
詳解SLIM與GLSLIM推薦模型
一、介紹
SLIM模型是明尼蘇達大學2011年的論文,點選開啟連結這是文章連結。GLSLIM是今年推薦系統頂會RecSys的 best paper,新鮮出爐Local Item-Item Models for Top-N Recommendation 。網上還沒有解釋過SLIM的博文,所以寫在這裡(全網首發哦,轉載請註明出處),希望和大家分享,如果有錯誤的地方,也希望大家批評建議。
Top-N 推薦系統一直是熱門問題,它的解決演算法一般分為兩大類:neighborhood-based 和 model-based。 neighborhood-based 大家都很熟悉,用各種距離度量方式計算出使用者之間(user-based)或者物品之間(item-based)的近似度,然後類似於KNN演算法,根據該使用者(物品)的最相似的 k 個使用者(物品)來進行推薦,這種演算法只用了使用者行為資料,可解釋性強,容易實現,得益於使用者行為矩陣的稀疏性,運算非常快。Youtube之前的視訊推薦演算法,是content-based和item-based結合,根據使用者行為,只計算同一topic下的視訊的相似度,這樣避免了使用者行為資料裡的噪音,並且相對普通的item-based演算法,更好地利用了長尾資料,增強了推薦系統的覆蓋率,並且在改進演算法中結合model-based,效果進一步提升。Model-based一般是指根據使用者行為資料矩陣進行矩陣分解或者用模型來學習使用者、物品隱變數,用學習到的低rank的使用者矩陣、物品矩陣相乘來預測結果,典型演算法有SVD, SVD++, ALS演算法等等。 Neighborhood-based的優勢是計算速度快(畢竟不需要有訓練、學習的過程),但是速度是犧牲在推薦效果上的。Model-based演算法推薦效果會優於neighborhood-based演算法,但是推薦效果的提升是在演算法訓練時間大幅上漲的前提下。那麼,有沒有一種演算法可以既提升neighborhood-based演算法的效果,又提升model-based演算法的執行時間呢?答案就是SLIM演算法。
二、SLIM
1. SLIM 介紹
瞭解SVD系列推薦系統的都知道,SVD系列演算法的精髓在於找出兩個rank遠低於原矩陣的小矩陣,矩陣B代表使用者的特徵,矩陣C代表物品的特徵,B的第 i 行即為使用者 i 的特徵,C 的第 j 列即為物品 j 的特徵,兩個向量相乘,得到的即為使用者 i 對於 物品 j 的得分預測。由於預測過程只需要矩陣相乘,訓練出兩個 low rank 矩陣後,得到速度非常快。SLIM和SVD系列相似,區別在於 SVD是把矩陣 A 分解為了兩個 low rank 的小矩陣,而SLIM是直接用矩陣 A 當做要學習得到的用來相乘的兩個矩陣中的一個。 在下 SLIM 這一節中,u代表使用者,t代表物品,集合U代表所有使用者,集合T代表所有物品。使用者行為矩陣為A(m*n,m個使用者,n個物品)如果使用者 i 對 物品 j 有過點選、購買等行為,Aij 就是1(或者一個正數),否則為0 。
 代表矩陣A的一列,即所有使用者對物品 j 的記錄。字母上面帶下劃線的是預測的結果,例如
代表矩陣A的一列,即所有使用者對物品 j 的記錄。字母上面帶下劃線的是預測的結果,例如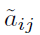 。
。SLIM的預測公式是
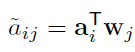
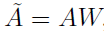
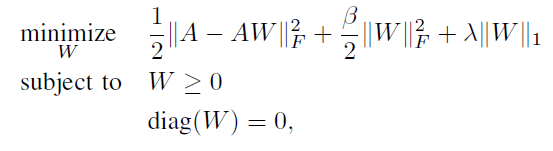
2. SLIM 的優勢
好了不賣關子啦,答案是如果沒有這個對角線限制,與 A 相乘之後,為了減小誤差函式,會傾向於只推薦它自己,所以我們要保證一個已知的行為得分不會用於預測
他自己的計算。
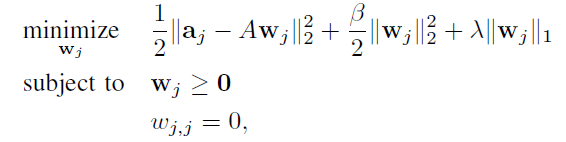
其次,由上面各列的損失函式,可以發現擬合
相似度高的列,也就是取那些使用者行為和物品
j 相似的物品們的向量。這裡其實很像 item-based。
綜上所述,SLIM 既考慮到了利用使用者物品行為之間的相似度來縮短訓練時間(neighborhood-based),又利用學習訓練過程提升了結果的精度(model-based),結合了兩種主流演算法的優勢,而且由於矩陣 A 很稀疏(一個使用者只會對很小一部分物品有過行為,注意在這個演算法裡,矩陣缺失值填0),學習到的 W 也很稀疏(一是L1正則化會產生稀疏解,二是特徵選擇的過程本身就將使用者行為相似度低的物品們的權重置零了)。據論文作者的實驗,SLIM
演算法在 top-N 推薦任務裡的準確度要高於其餘演算法。
三、 從SLIM到GLSLIM
1. 思路
SLIM 已經不錯了,但還有沒有可以改進的方向呢? SLIM 是對全域性資訊進行統一的學習過程,但是使用者之間是可以根據使用者行為聚類的,各類裡獨有的行為,用一個 global 的模型恐怕不能完整地描述出來。比如下圖中,如果使用者行為如左圖所示,那麼物品 c 和 i、j 之間在使用者群 B 裡的相似度和在使用者群 A 裡的相似度是截然不同的;若使用者行為如右圖所示,則物品 i 和 j 的相似度不受使用者群體影響。考慮到其實絕大多數現實資料都像左圖一樣,我們可以針對各類進行訓練,學習每個類裡的特殊資訊。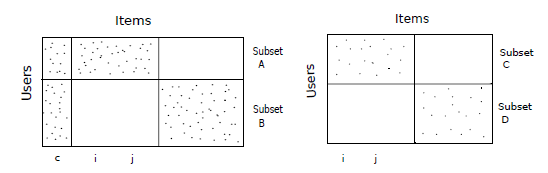
2. GLSLIM
公式(3)是 GLSLIM 的擬合公式,GLSLIM 會像 SLIM 一樣擬合一個權重矩陣 S (SLIM演算法中的W),然後再訓練 k 個 local 模型,學習 k 個不同的類中的資訊(論文中聚類方法採用的是CLUTO)。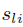
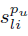 代表物品 l 和物品 i 的在第pu個使用者群裡的區域性相似度。
代表物品 l 和物品 i 的在第pu個使用者群裡的區域性相似度。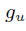 是每個使用者獨有的權重係數,代表該使用者更傾向於全域性模型還是區域性模型,該係數位於【0,1】區間內,也是模型需要學習的引數。下圖意為預測
使用者 u 對 物品 i 的得分,其中使用者 u 屬於 pu 類。
是每個使用者獨有的權重係數,代表該使用者更傾向於全域性模型還是區域性模型,該係數位於【0,1】區間內,也是模型需要學習的引數。下圖意為預測
使用者 u 對 物品 i 的得分,其中使用者 u 屬於 pu 類。
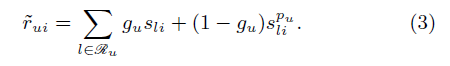
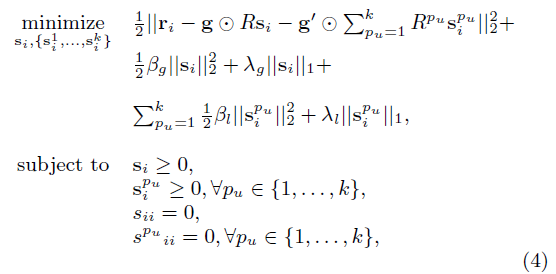
使用者偏好係數由最小化公式(3)的誤差而得,公式如下圖所示:
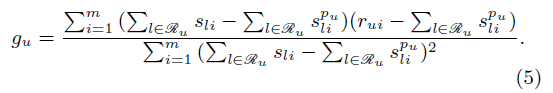
看到這裡,大家應該一目瞭然了,與 SLIM 非常相似,只不過加入了更多的區域性模型。大家應該能發現,GLSLIM 的一個關鍵點是如何對使用者進行聚類,眾所周知,聚類的 效果不容易保證,難道要完全依賴於聚類演算法們的效果嗎? 答案是 No,第一步聚類的結果只是初始化用,GLSLIM 演算法本身還會對聚類結果進行調整。下圖是 GLSLIM 的完整演算法,可以看到在while迴圈裡,對每個使用者,會把他分到訓練誤差最小的那一類去。當聚類的結果改變超過 1% 時,會一直迭代下去。GLSLIM 的結果要優於 SLIM,但是這個準確度的提升,是建立在更多次的迭代和更多的基模型的基礎上的。

3. LSLIM 和 GLSLIMr0
這是兩種 GLSLIM 的變型,LSLIM 與 GLSLIM 相比,沒有去訓練全域性模型,只訓練了各使用者群的區域性模型。效果會比GLSLIM稍差一些,畢竟訓練過程縮短,沒有訓練全域性模型,捕捉不到全域性資訊。擬合公式如公式(9)所示,損失函式如公式(8)所示: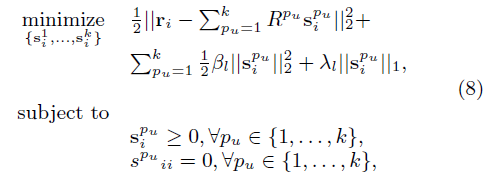

GLSLIMr0 與GLSLIM 相比,相信聚類演算法的結果,沒有在每次迭代中對使用者所在的使用者群進行更改,固定住每個類裡的使用者,當某次迭代和上一次的訓練誤差相比變化不大時,停止訓練。以下是這兩種演算法的詳細過程:

個人感覺 GLSLIM 的計算量確實大了些,訓練時間比起 SLIM 幾何倍增加,短時間內應該很難進行工業實現。謝謝能看到這裡的朋友~ 轉載請註明出處~