
hadoop基礎概念之Hadoop核心元件
認知和學習Hadoop,我們必須得了解Hadoop的構成,我根據自己的經驗通過Hadoop構件、大資料處理流程,Hadoop核心三個方面進行一下介紹:
一、 Hadoop元件
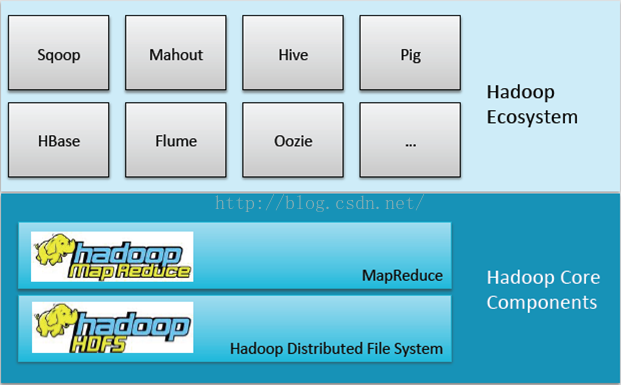
由圖我們可以看到Hadoop元件由底層的Hadoop核心構件以及上層的Hadoop生態系統共同整合,而上層的生態系統都是基於下層的儲存和計算來完成的。
首先我們來了解一下核心構件:Mapreduce和HDFS。核心元件的產生都是基於Google的思想來的,Google的GFS帶來了我們現在所認識的HDFS,Mapreduce帶來了現在Mapreduce。因為Google有bigtable的概念,就是通過一個表格去儲存所有的網頁資料,從而也帶來了Hbase,但Hbase只是這種架構思想,架構並不完全一樣。
而位於上層的生態就是圍繞Hadoop核心構件進行資料整合,資料探勘,資料安全,資料管理以及使用者體驗等。
二、 大資料處理:
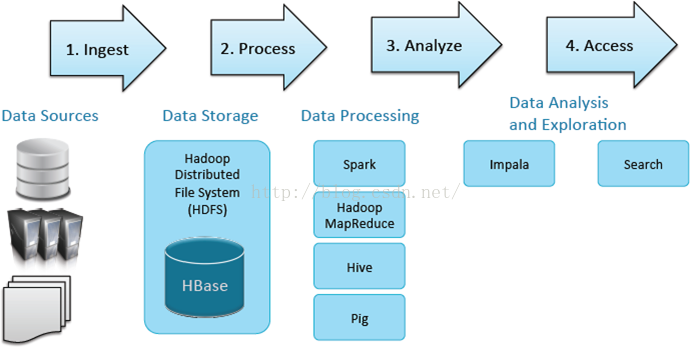
以上的流程符合大資料所有的應用場景。那麼大資料處理,首先必須有各種的資料來源,這個資料來源包含了所有傳統的結構化的資料,伺服器的認證以及非結構化的文字(如PDF及CSV)。之前做過一個檢察院的專案,大量的案例及文書都是以PDF和CSV的形式存在的,加入到Hadoop統一進行結構化和建模,進行全民索引,大大提高了效率。
接著就是資料儲存層,資料儲存層可以選擇HDFS,也可以選擇HBase。它們兩個如何來更好的選擇呢?HDFS一般是大量資料集的時候用比較好,因為HDFS能提供高吞吐量的資料訪問,非常適合大規模資料集上的應用。而HBase更多的是利用它的隨機寫,隨機訪問的海量資料的一個性能。
然後就是資料處理工具,基本的就是spark和mapreduce,更高階的就是hive和pig,有機會我會做詳細的分析。在這些資料處理工具的之後,我們要跟BI和現有的、傳統的資料進行整合,這時我們可以使用Impala,進行及時查詢。首先我們要提前建好Q,算出維度、指標,通過Impala鑽去,切片、切塊,速度很快。search就是權威索引,之前工作都做完後,可以通過搜尋去查詢到需要的資訊。
大資料處理都是需要這些元件來發揮作用,只是元件所處的階段不一樣而已,下面來介紹一下核心的元件。
三、 Hadoop核心
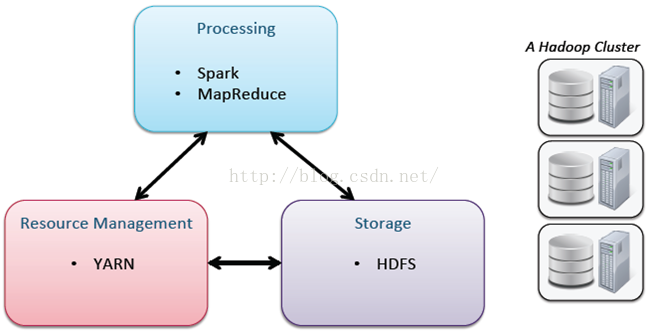
這裡主要強調YARN:我們都知道大家使用資源都是一個共用叢集資源,在使用資源的過程中就需要進行資源控制,而YARN就可以起到控制和使用資源多少的一個作用。
以上就是給大家介紹的Hadoop的元件,至於每一個元件的作用,後續我也會給大家做一個知識分享。建議對大資料感興趣的同學自己平時多學習和了解,我平常喜歡關注大資料cn和大資料時代學習中心這些微信公眾號,裡面介紹的一些知識很不錯,可以看一下。另外自己可以多看一些這方面的書籍,不斷提升和完善自己的知識架構!