
Hive中UDF和UDAF的使用
UDF
使用者自定義函式(user defined function)–針對單條記錄。
建立函式流程
1、自定義一個Java類
2、繼承UDF類
3、重寫evaluate方法
4、打成jar包
6、在hive執行add jar方法
7、在hive執行建立模板函式
8、hql中使用
Demo01:
自定義一個Java類
打成jar包UDFTest.jar
在hive執行add jar方法
在hive建立一個bigthan的函式,引入的類是UDF.UDFTest
1.add jar /liguodong/UDFTest.jar;
2.create temporary function bigthan as 'UDFDemo.UDFTest' 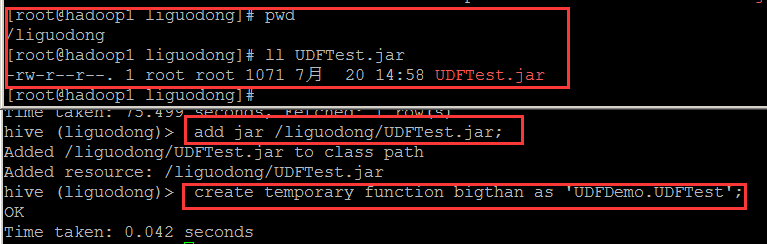
1.select no,num,bigthan(no,num) from testudf;
UDAF
UDAF(user defined aggregation function)使用者自定義聚合函式,針對記錄集合
開發UDAF通用有兩個步驟
第一個是編寫resolver類,resolver負責型別檢查,操作符過載。
第二個是編寫evaluator類,evaluator真正實現UDAF的邏輯
通常來說,頂層UDAF類繼承 org.apache.Hadoop.hive.ql.udf.generic.GenericUDAFEvaluator裡面編寫巢狀類evaluator實現UDAF的邏輯。
一、實現resolver
resolver通常繼承
org.apache.hadoop.hive.ql.udf.GenericUDAFResolver2,但是更建議繼承AbstractGenericUDAFResolver,隔離將來hive介面的變化。GenericUDAFResolver和GenericUDAFResolver2介面的區別是後面的允許evaluator實現可以訪問更多的資訊,例如
DISTINCT限定符,萬用字元FUNCTION(*)。二、實現evaluator
所有eva1uators必須繼承抽象類 org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator
Mode
這個類比較重要,它表示了udaf在mapreduce的各個階段,理解Mode的含義,就理解了hive的UDAF的執行流程。
public static enum Mode{
PARTIAL1,
PARTIAL2,
FINAL,
COMPLETE
};
PARTIAL1:這個是mapreduce的map階段:從原始資料到部分資料聚合,將會呼叫iterate()和terminatePartial()。PARTIAL2:這個是mapreduce的map端的Combiner階段,負責在map端合併map的資料;從部分資料聚合到部分資料聚合,將會呼叫merge()和terminatePartial()。
FINAL:mapreduce的reduce階段:從部分資料的聚合到完全聚合,將會呼叫merge()和terminate()。
COMPLETE:如果出現了這個階段,表示mapreduce只有map,沒有reduce,所以map端就直接出結果了;從原始資料直接到完全聚合,將會呼叫iterate()和terminate()
流程–無Combiner

流程–有Combiner
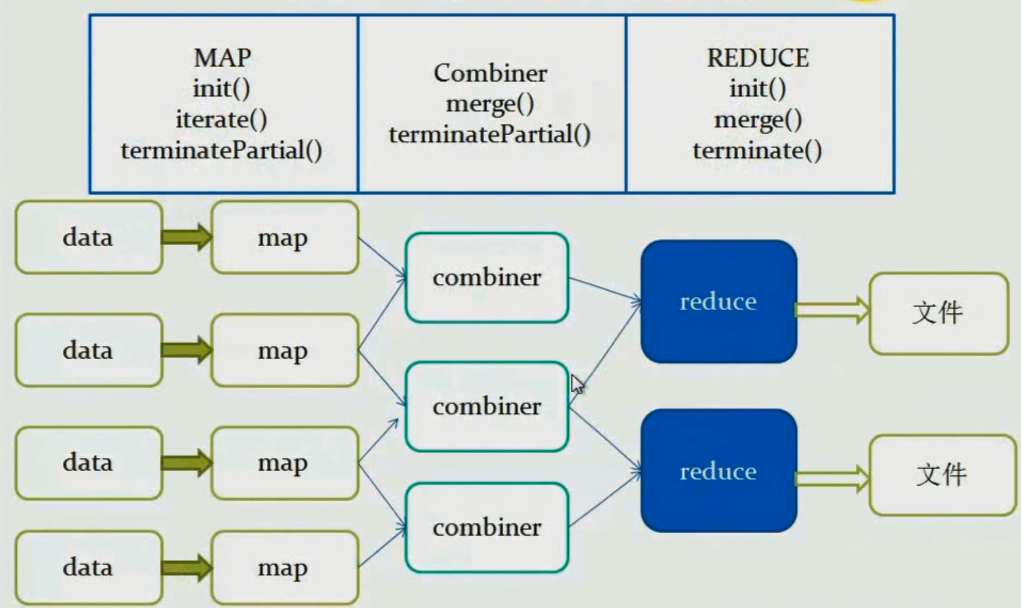
mapreduce階段呼叫函式
MAP
init()
iterate()
terminatePartial()
Combiner
merge()
terminatePartial()
REDUCE
init()
merge()
terminate()
永久函式
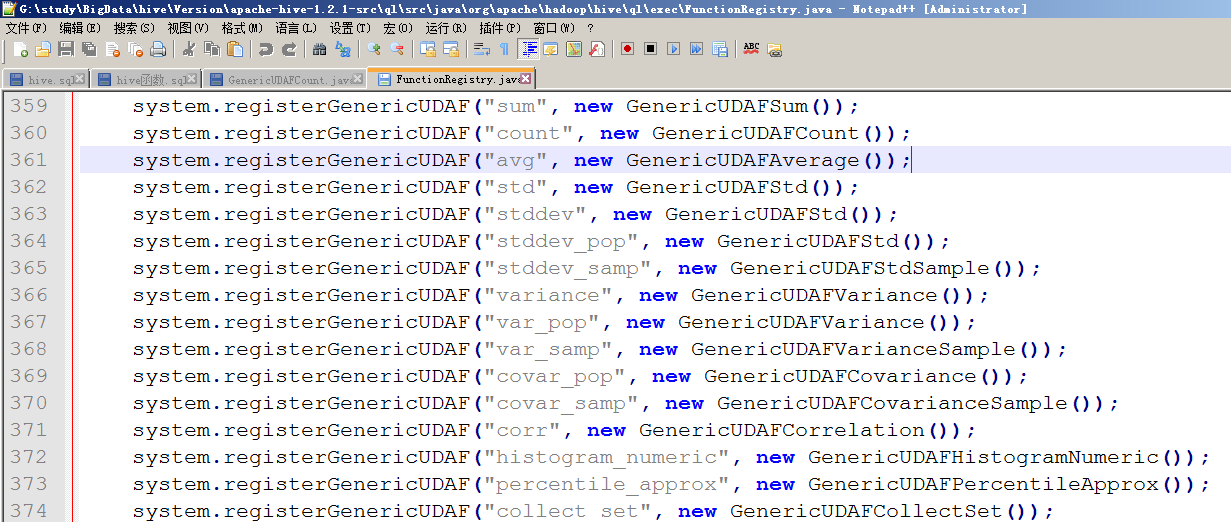
方式1、如果希望在hive中自定義一個函式,且能永久使用,
則修改原始碼新增相應的函式類,然後在修改ql/src/java/org/apache/hadoop/hive/ql/exec/FunctionRegistry.java類,新增相應的註冊函式程式碼registerUDF("parse_url",UDFParseUrl.class,false);。
方式2、hive -i ‘file’
方式3、新建hiverc檔案
1、jar包放到安裝日錄下或者指定目錄下
2、${HIVE_HOME}/bin目錄下有個.hiverc檔案,它是隱藏檔案。
3、把初始化語句載入到檔案中
1.vi .hiverc
2.add jar /liguodong/UDFTest.jar;
3.create temporary function bigthan as 'UDFDemo.UDFTest';
然後開啟hive時,它會自動執行.hiverc檔案。