
資料探勘概念與技術——讀書筆記(1)
阿新 • • 發佈:2019-02-09
原書第三版
Jiawei Han Micheline Kamber Jian Pei 著
第一章 引論
為什麼進行資料探勘
解決“資料豐富,但資訊貧乏”的問題。
資料的爆炸式增長,廣泛可用,巨大數量 ——> 資料時代 ——> 需要功能強大和通用的工具,從海量資料中發現有價值的資訊。
什麼是資料探勘
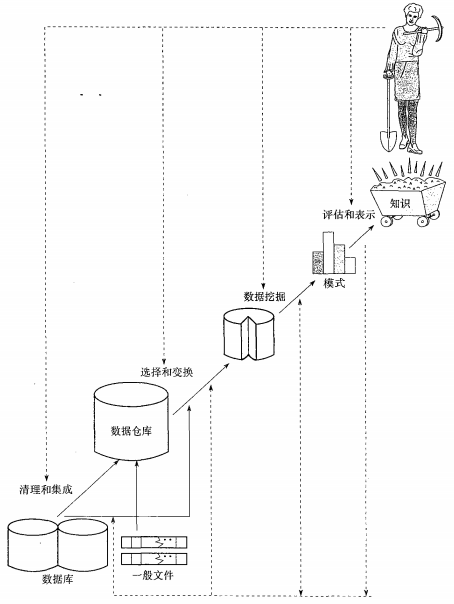
從資料中挖掘知識。
- 資料清理(消除噪聲和刪除不一致的資料)
- 資料整合(多種資料來源可以組合在一起)
- 資料選擇(從資料庫中提取與分析任務相關的資料)
- 資料變換(通過彙總或聚集操作,把資料變換和統一成適合挖掘的形式)
- 資料探勘(基本步驟,使用智慧方法提取資料模式)
- 模式評估(根據某種興趣度度量,識別代表知識的真正有趣的資料)
- 知識表示(使用視覺化和知識表示技術,向用戶提供挖掘的知識)
可以挖掘什麼型別的資料
- 資料庫資料
- 由一組內部相關的資料和一組管理和存取資料的軟體程式組成。
- 關係資料庫是表的彙集(屬性—>欄位或列,元祖—>記錄或行)。物件被唯一關鍵字標識,被一組屬性值描述。
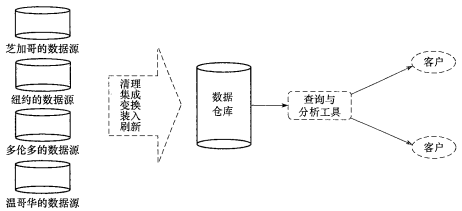
- 資料倉庫
- 從多個數據源收集的資訊儲存庫(例如分部遍佈全世界的公司的資料庫)
- 從多個數據源收集的資訊儲存庫(例如分部遍佈全世界的公司的資料庫)
- 事務資料
- 每個記錄代表一個事務。
- 包含一個唯一的事務標識號,以及一個組成事務的項。
- 例如商場的第50條交易記錄,使用者購買了A,D,F這三件物品。
- 其他型別的資料
- 空間資料,超文字和多媒體資料……等等
可以挖掘什麼型別的模式
- 描述性(刻畫目標資料中資料的一般性質)
- 預測性(在當前資料上做出歸納,以便進行預測)
類/概念描述:特徵化與區分
資料特徵化:目標類資料的一般特性或特徵的彙總
資料區分:將目標類,與一個或多個可比較類進行比較。
例如:定期購買電腦產品的客戶和不購買電腦產品的客戶進行比較。
挖掘頻繁模式、關聯和相關性
頻繁模式:在資料中頻繁出現的模式。
- 頻繁項集:頻繁在事務資料集中一起出現(顧客在小賣部總是一起買牛奶和麵包)
- 頻繁子序列:顧客先買數碼相機,再買記憶體卡。
- 頻繁子結構
關聯分析(例如分析,哪些商品總是一起被購買)
- “computer”=>“software”[1% , 50%] 表示所有事務的1%顯示計算機和軟體被同時購買。購買了計算機的人,有50%的可能性會選擇購買軟體。
相關性(相關聯的屬性-值對之間的統計相關性)
用於預測分析的分類和迴歸
- 分類:找出描述和區分資料類或概念的模型(或函式),預測類別標號。
- 迴歸:建立連續值函式模型,預測缺失的或難以獲得的數值資料值。
相關分析可能需要在分類和迴歸之前進行,它試圖識別與分類和迴歸過程顯著相關的屬性。
聚類分析
聚類分析:分析資料物件,而不考慮類標號。可以使用聚類產生資料組群的類標號。
—>“最大化類內相似性,最小化類間相似性”
離群點分析
異常挖掘。有時看做噪聲而丟棄,但是在比如欺詐檢測等應用中,罕見事件的出現,更令人感興趣。
所有模式都是有趣的嗎?
- 易於被人理解
- 在某種確信度上,對於新的或檢驗資料是有效的
- 潛在有用的
- 新穎的
客觀度量:支援度,置信度。
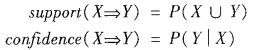
使用什麼技術
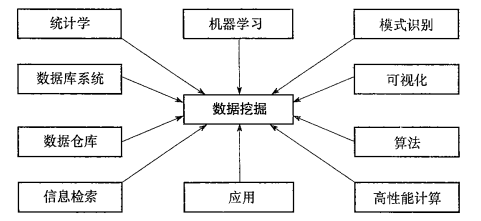
- 統計學:例如建立分類或預測模型之後,統計假設檢驗來驗證模型
- 機器學習:監督學習(基本上是分類的同義詞),無監督學習(本質上是聚類的同義詞),半監督學習,主動學習
- 資訊檢索:搜尋文件或文件中資訊的科學
面向什麼型別的應用
商務智慧、Web搜尋、生物資訊學、衛生保健資訊學、金融、數字圖書館……
資料探勘的主要問題
- 挖掘方法
- 新的知識型別、多維空間中的知識、跨學科、網路環境下的挖掘能力、模式評估
- 使用者互動
- 結合背景知識
- 表示和視覺化,使知識更容易理解
- 有效性與可伸縮性
- 處理多種多樣的資料型別
- 動態的、複雜的。
- 資料探勘與社會
- 保護隱私
- 社會影響
自己加油加油 笨鳥後飛也要飛呀飛