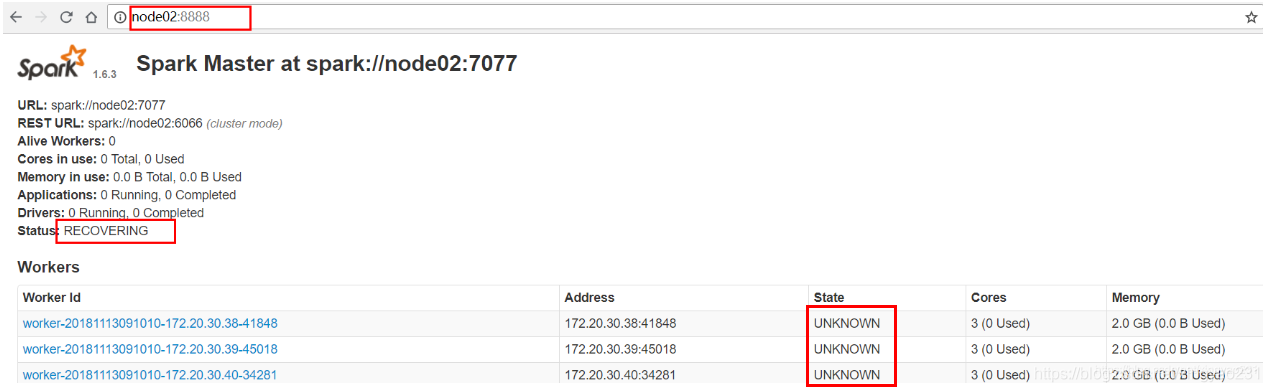
- 當 master(active) 掛掉時,zookeeper 會選舉出一個 master(standby),被選中的 master(standby) 進入恢復狀態 master(recovering)
- master(recovering) 從 zookeeper 讀取元資料,得到元資料後,master(recovering) 會向 worker 節點發送訊息,告知主master已經更換
- 正在正常執行的 worker 在收到通知後,會向 master(recovering) 節點發送響應資訊
- master(recovering) 節點收到響應資訊後,會呼叫自身的completeRecovery()方法,此時未向 master(recovering) 節點發送響應資訊的 worker 節點會被認為已經掛掉,從 workers 中刪除(workers
是儲存 worker 資訊的物件)- 短暫的 completeRecovery 狀態一閃而過,master(completeRecovery) 成為 active 狀態,開始對外提供服務
–主備切換的過程大概需要1~2分鐘,此期間叢集不接受提交任務的請求,但是已經跑在叢集上的任務不會受到影響,會正常執行,這得益於 spark 粗粒度的資源排程
–workers 使用 HashSet 資料結構來儲存 worker 資訊,是為了防止同一臺 worker 節點在 master 中註冊兩次(worker 節點掛掉但是迅速恢復可能會導致此問題)
叢集配置
1、 在上面 standalone 叢集配置的基礎上,先關閉之前開啟的叢集
stop-spark.sh
2、在 node01 節點上對 spark 安裝包中的 spark-env.sh檔案新增如下配置,注意寫在一行,不要手動換行,三個引數間使用空格隔開
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=node02:2181,node03:2181,node04:2181
-Dspark.deploy.zookeeper.dir=/spark"
官網對三個引數的解釋

3、將 spark-env.sh傳送到其他節點,進入 spark 安裝包的 conf 目錄下執行
scp spark-env.sh node02:`pwd`
scp spark-env.sh node03:`pwd`
scp spark-env.sh node04:`pwd`
scp spark-env.sh client:`pwd`
4、選用 node02 節點作為備用的 master 節點,在 node02 節點的 spark 安裝包中的 spark-env.sh檔案中修改 SPARK_MASTER_IP,令 SPARK_MASTER_IP=node02
5、啟動zookeeper,spark叢集
zkServer.sh start
start-spark.sh
6、node02啟動master(standby狀態)
start-master.sh
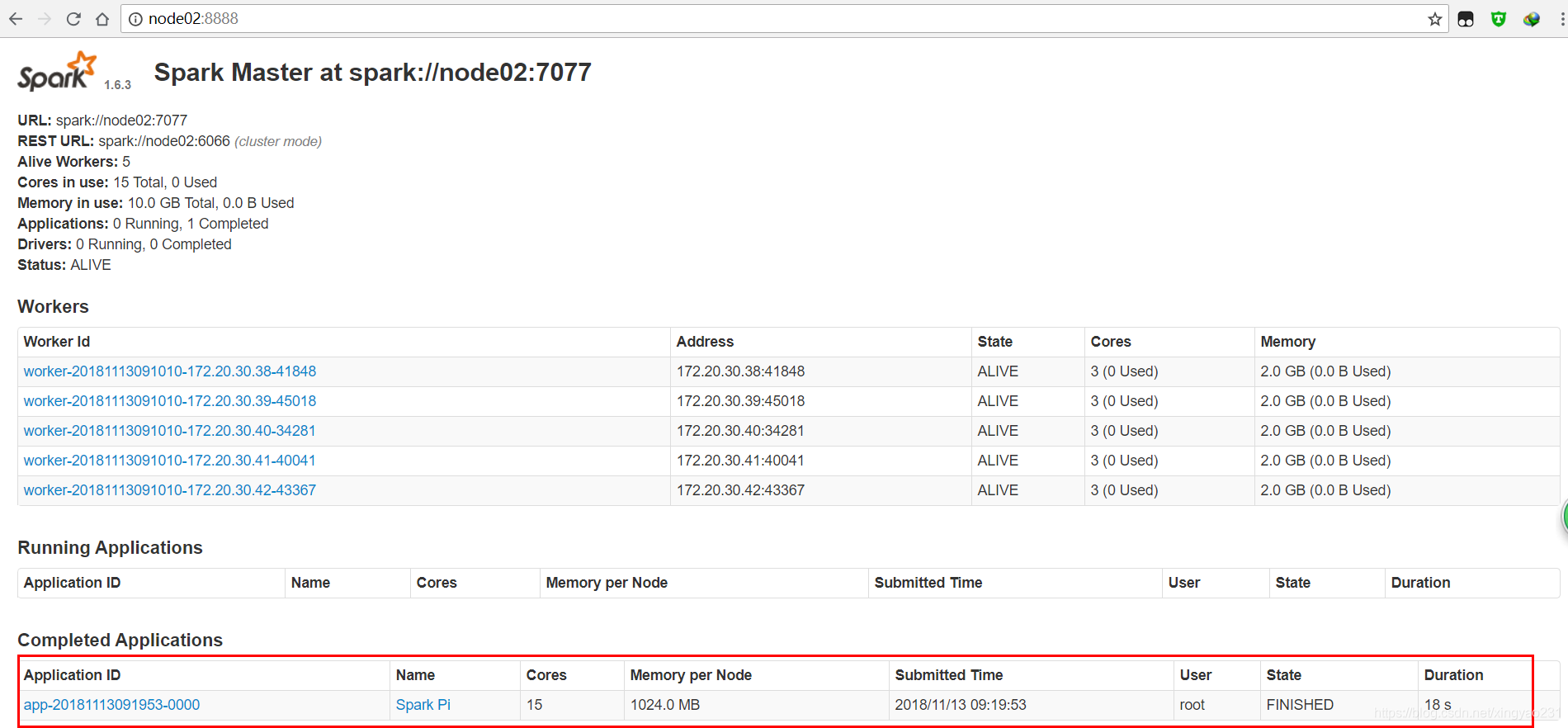
7、node02:8888 WEBUI頁面檢視節點狀態資訊
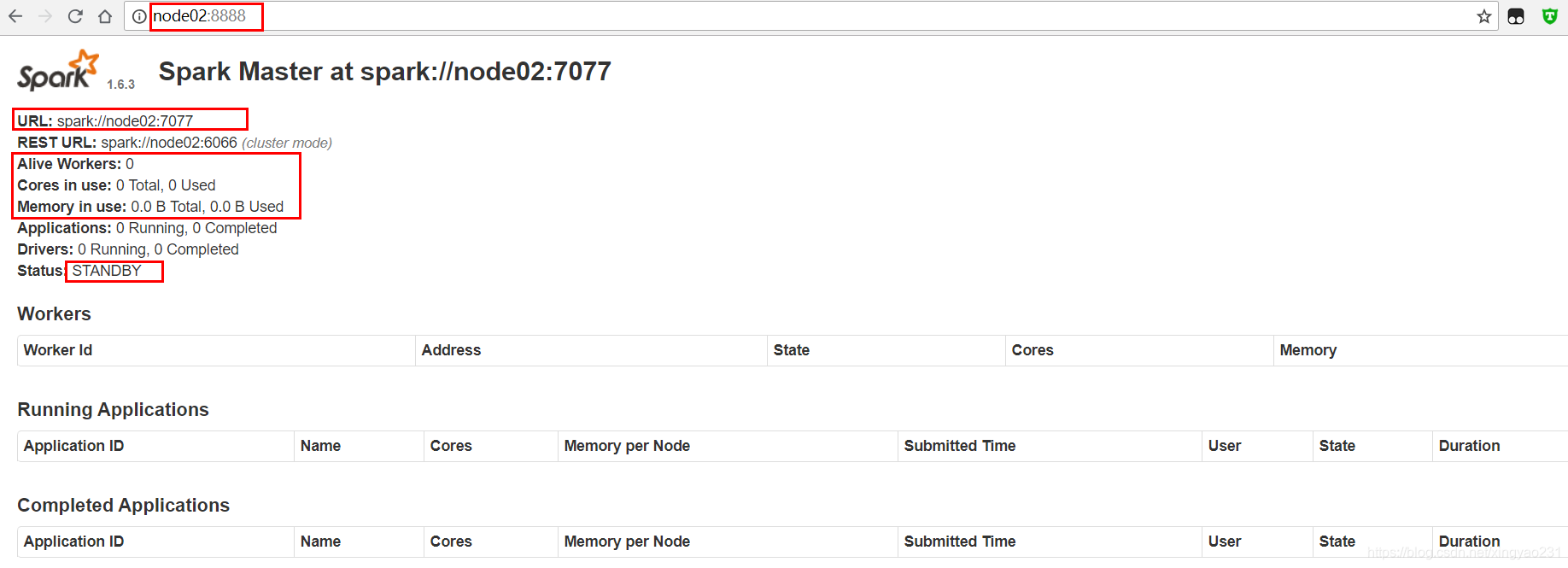
將 nodeo1 上的 master 程序 kill 掉,然後觀察 master(standby) 的狀態變化
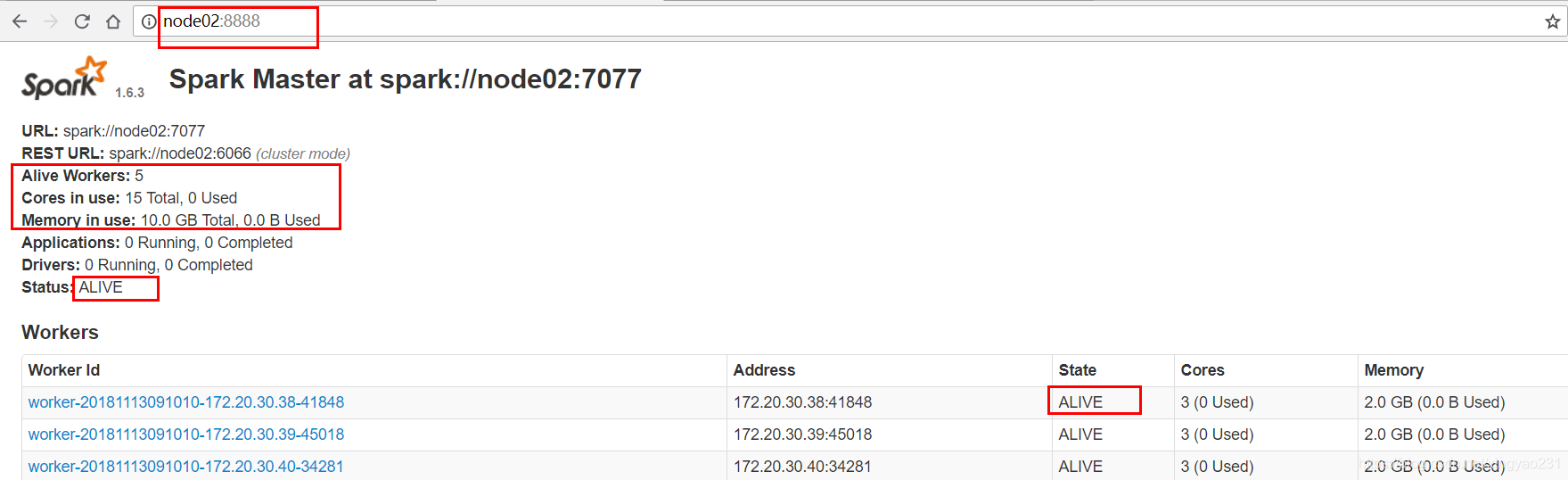
在客戶端提交 spark 提供的 SparkPi 程式
spark-submit --master spark://node01:7077,node02:7077
--class org.apache.spark.examples.SparkPi
/opt/software/spark-1.6.3/lib/spark-examples-1.6.3-hadoop2.6.0.jar
100
在 WEBUI 頁面檢視任務
Spark on YARN
spark 應用程式跑在 yarn 叢集上很簡單,只需要在客戶端有 spark 安裝包就可以了(用來提交 spark 應用程式)
- 在客戶端 spark 安裝包中配置 spark-env.sh檔案,新增如下配置資訊
HADOOP_CONF_DIR=/opt/zgl/hadoop-2.6.5/etc/hadoop
- 開啟 HDFS叢集和 YARN叢集,客戶端提交的應用程式 jar 包會託管在 hdfs 上
- 在客戶端提交 spark 提供的 SparkPi 程式
spark-submit --master yarn
--class org.apache.spark.examples.SparkPi
/opt/zgl/spark-1.6.3/lib/spark-examples-1.6.3-hadoop2.6.0.jar
10000
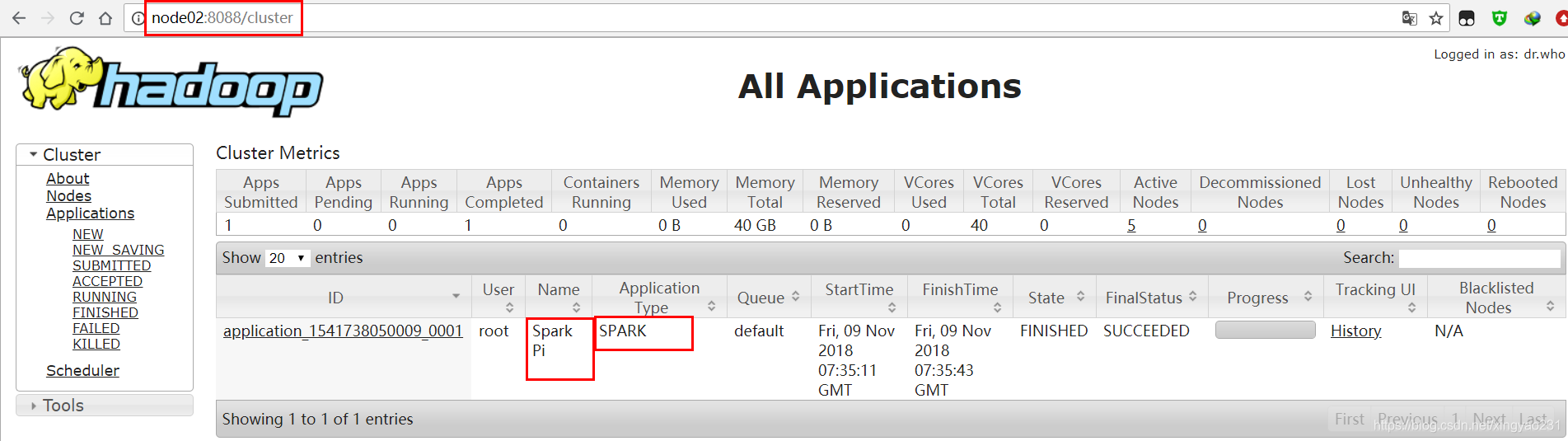
- 在 yarn 的 WebUI 頁面檢視任務
提交任務可能會報下面這個異常,主要是因為虛擬記憶體超限, contrainer 被 kill,從而導致任務結束
Yarn application has already ended! It might have been killed or unable to launch application master
可以通過在 hadoop 安裝包的 yarn-site.xml 檔案中配置如下資訊來解決
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
<description>是否檢查每個任務正使用的實體記憶體量,如果超過預設值則將其殺死,預設是true </description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>