
試一試dgraph
在github上下載了0.7.7版本的tar包dgraph-linux-amd64-v0.7.7.tar.gz。我是在ubuntu16.04下試的。解壓後可以執行,但是在瀏覽器裡輸入localhost:8080看不到頁面。 在ubuntu14.04和ubuntu12.04下不能執行。
沒辦法拉一個docker試試吧。直接拉很慢,還是配置一下daocloud的映象源吧。
如果你跟我一樣,用的是ubuntu16.04。請參考這篇文章ubuntu16.04設定daocloud映象源。因為daocloud官網沒有說在ubunt16.04上怎麼配置映象源。
設定好並且重啟docker服務之後。
sudo docker pull dgraph/dgraph:v0.7.7
目前github上release最新的版本就是v0.7.7。docker裡已經有1.0版本了,docker竟然比github新,出乎意料。
拉完了之後 sudo docker images看一下。
然後mkdir -p ~/dgraph
sudo docker run -it -p 9090:8080 -v ~/dgraph:/dgraph --name dgraph dgraph/dgraph:v0.7.7 dgraph --bindall=true-p 9090:8080 意思是把容器裡8080埠對映到主機的9090埠上。
-v ~/dgraph:/dgraph是對映資料卷。將來dgraph的資料和日誌都會寫到主機的~/dgraph/目錄下
–name dgraph是給容器起一個名字叫dgraph
dgraph/dgraph:v0.7.7 意思是從這個映象啟動一個容器
dgraph是容器起來後執行的命令。我們知道啟動dgraph的命令就是 dgraph
–bindall=true 不知道什麼意思。猜測是繫結 0.0.0.0到8080
這樣dgraph的環境就搭好了。有docker就是好啊。
瀏覽器輸入http://192.168.x.x:9090 看到如下畫面:
哎喲乍一看很像neo4j的畫面哦。 畫面也比cayley好看一些。 cayley的頁面太簡陋了。
輸入框裡輸入:
mutation {
set {
_:luke <name> "Luke Skywalker" .
_:leia <name> "Princess Leia" .
_:han <name> "Han Solo" .
_:lucas <name> "George Lucas" .
_:irvin <name 點選“Run”
再輸入如下內容,新增schema:
mutation {
schema {
name: string @index .
release_date: date @index .
revenue: float .
running_time: int .
}
}點選“Run”
現在可以查詢了,輸入如下內容可以查詢名稱為星球大戰並且在1980年後發行的電影:
{
me(func:allofterms(name, "Star Wars")) @filter(ge(release_date, "1980")) {
name
release_date
revenue
running_time
director {
name
}
starring {
name
}
}
}哎喲,不錯哦,頁面挺漂亮的。這小清新的配色比neo4j和cayley好看多了。
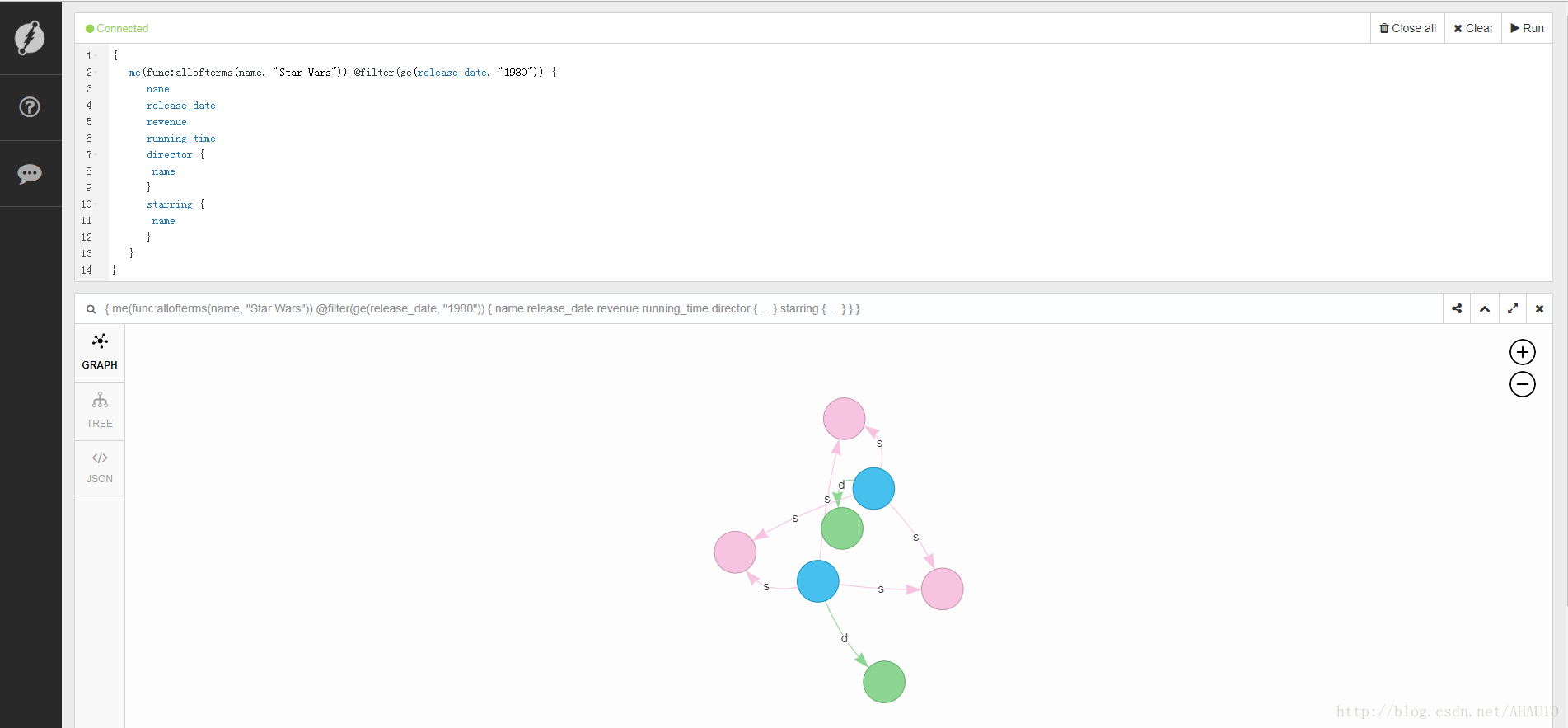
咦?才提交了這麼一點資料,有這麼多邊嗎?
不像neo4j, dgraph的vertex裡沒有property這概念。所有的property都是邊。
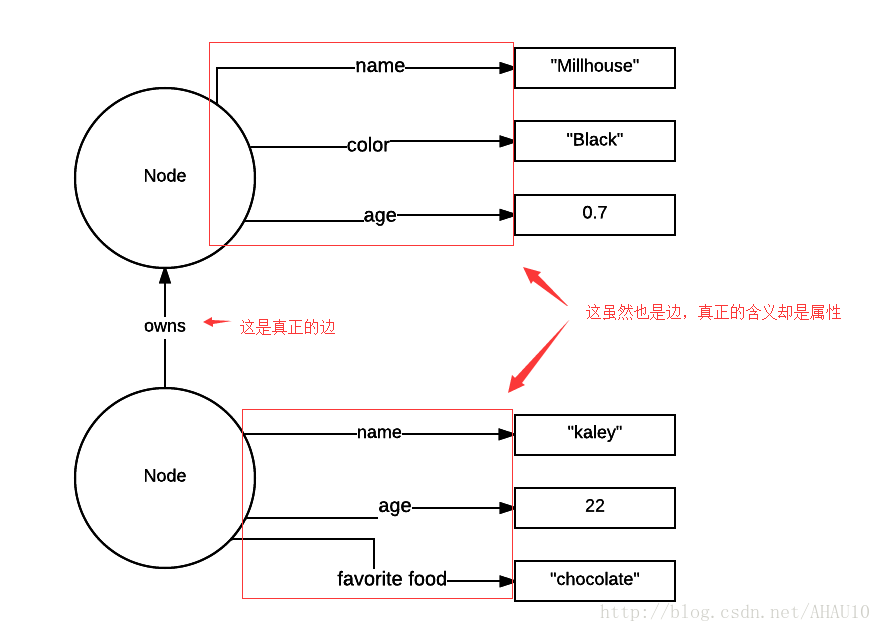
不要覺得這很傻。在stackoverflow上看到有人問如何讓vertex的屬性支援多值?有不少人都說了,給vertex新增多條邊。用這種辦法讓vertex支援多值。
而且據我所知,新增邊和查邊的時候比屬性快一些。別以為查邊很慢,有鄰接表和其它的策略,查邊是非常快的。要不然圖資料的優勢怎麼體現出來?
雖然直接在vertex裡新增屬性更直觀一些。我相信dgraph這樣做一定是考慮了很多因素的。別忘了dgraph比neo4j出來的晚,是有後發優勢的。
dgraph是支援分片的。在微博上看到有人說dgraph是通過邊來切圖的。圖資料庫分片是個NP完全的問題。目前沒有非常好的切圖策略。
不管dgraph怎麼實現分片的。至少人家是支援分片的。而且是底層設計上就考慮了分片的。
dgraph還有一個問題,就是需要你自己維護主鍵唯一性。上面的mutation操作中,
_:luke是一個偽id。 dgraph內部會為你生成一個唯一的id。如果你想通過id就能把這個vertex查出來,然後更新之。那麼需要你自己去維護id的唯一性。 dgraph的設計理念是儘量保持簡單(贊同)。 所以現在的問題是導資料的時候想更新節點可能沒那麼容易了。 mutation中每一句結尾的 “.”,相當於SQL裡的分號。
我想通過全文檢索把節點查出來怎麼辦?dgraph支援fulltext索引,不過很可惜,目前不支援中文。如果它是用java寫的,那麼我們可以快速的新增一個smartcn或者IK。但是人家使用go語言寫的。哪位大神能搞一個go語言的中文分詞,在此先行謝過。