
linux下grep用法
阿新 • • 發佈:2019-02-09
linux grep命令
不定時更新中。。。
新建一個test.txt,裡面內容如下:
[email protected]:~/shell# cat test.txt
a
bc
def
ght12
abc999
tydvl658
123
456
789abc

新建一個text.txt
[[email protected] shell]# cat test.txt
a
bcd
1
233
abc123
defrt456
123abc
12568teids
abcfrt568
[[email protected] shell]#
 示例2:
[[email protected] shell]# grep -n --color '[a]' test.txt
1:a
5:abc123
7:123abc
9:abcfrt568
示例2:
[[email protected] shell]# grep -n --color '[a]' test.txt
1:a
5:abc123
7:123abc
9:abcfrt568
 示例3:
[[email protected] shell]# grep -n --color '[1 2 3]' test.txt
3:1
4:233
5:abc123
7:123abc
8:12568teids
示例3:
[[email protected] shell]# grep -n --color '[1 2 3]' test.txt
3:1
4:233
5:abc123
7:123abc
8:12568teids
 示例4:
[[email protected] shell]# grep -n --color '[1-3]' test.txt
3:1
4:233
5:abc123
7:123abc
8:12568teids
[[email protected] shell]#
示例4:
[[email protected] shell]# grep -n --color '[1-3]' test.txt
3:1
4:233
5:abc123
7:123abc
8:12568teids
[[email protected] shell]#
 示例5:
[[email protected] shell]# grep -n --color '[1-3 a-b]' test.txt
1:a
2:bcd
3:1
4:233
5:abc123
7:123abc
8:12568teids
9:abcfrt568
[[email protected] shell]#
示例5:
[[email protected] shell]# grep -n --color '[1-3 a-b]' test.txt
1:a
2:bcd
3:1
4:233
5:abc123
7:123abc
8:12568teids
9:abcfrt568
[[email protected] shell]#

 下面例子的意思是:匹配字串”23”,但是 ‘3’ 被匹配的次數 >= 0
[[email protected] shell]# grep -n --color '23*' test.txt
4:233
5:abc123
7:123abc
8:12568teids
[[email protected] shell]#
下面例子的意思是:匹配字串”23”,但是 ‘3’ 被匹配的次數 >= 0
[[email protected] shell]# grep -n --color '23*' test.txt
4:233
5:abc123
7:123abc
8:12568teids
[[email protected] shell]#

 下面例子的意思是:匹配字串”33”但是 第二個字元‘3’只能匹配0次或者1次,因此實際匹配到的字元有“33 ”和 ‘3’這兩種
[[email protected] shell]# grep -n --color '33\?' test.txt
4:233
5:abc123
7:123abc
下面例子的意思是:匹配字串”33”但是 第二個字元‘3’只能匹配0次或者1次,因此實際匹配到的字元有“33 ”和 ‘3’這兩種
[[email protected] shell]# grep -n --color '33\?' test.txt
4:233
5:abc123
7:123abc
 下面例子的意思是:匹配字串”23”但是 第二個字元‘3’只能匹配0次或者1次,因此實際匹配到的字元有“23 ”和 ‘2’這兩種
[[email protected] shell]# grep -n --color '23\?' test.txt
4:233
5:abc123
7:123abc
8:12568teids
[[email protected] shell]#
下面例子的意思是:匹配字串”23”但是 第二個字元‘3’只能匹配0次或者1次,因此實際匹配到的字元有“23 ”和 ‘2’這兩種
[[email protected] shell]# grep -n --color '23\?' test.txt
4:233
5:abc123
7:123abc
8:12568teids
[[email protected] shell]#

一、作用
百度二、格式
grep [options] ‘pattern’ filename三、option主要引數
下面所列的引數主要是一些常用的引數。| 編號 | 引數 | 解釋 |
| 1 | --version or -V | grep的版本 |
| 2 | -A 數字N | 找到所有的匹配行,並顯示匹配行後N行 |
| 3 | -B 數字N | 找到所有的匹配行,並顯示匹配行前面N行 |
| 4 | -b | 顯示匹配到的字元在檔案中的偏移地址 |
| 5 | -c | 顯示有多少行被匹配到 |
| 6 | --color | 把匹配到的字元用顏色顯示出來 |
| 7 | -e |
可以使用多個正則表示式 |
| 8 | -f FILEA FILEB | FILEA在FILEAB中的匹配 |
| 9 | -i | 不區分大小寫針對單個字元 |
| 10 | -m 數字N | 最多匹配N個後停止 |
| 11 | -n | 列印行號 |
| 12 | -o | 只打印出匹配到的字元 |
| 13 | -R | 搜尋子目錄 |
| 14 | -v | 顯示不包括查詢字元的所有行 |
1.--version
顯示grep的版本號 [[email protected]2. -A 數字N
找到所有的匹配行,並顯示匹配行後面N行 [[email protected] shell]# grep -A 2 "a" test.txt a //匹配字元’a’ 後面兩行 bc def -- abc999 tydvl658 123 -- 789abc [[email protected] shell]#3.-B 數字N
找到所有的匹配行,並顯示匹配行前面N行 [[email protected] shell]# grep -B 2 "a" test.txt a -- def ght12 abc999 //匹配字元’a’ 前面兩行 -- 123 456 789abc [[email protected] shell]#4.-b
顯示匹配到的字元在檔案中的偏移地址 [[email protected] shell]# grep -b "a" test.txt 0:a //在檔案中的偏移地址 15:abc999 39:789abc [[email protected] shell]#5. -c
顯示有多少行被匹配到 [[email protected] shell]# grep -c "a" test.txt 3 //在整個txt中,共有三個字元’a’被匹配到 [[email protected] shell]#6.--color
把匹配到的字元用顏色顯示出來
7.-e
可以使用多個正則表示式 [[email protected] shell]# grep -e "a" -e "1" test.txt a //查詢txt中字元 ‘a’ 和 字元 ‘1’ ght12 abc999 123 789abc [[email protected] shell]#8.-f FILEA FILEB
FILEA在FILEAB中的匹配 [[email protected] shell]# cat test.txt a bc def ght12 abc999 tydvl658 123 456 789abc [[email protected] shell]# cat test1.txt abc [[email protected] shell]# grep -f test.txt test1.txt abc [[email protected] shell]# grep -f test1.txt test.txt abc999 789abc [[email protected] shell]#9.-i
不區分大小寫 [[email protected] shell]# cat test1.txt ab Ac 6356 AKF57 [[email protected] shell]# grep -i "a" test1.txt ab //找出所有字元’a’ 並且不區分大小寫 Ac AKF57 [[email protected] shell]#10.-m 數字N
最多匹配N個後停止 [[email protected] shell]# grep -m 2 "a" test.txt a abc999 //匹配2個後停止 [[email protected] shell]#11.-n
列印行號 [[email protected] shell]# grep -n -m 2 "a" test.txt 1:a //打印出匹配字元的行號 5:abc999 [[email protected] shell]#12.-o
會列印匹配到的字元 [[email protected] shell]# grep -n -o "a" test.txt 1:a 5:a 9:a [[email protected] shell]#13.-R
搜尋子目錄 [[email protected] shell]# mkdir 666 //建立一個子目錄 [[email protected] shell]# cp test.txt 666/ //將txt複製到子目錄裡面 [[email protected] shell]# ls 666 test1.txt test.txt //當前目錄有兩個txt和一個子目錄 [[email protected] shell]# grep "a" * test1.txt:ab //只在當前目錄查詢字元’a’ test.txt:a test.txt:abc999 test.txt:789abc [[email protected] shell]# grep -R "a" * 666/test.txt:a //在當前目錄和子目錄查詢字元’a’ 666/test.txt:abc999 666/test.txt:789abc test1.txt:ab test.txt:a test.txt:abc999 test.txt:789abc [[email protected] shell]#14.-v
顯示不包括查詢字元的所有行 [[email protected] shell]# grep -v "a" test.txt bc def ght12 tydvl658 123 456 [[email protected] shell]#四、pattern主要引數
| 編號 | 引數 | 解釋 |
| 1 | ^ | 匹配行首 |
| 2 | $ | 匹配行尾 |
| 3 | [ ] or [ n - n ] | 匹配[ ]內字元 |
| 4 | . | 匹配任意的單字元 |
| 5 | * | 緊跟一個單字元,表示匹配0個或者多個此字元 |
| 6 | \ | 用來遮蔽元字元的特殊含義 |
| 7 | \? | 匹配前面的字元0次或者1次 |
| 8 | \+ | 匹配前面的字元1次或者多次 |
| 9 | X\{m\} | 匹配字元X m次 |
| 10 | X\{m,\} | 匹配字元X 最少m次 |
| 11 | X\{m,n\} | 匹配字元X m---n 次 |
| 12 | \(666\) | 標記匹配字元,如666 被標記為1,隨後想使用666,直接以 1 代替即可 |
| 13 | \| | 表示或的關係 |
1.^
匹配行首 [[email protected] shell]# grep -n '^a' test.txt 1:a //匹配以字元’a’開頭的 5:abc123 9:abcfrt568 [[email protected] shell]# [[email protected] shell]# grep -n '^abc' test.txt 5:abc123 //匹配以字串”abc”開頭的 9:abcfrt568 [[email protected] shell]#2.$
匹配行尾 [[email protected] shell]# grep -n '33$' test.txt 4:233 //匹配以字串”33”結束的 [[email protected] shell]# grep -n '3$' test.txt 4:233 //匹配以字元’3’結束的 5:abc123 [[email protected] shell]#3.[ ]
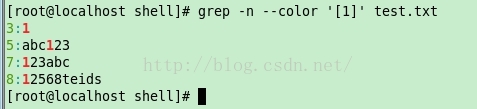
匹配 [ ]內的字元, 可以使用單字元 如 [ 1] 即匹配含有字元’1’的字串(示例1), 如 [ a] 即匹配含有字元’a’的字串(示例2), 如 [ 1 2 3 ] 即匹配含有字元’1’ 或者 ’2’ 或者’3’ 的字串(示例3), 也可以使用字元序列,用字元 ‘-’ 代表字元序列 如 [ 1-3 ] 即匹配含有字元’1’ 或者 ’2’ 或者’3’ 的字串(示例4) 如 [ 1-3 a-b] 即匹配含有字元’1’ 或者 ’2’ 或者’3’ 或者 ’a’ 或者 ’b’的字串(示例5) 示例1: [[email protected] shell]# grep -n --color '[1]' test.txt 3:1 5:abc123 7:123abc 8:12568teids
示例2:
[[email protected] shell]# grep -n --color '[a]' test.txt
1:a
5:abc123
7:123abc
9:abcfrt568
示例3:
[[email protected] shell]# grep -n --color '[1 2 3]' test.txt
3:1
4:233
5:abc123
7:123abc
8:12568teids
示例4:
[[email protected] shell]# grep -n --color '[1-3]' test.txt
3:1
4:233
5:abc123
7:123abc
8:12568teids
[[email protected] shell]#
示例5:
[[email protected] shell]# grep -n --color '[1-3 a-b]' test.txt
1:a
2:bcd
3:1
4:233
5:abc123
7:123abc
8:12568teids
9:abcfrt568
[[email protected] shell]#
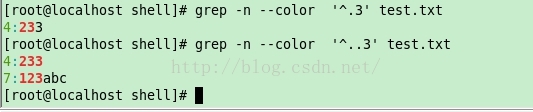
4. .
匹配任意的單字元 [[email protected] shell]# grep -n --color '^.3' test.txt 4:233 //任意字元開頭然後第二個字元為 ‘3’ [[email protected] shell]# grep -n --color '^..3' test.txt 4:233 //任意兩個字元開頭,然後第三個字元為 ‘3’ 7:123abc [[email protected] shell]#
5. *
緊跟一個單字元,表示匹配0個或者多個此字元 下面例子的意思是,匹配字元’3’ 0次或者多次 [[email protected] shell]# grep -n --color '3*' test.txt 1:a 2:bcd 3:1 4:233 5:abc123 6:defrt456 7:123abc 8:12568teids 9:abcfrt568 10:3
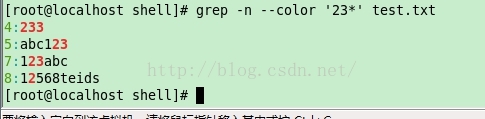
下面例子的意思是:匹配字串”23”,但是 ‘3’ 被匹配的次數 >= 0
[[email protected] shell]# grep -n --color '23*' test.txt
4:233
5:abc123
7:123abc
8:12568teids
[[email protected] shell]#
6. \
用來遮蔽元字元的特殊含義 下面的例子的意思是 在字串 "365.398" 中,查詢’.’這個字元,而不是任意單字元 [[email protected] shell]# echo "365.398" | grep --color '.' 365.398 [[email protected] shell]# echo "365.398" | grep --color '\.' 365.398 [[email protected] shell]#
7. \?
匹配前面的字元0 次或者 多次 [[email protected] shell]# grep -n --color '3\?' test.txt 1:a 2:bcd 3:1 4:233 5:abc123 6:defrt456 7:123abc 8:12568teids 9:abcfrt568
下面例子的意思是:匹配字串”33”但是 第二個字元‘3’只能匹配0次或者1次,因此實際匹配到的字元有“33 ”和 ‘3’這兩種
[[email protected] shell]# grep -n --color '33\?' test.txt
4:233
5:abc123
7:123abc
下面例子的意思是:匹配字串”23”但是 第二個字元‘3’只能匹配0次或者1次,因此實際匹配到的字元有“23 ”和 ‘2’這兩種
[[email protected] shell]# grep -n --color '23\?' test.txt
4:233
5:abc123
7:123abc
8:12568teids
[[email protected] shell]#