
Centos7.2 搭建ELK-5.6.4日誌分析平臺(一)
日誌作為系統的重要的除錯分析檔案,是我們開發除錯,運維監控,找錯等。所以,必須需要建立一個日誌分析平臺,用於監控分析各個系統的日誌。而業內最有知名的日誌分析平臺,則是ELK系統。是一整套完整的日誌分析體系,官方地址為:https://www.elastic.co/cn/products
ELK,是Elasticsearch+Logstash+Kibana三個軟體的簡稱,久而久之則稱之為ELK,但是現在隨著版本更迭,要完善整個日誌分析系統,不單隻需要這三個軟體,而是多個軟體的配合協助,構成一個完整的系統。
系統架構圖如下:
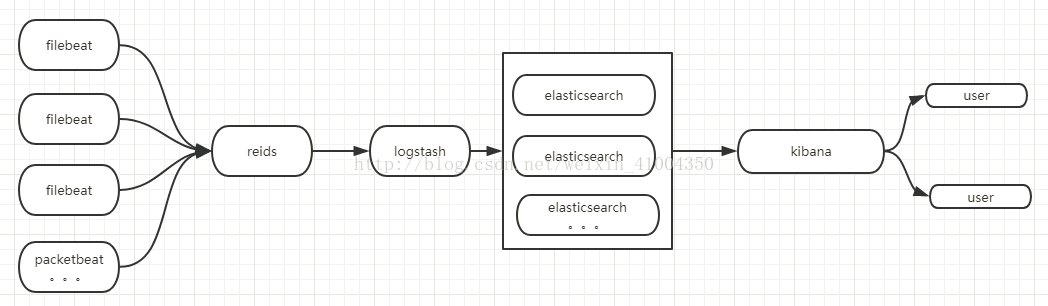
ELK從5.0版本開始,統一版本資訊,一套系統對應的版本號一致,以前的舊版本就很亂,各種相容問題也比較麻煩,現在就簡單多了,具體環境如下:
filebeat-5.64: 5.6.4版本,替代以前舊版本的logstash-agent,用於安裝在各個主機,收集各個主機上的日誌,實時採集內容發到redis佇列。現在版本將這個採集器統一合併為beat,其中包含多個不用的軟體,類似filebeat是採集日誌檔案,packetbeat是監控主機流量。。。等等,可以根據需求,安裝不同的外掛。
redis-4.0.1: 這裡用redis做佇列, 用做暫緩filebeat傳過來的資料,避免因瞬間的傳輸量的飆升導致logstash的崩潰,類似於一個管道,讓logstash能夠定量的處理資料,不會受峰值流量的影響。
logstash-5.6.4: logstash是日誌採集何過濾的軟體,雖然也具備filebeat一樣的日誌採集功能,但logstash需要執行在java虛擬機器上,更重量級,消耗資源。所以不推薦用開做資料採集,只用來做資料過濾,比如將採集的日誌,通過各種外掛,進行分類,分端,轉換成json類的易於分析分類的資訊,將其儲存在elasticsearch中。
elasticsearch-5.6.4:是一個基於json的資料儲存分析軟體,可以分散式的拓展部署,儲存的資料,用於kibana呼叫,實現日誌的分析,展示。
kibana-5.6.4:日誌分析平臺的視覺化介面,可以在這個介面上對系統進行管理,資料分析,監控等。配合x-pack中的其他外掛,可以實現各種拓展功能。
x-pack: x-pack是一個拓展功能集合的外掛包,可以實現安全防護,實時監控,生成報告等拓展功能,用的最多的就是安全防護功能,預設的ELK是沒有密碼認證的,直接就可以登陸的,載入了x-pack後,則可以使用密碼認證,證書認證等功能,來實現ELK軟體之間的相互認證。
整個ELK系統都是基於java的,5.64版本需要jdk環境1.8以上。這裡我的是jdk_1.8_144,作業系統:centos-7.2。jdk環境的配置,這裡就不贅述了,參考我之前的博文:
下面記錄一下整個elk日誌分析平臺的搭建流程。與遇到的一些問題,和注意事項。
1. 下載基礎的elk三個軟體,elasticsearch,logstash,kibana。下載地址去官網找:https://www.elastic.co/cn/products
logstash下載地址:https://artifacts.elastic.co/downloads/logstash/logstash-6.0.0.tar.gz
elasticsearch下載地址:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.0.0.tar.gz
kibana下載地址:https://artifacts.elastic.co/downloads/kibana/kibana-6.0.0-linux-x86_64.tar.gz
2. 在你選擇安裝elk的伺服器上,選擇一個地方,解壓三個軟體,我這裡是放在/usr/local/下面
$ cd /usr/local/ #進入我放elk的目錄
$ mkdir ELK #建立ELK資料夾,用於存放elk軟體
$ tar -zxvf /usr/lcoal/ELK/logstash-6.0.0.tar.gz ## 解壓各個軟體,下同。
$ tar -zxvf /usr/local/ELK/elasticsearch-6.0.0.tar.gz
$ tar -zxvf /usr/local/ELK/kibana-6.0.0-linux-x86_64.tar.gz3. 先安裝elasticsearch資料儲存器。用於資料儲存,可以分散式部署。上一步解壓後,直接修改配置檔案,則可以啟動。這裡我用了兩臺主機坐了一個elasticsearch的叢集,如果有需求可以根據需求,增加更多的機器用於儲存資料,增加elasticsearch的節點
主機IP分別為:192.168.9.89 192.168.9.90
$ vim /usr/local/ELK/elasticsearch/config/elasticsearch.yml ## 編輯配置檔案
# ---------------------------------- Cluster -----------------------------------
cluster.name: ES-cluster ##設定叢集名稱,叢集內的節點都要設定相同,可自定義
# ------------------------------------ Node ------------------------------------
node.name: ES-02 ## 節點名稱,自定義,各個節點不可相同
node.master: true ## 是否作為master節點
node.data: true ## 是否作為資料節點
node.ingest: true ## 是否作為ingest節點,ingest節點則可以對資料進行加工,類似logstash的功能,定義一個管道,在索引資料時,通過指定管道進行過濾,再展示出來
# ---------------------------------- Network -----------------------------------
network.host: 192.168.9.90 ## 本機IP
http.port: 9200 ## 埠,預設9200
# --------------------------------- Discovery ----------------------------------
discovery.zen.ping.unicast.hosts: ["192.168.9.89","192.168.9.90"] ## 此叢集內所有節點的IP地址,這裡沒有使用自動發現,而是指定地址發現,因為規模較小
discovery.zen.minimum_master_nodes: 1 ##設定這個引數來保證叢集中的節點可以知道其它N個有master資格的節點,預設為1,推薦設定為叢集master節點數/2 +1 。有一定的防止腦裂的功能。
按上述配置配置完成所有節點後,啟動elasticsearch還是會報錯,最常見的報錯有如下幾種原由,根據日誌報錯資訊可以很容易分辨原由:
1.檔案最大開啟數沒有65536,解決辦法:修改系統最大檔案開啟數
vim /etc/security/limits.conf ##新增如下兩行,儲存後重新登陸使用者及生效
* soft nofile 65536
* hard nofile 655362.vm.mx_map_count 太小,沒有262144
vim /etc/sysctl.conf # 新增下面一行
vm.max_map_count = 262144
systcl -p ## 載入配置3. 記憶體不足,elasticsearch預設是使用2G記憶體,在jvm的配置裡可以自定義配置,在上述配置中我沒有配置鎖定記憶體,但如果有需要配置鎖定記憶體,則很可能會報錯鎖定記憶體不足,解決辦法,修改最大鎖定記憶體。
vim /etc/security/limits.conf ## 新增下面一行,儲存退出,重新登陸生效
work - memlock unlimitedOK,一一解決了這些問題後,就可以正常啟動elasticsearch了,分別啟動各個節點,檢視日誌,顯示成功啟動,選舉出master即可。啟動命令:
/usr/local/ELK/elasticsearch/bin/elasticsearch啟動之後,可以通過訪問IP的9200埠判斷elasticsearch是否啟動成功,訪問返回elasticsearch節點資訊則為成功啟動。
通過訪問http://192.168.9.90:9200/_cluster/health?pretty 網址來檢視叢集狀態,成功的話,則會出現叢集的名稱,節點數量。叢集狀態可分為綠色,黃色,紅色。綠色則為正常執行。
二。elasticsearch之後,則安裝logastash和kibana,先後無所謂,我這裡先安裝kibana
解壓kibana到ELK內,編輯配置檔案
vim /usr/local/ELK/kibana-5.6.4-linux-x86_64/config/kibana.yml
server.port: 5601 ## kibana預設埠
server.host: "192.168.9.90" ## 服務的host,直接填本機IP即可。
elasticsearch.url: "http://192.168.9.89:9200" ## elasticsearch的連線地址,叢集時,連線其中一臺節點即可。啟動kiban即可,啟動命令:
/usr/local/ELK/kibana-5.6.4-linux-x86_64/bin/kibana依然不是後臺程序,用supervisor進行管理。啟動後,則可以訪問本機IP的5601埠,出現kibana的介面則安裝成功。(另外,記得開放埠)
第一次訪問,會要求建立索引,但是因為並沒有資料,所以沒辦法建立,這是正常的,目前暫不用進去,只要能看到介面則OK了,日後完整搭建後,會再提到。
三。logstash的安裝
解壓logstash到ELK內,編輯配置檔案
vim /usr/local/ELK/logstash-5.6.4/config/logstash.yml
http.host: "0.0.0.0" ##修改host為0.0.0.0,這樣別的電腦就可以連線整個logstash,不然只能本機連線。要啟動logstash,還需要一個配置檔案,來配置logstash過濾解析日誌資訊的規則,這個規則的配置檔案則是需要自行定義,logstash對於這個規則的外掛有很多,常用的有grok,kv,geoip等,這個配置檔案需要有一個入口,和一個出口,中間是過濾器,一共三大部分。入口的化,根據我們的架構,是通過redis,將日誌資訊輸入到logstash,所以入口配置為redis即可,而出口則是後面的elasticsearch資料儲存器,所以出口也固定了,所以需要根據實際情況自定義的主要就是中間的過濾器filter。
下面貼出一個配置例子:
input { ## input為輸入口
redis {
data_type => "list" ## 佇列輸入,預設輸入型別為list
db => 10 ## 指定redis庫
key => "redis-pipeline" ## redis是key-value式的記憶體資料庫,指定key即是指定佇列的標識key的大概意思
host => "192.168.9.79" ## 下面是連線資訊,如果有密碼則需要新增password這一項
port => "6379"
threads => 5 ## 執行緒數
}
}
filter { ## 過濾器filter
grok { ## grok外掛,可以通過正則匹配,將日誌的message進行格式化轉換。
match => ["message","%{YEAR:YEAR}-%{MONTHNUM:MONTH}-%{MONTHDAY:DAY} %{HOUR:HOUR}:%{MINUTE:MIN}:%{SECOND:SEC},(?<MSEC>([0-9]*)) %{LOGLEVEL:loglevel} \[(?<Classname>(.*))\] - (?<Content>(.*))"]
}
}
output { ## 輸出elasticsearch
elasticsearch {
hosts => ["192.168.9.89:9200","192.168.9.90:9200"] ## 輸出的elasticsearch的資料節點IP
index => "logstash-test" ## 索引值
#user => "elastic" ## elasticsearch 的使用者密碼,需要安裝x-pack才會有,這裡先不用
#password => "changeme"
}
}
好的,配置好自定義過濾轉換規則後,並將其儲存在 ELK/conf/all.conf ,開啟logstash,啟動命令:
/usr/local/ELK/logstash-5.6.4/bin/logstash -f /usr/local/ELK/conf/all.conf同上,logstash依然是使用supervisor進行管理,請參考《centos7 Supervisor的安裝與配置,管理elk程序。》
OK,到此,elk三個軟體的部署搭建完成。
下一篇,講解如何搭建filebeat對日誌檔案進行監控,實時採集。和如何利用grok進行資料過濾,轉化成想要的格式儲存再elasticsearch裡,用於展示。