
Spark2.0 相關知識彙總
1. VMware搭建Ubuntu16.04 spark叢集
- VMware 安裝Ubuntu16.04
- Ubuntu 啟用root使用者登陸
- 安裝 VMware tools
- 安裝jdk1.8,配置環境變數
- 安裝ssh
- 虛擬機器設定固定ip
- 設定/etc/hostname 本系統的名字(如:Master,Worker1);設定/etc/hosts 主從機的ip對應
- ssh無密碼驗證配置
- 安裝hadoop2.7.3,配置環境變數
- 格式化檔案系統 hadoop namenode -format
./start-dfs.sh 啟動hdfs
jps 檢視jvm程序 瀏覽器master:50070
./start-yarn.sh 啟動資源管理框架
jps 檢視jvm程序 瀏覽器master:8088 - 安裝spark-2.0.0-bin-hadoop2.7,配置環境變數
2. Eclipse 編寫第一個Spark程式
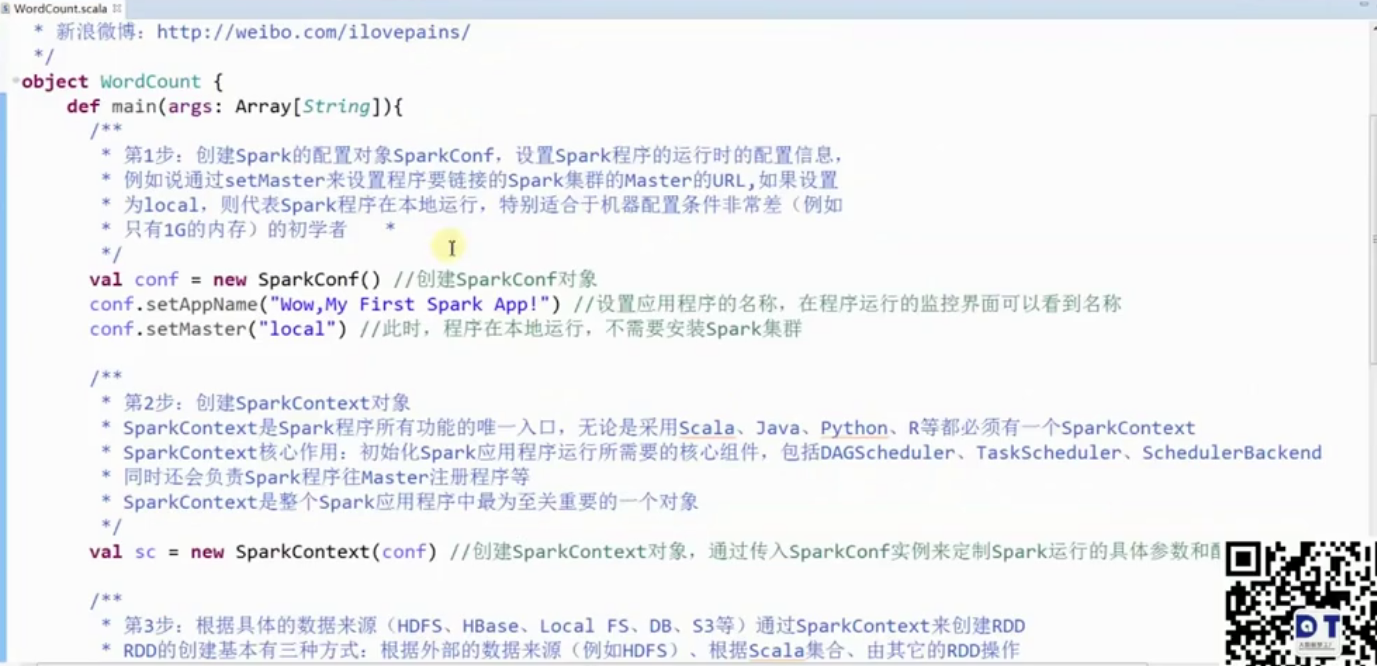
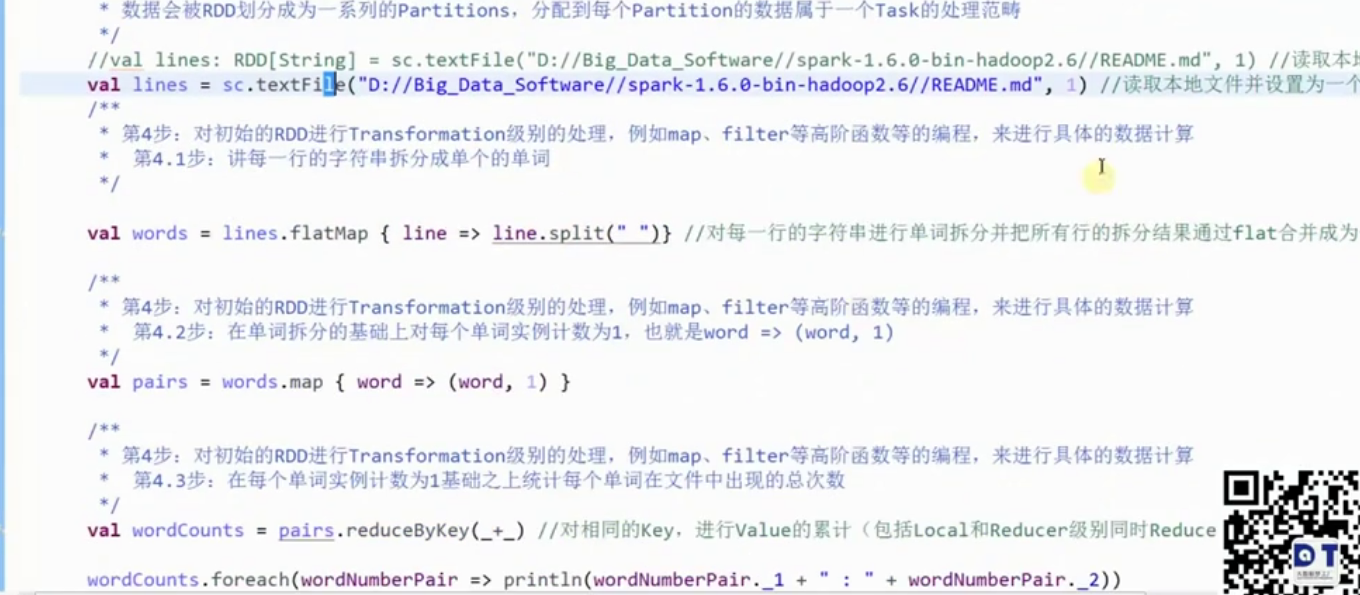
sc.stop()
3. RDD
RDD:Resillient Distributed DataSet 彈性分佈資料集.RDD是Spark中的抽象資料結構型別,任何資料在Spark中都被表示為RDD。從程式設計的角度來看,RDD可以簡單看成是一個數組。和普通陣列的區別是,RDD中的資料是分割槽儲存的,這樣不同分割槽的資料就可以分佈在不同的機器上,同時可以被並行處理。因此,Spark應用程式所做的無非是把需要處理的資料轉換為RDD,然後對RDD進行一系列的變換和操作從而得到結果。
所謂彈性為一下七點:
1、自動的進行記憶體和磁碟資料儲存的切換;
2、基於Lineage的高效容錯(第n個節點出錯,會從第n-1個節點恢復,血統容錯);
3、Task如果失敗會自動進行特定次數的重試(預設4次);
4、Stage如果失敗會自動進行特定次數的重試(可以值執行計算失敗的階段);只計算失敗的資料分片
5, checkpoint和persist
6,資料排程彈性:DAG TASK和資源 管理無關
7,資料分片的高度彈性,repartition
RDD的7種基本的建立方式
1,使用程式中的集合建立RDD;
2,使用本地檔案系統建立RDD;
3,使用HDS建立RDD
4,基於DB建立RDD
5,基於NoSQL,例如HBase
6,基於S3建立RDD
7,基於資料流建立RDD
4. Transformation Action 運算元
凡是Action級別的操作都會觸發sc.runjob.
reduceByKey 是Transformation ,lazy級別的
reduce 是 Action
Action級別的操作:
reduce,collect,count,countByKey,take,saveAsTextFile
運算元
1. map、filter、flatmap
2. reduceByKey、groupByKey
3. join、cogroup
5. 廣播 broadcastNumber
val number = 10
val broadcastNumber = sc.broadcast(Number)
val data = sc.parallelize(1 to 10000)
val bn = data.map(_* broadcastNumber.value)
bn.collect 6. 累加器 accumulator
val sum = sc.accumlator(0) //初始值為0
val data = sc.parallelize(1 to 100)
val result = data.foreach(item => sum += item)
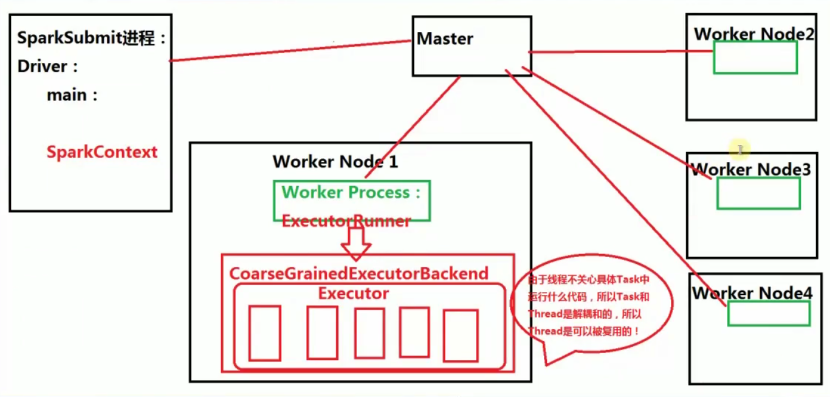
7. Spark架構
- 預設的資源分配方式:在每個Work上為當前程式分配一個ExecutorBackend程序,且預設情況下會最大化的使用core和momory。
- 一個work 上可以有多個executor
- 在excecutor 中一次性最多能夠執行多少併發的Task取決於當前Executor能夠使用的cores數量
- 執行緒不關心具體Task中執行什麼程式碼,所以Task 和Thread和解耦合,所以Thread是可以被複用
- 當Spark叢集啟動的時候,首先啟動Master程序(全域性資源管理器),負責整個叢集的資源管理和分配,以及接收程式作業的提交且為作業分配資源。每個工作節點預設都會啟動一個Work Process,來管理當前節點的Memory、CPU等計算資源,並向Mster彙報Worker還能夠正常工作(即心跳)。當應用程式提交作業給Master的時候,Master 會為程式分配ID並分配計算資源,預設情況下為當前的應用程式在每個Worker Process下分配一個CoarseGrainedExecutorBackend程序(一個節點有可能會有多個Worker Process),該程序預設情況下會最大限度的使用當前節點上的的CPU和記憶體。當Driver 本身沒有問題的話,Driver就會進行作業的排程來驅動CoarseGrainedExecutorBackend 中Excutor的執行緒來具體幹活。這也就併發執行了。
- Work Process 管理當前節點的CPU和記憶體等計算資源實際上是通過Master來管理每臺機器上的計算資源
- Worker節點上有Worker Process,Worker Process會接收Master的指令,為當前要執行的應用程式分配CoarseGrainedExecutorBackend 程序
- Spark的一個應用程式中可以應為不同的Action產生眾多的Job,每個Job至少有一個Stage,Stage裡面的內容一定是在Executor中執行的,而且Stage必須從前往後執行。
“`
8. RDD依賴關係
- 寬依賴是指一個父RDD的Partition會被多個子RDD的Partition所使用,例如groupByKey、reduceByKey、sortByKey等操作都會產生寬依賴,寬依賴會產生shuffle
- 窄依賴是指每個父RDD的一個Partition最多被子RDD的一個Partition所使用,例如map、filter、union等都會產生窄依賴【map、filter等Transformation的操作來說,它們只是按照具體的map、filter裡面的函式,進行具體的轉換,它並不是涉及其他的處理。實質上是資料從一種形式轉換成另外一種形式。Union操作是將多個RDD合併成一個RDD,它所有的父RDD的Partition不會有任何變化】
- 總結:如果父RDD的一個Partition被一個子RDD的Partition所使用就是窄依賴,否則的話就是寬依賴。如果子RDD中的Partition對父RDD的Partition依賴的數量不會隨著RDD資料規模的改變而改變的話,就是窄依賴,否則的話就是寬依賴。
- 特別說明:對join操作有兩種情況,如果說join操作的時候每個partition僅僅和已知的Partition進行join,這次是join操作就是窄依賴;其它情況【input not co-partitioned 會產生shuffle操作,而co-partitioned是哪幾個固定的Partition進行join】的join操作就是寬依賴;
因為是確定的partition數量的依賴關係,所有就是窄依賴,得出一個推論,窄依賴不僅包含一對一的窄依賴,還包含一對固定個數的窄依賴(也就是說對父RDD的依賴的Partition的數量不會隨著RDD資料規模的改變而改變)
注意:
1,從後往前推理,遇到寬依賴就斷開,遇到窄依賴就把當前的RDD加入到該Stage中;
2,每個Stage裡面的Task的數量是由該Stage中最後一個RDD的Partition的數量所決定的!
3,最後一個Stage裡面的任務的型別是ResultTask,前面其它所有的Stage裡面的任務的型別都是ShuffleMapTask【原因是它需要將自己的計算結果shuffle到下一個RDD中】;
4,代表當前Stage的運算元一定是該Stage的最後一個計算步驟!!!
表面上是資料在流動,實質上運算元在流動:
1, 資料不動程式碼動;
2,在一個Stage內幕運算元為何會流動(Pipeline)?首先是運算元合併,也就是所謂的函數語言程式設計的執行的時候最終進行函式的展開從而把一個Stage內部的多個運算元合併成為一個大運算元(其內部包含了當前Stage中所有運算元對資料的計算邏輯);其次是由於Tranformation操作的Lazy特性!!!在具體運算元交給叢集的Executor計算之前首先會通過Spark Framework(DAGScheduler)進行運算元的優化(基於資料本地性的Pipeline)
9. Spark Job物理執行
- Spark Application裡面可以產生1個或者多個Job,例如spark-shell預設啟動的時候內部就沒有Job,只是作為資源的分配程式,可以在spark-shell裡面寫程式碼產生若干個Job,普通程式中一般而言可以有不同的Action,每一個Action一般也會觸發一個Job,【Action會觸發其他Action操作】
- 基於Pipeline的思想,資料被使用的時候才開始計算,從資料流動的視角來說,是資料流動到計算的位置!!!實質上從邏輯的角度來看,是運算元在資料上流動!
從演算法構建的角度而言:肯定是運算元作用於資料,所以是運算元在資料上流動;方便演算法的構建!
從物理執行的角度而言:是資料流動到計算的位置;方便系統最為高效的執行!
對於pipeline而言,資料計算的位置就是每個Stage中最後的RDD,一個震撼人心的內幕真相就是:每個Stage中除了最後一個RDD運算元是真實的以外,前面的運算元都是假的!!!
9. Shuffle
Shuffle中文翻譯為“洗牌”,需要Shuffle的關鍵性原因是某種具有共同特徵的資料需要最終匯聚到一個計算節點上進行計算。執行Task的時候才會產生Shuffle
Hash Shuffle
15. key不能是Array 【key如果是Array,則就無法非常友好的計算具體的hashcode值】
16. Hash Shuffle不需要排序
17. 思考:不需要排序的Hash Shuffle是否一定比需要排序的Sorted Shuffle速度更快?不一定!如果資料規模比較小的情形下,Hash Shuffle會比Sorted Shuffle速度快(很多)!但是如果資料量大,此時Sorted Shuffle一般都會比Hash Shuffle快(很多)
【資料量大的情況下,Sorted Shuffle比Hash Shuffle快的原因:如果資料規模比較 大,可能Hash Shuffle無法處理,因為hash的方式時會有key和控制代碼之類,還有許 多小檔案,此時,磁碟的效能會成為瓶頸,記憶體也會變成瓶頸。Sorted Shuffle會極 大地節省磁碟、記憶體的訪問,更有利於更大規模的資料運算】
18. 每個ShuffleMapTask會根據key的雜湊值計算出當前的key需要寫入的Partition,然後把決定後的結果寫入當單獨的檔案,此時會導致每個Task產生R(指下一個Stage的並行度)個檔案,如果當前的Stage中有M個ShuffleMapTask,則會M*R個檔案!!!
注意:Shuffle操作絕大多數情況下都要通過網路,如果Mapper和Reducer在同一臺機器上,此時只需要讀取本地磁碟即可。
Hash Shuffle的兩大死穴:第一:Shuffle前會產生海量的小檔案於磁碟之上,此時會產生大量耗時低效的IO操作;第二:記憶體不共用!!!由於記憶體中需要儲存海量的檔案操作控制代碼和臨時快取資訊,如果資料處理規模比較龐大的話,記憶體不可承受,出現OOM等問題!
Sort-Based Shuffle
1,Shuffle一般包含兩階段任務:第一部分,產生Shuffle資料的階段(Map階段,額外補充,需要實現ShuffleManager中getWriter來寫資料(資料可以BlockManager寫到Memory、Disk、Tachyon等,例如像非常快的Shuffle,此時可以考慮把資料寫在記憶體中,但是記憶體不穩定,建議採用MEMORY_AND_DISK方式));第二部分,使用Shuffle資料的階段(Reduce階段,額外的補充,需要實現ShuffleManager的getReader,Reader會向Driver去獲取上一下Stage產生的Shuffle資料);
10. Spark叢集部署
1, 從Spark Runtime的角度來講由五大核心物件:Master、Worker、Executor、Driver、CoarseGrainedExecutorBackend;
2, Spark在做分散式集群系統設計的時候:最大化功能獨立、模組化封裝具體獨立的物件、強內聚鬆耦合。
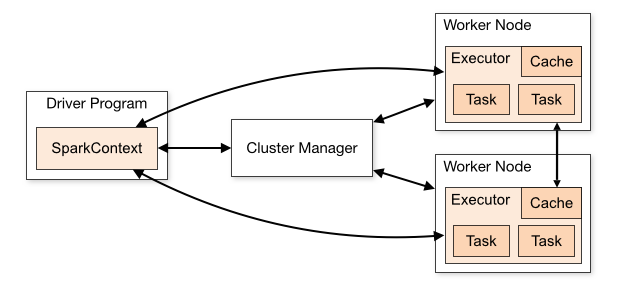
3,當Driver中的SparkContext初始化的時候會提交程式給Master,Master如果接受該程式在Spark中執行的話,就會為當前的程式分配AppID,同時會分配具體的計算資源,需要特別注意的是,Master是根據當前程式提交的配置資訊來給叢集中的Worker發指令分配具體的計算資源,但是,Master發出指令後並不關心具體的資源是否已經分配,轉來說Master是發指令後就記錄了分配的資源,以後客戶端再次提交其它的程式的話就不能使用該資源了。其弊端是可能會導致其它要提交的程式無法分配到本來應該可以分配到的計算資源;最終的優勢在Spark分散式系統功能若耦合的基礎上最快的執行系統(否則如果Master要等到資源最終分配成功後才通知Driver的話,就會造成Driver阻塞,不能夠最大化平行計算資源的使用率)。
需要補充說明的是:Spark在預設情況下由於叢集中一般都只有一個Application在執行,所有Master分配資源策略的弊端就沒有那麼明顯了。
11. SparkOn Yarn
http://bbs.pinggu.org/thread-4637621-1-1.html
1、Yarn是Hadoop推出整個分散式(大資料)叢集的資源管理器,負責資源的管理和分配,基於Yarn我們可以在同一個大資料叢集上同時執行多個計算框架,例如Spark,MapReduce、Storm等;
2、SparkOn Yarn執行工作流程圖
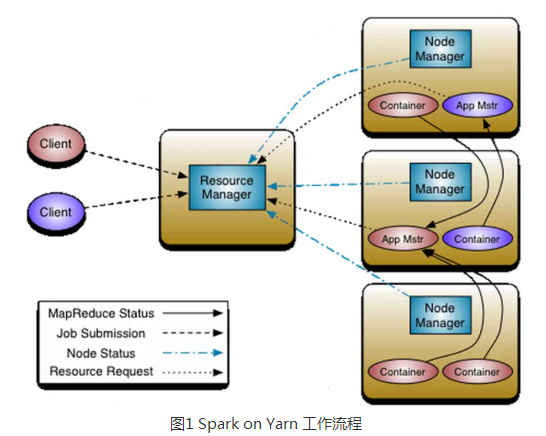
注意:Container要向NodeManager彙報資源資訊,Container要向App Mstr彙報計算資訊;
重構根本的思想是將 JobTracker 兩個主要的功能分離成單獨的元件,這兩個功能是資源管理和任務排程 / 監控。新的資源管理器全域性管理所有應用程式計算資源的分配,每一個應用的 ApplicationMaster 負責相應的排程和協調。一個應用程式無非是一個單獨的傳統的 MapReduce 任務或者是一個 DAG( 有向無環圖 ) 任務。ResourceManager 和每一臺機器的節點管理伺服器能夠管理使用者在那臺機器上的程序並能對計算進行組織。
事實上,每一個應用的 ApplicationMaster 是一個詳細的框架庫,它結合從 ResourceManager 獲得的資源和 NodeManager 協同工作來執行和監控任務。
上圖中 ResourceManager 支援分層級的應用佇列,這些佇列享有叢集一定比例的資源。從某種意義上講它就是一個純粹的排程器,它在執行過程中不對應用進行監控和狀態跟蹤。同樣,它也不能重啟因應用失敗或者硬體錯誤而執行失敗的任務。
ResourceManager 是基於應用程式對資源的需求進行排程的 ; 每一個應用程式需要不同型別的資源因此就需要不同的容器。資源包括:記憶體,CPU,磁碟,網路等等。可以看出,這同現 Mapreduce 固定型別的資源使用模型有顯著區別,它給叢集的使用帶來負面的影響。資源管理器提供一個排程策略的外掛,它負責將叢集資源分配給多個佇列和應用程式。排程外掛可以基於現有的能力排程和公平排程模型。
上圖中 NodeManager 是每一臺機器框架的代理,是執行應用程式的容器,監控應用程式的資源使用情況 (CPU,記憶體,硬碟,網路 ) 並且向排程器彙報。
每一個應用的 ApplicationMaster 的職責有:向排程器索要適當的資源容器,執行任務,跟蹤應用程式的狀態和監控它們的程序,處理任務的失敗原因。
3,客戶端Client向ResourceManager提交Application,ResourceManager接受應用並根據叢集資源狀況決定在某個具體Node上來啟動當前提交的應用程式的任務排程器Driver(ApplicationMaster),決定後ResourceManager會命令具體的某個Node上的資源管理器NodeManager來啟動一個新的JVM程序執行程式的Driver部分,當ApplicationMaster啟動的時候(會首先向ResourceManager註冊來說明自己負責當前程式的執行)會下載當前Application相關的Jar等各種資源並基於此決定具體向ResourceManager申請資源的具體內容,ResourceManager接受到ApplicationMaster的資源分配的請求之後會最大化的滿足資源分配的請求併發送資源的元資料資訊給ApplicationMaster,ApplicationMaster收到資源的元資料資訊後會根據元資料資訊發指令給具體機器上的NodeManager讓NodeManager來啟動具體的Container,Container在啟動後必須向AppplicationMaster註冊,當ApplicationMaster獲得了用於計算的Containers後,開始進行任務的排程和計算,直到作業執行完成。需要補充說的是,如果ResourceManager第一次沒有能夠完全完成ApplicationMaster分配的資源的請求,後續ResourceManager發現叢集中有新的可用資源時,會主動向ApplicationMaster傳送新的可用資源的元資料資訊以提供更多的資源用於當前程式的執行!
補充說明:
1)如果是Hadoop的MapReduce計算的話Container不可以複用,如果是Spark on Yarn的話Container可以複用;
2)Container具體的銷燬是由ApplicationMaster來決定的;
3)ApplicationMaster 發指令給NodeManager讓NodeManager銷燬Container。
4、Spark on Yarn的執行實戰:
a) Client模式:方便在命令終端
天機解密:Standalone模式下啟動Spark叢集(也就是啟動Master和Worker)其實啟動的是資源管理器,真正作業計算的時候和叢集資源管理器沒有任何關係,所以Spark的Job真正執行作業的時候不是執行在我們啟動的Spark叢集中的,而是執行在一個個JVM中的,只要在JVM所在的叢集上安裝配置了Spark即可!當沒有啟動yarn和spark-all的時候執行提交上述作業,會提示找不到Server,此時叢集會一直嘗試retry連線
5、Spark on Yarn模式下Driver與ApplicationMaster的關係:
a) Cluster:Driver位於ApplicationMaster程序中,我們需要通過Hadoop預設指定的8088埠來通過Web控制檯檢視當前的Spark程式執行的資訊,例如進度、資源的使用(Cluster的模式中Driver在AppMaster中);
b)Client:Driver在提交程式碼的機器上,此時ApplicationMaster依舊位於叢集中且只負責資源的申請和launchExecutor,此時啟動後的Eexcutor並不會向ApplicationMaster程序註冊,而是向Driver註冊!!!
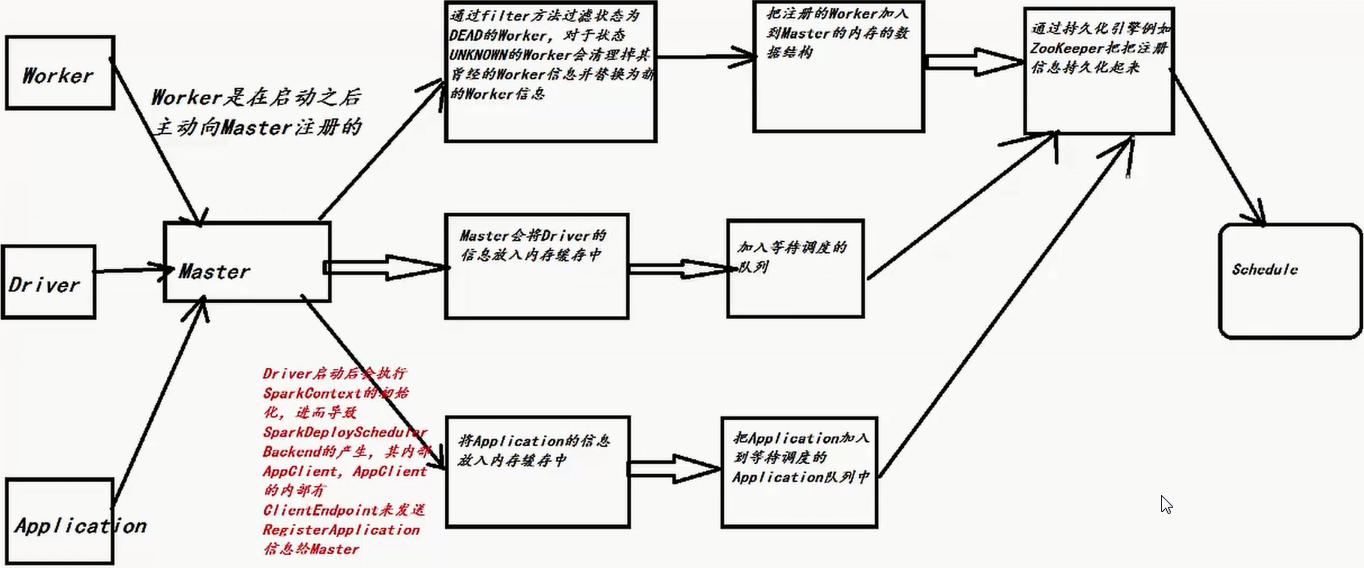
12. Master 註冊機制
13. 資源排程
http://bbs.pinggu.org/thread-4638090-1-1.html
一、任務排程與資源排程的區別
1、任務排程是通過DAGScheduler、TaskScheduler、SchedulerBackend等進行的作業排程;
2、資源排程是指應用程式如何獲得資源;
3、任務排程是在資源排程的基礎上進行的,沒有資源排程那麼任務排程就成為了無源之水無本之木!
二、資源排程內幕
1)因為Master負責資源管理和排程,所以資源排程的方法shedule位於Master.scala這個類中,當註冊程式或者資源發生改變的時候都會導致schedule的呼叫;
2)Schedule呼叫的時機:每次有新的應用程式提交或者叢集資源狀況發生改變的時候(包括Executor增加或者減少、Worker增加或者減少等);
3)當前Master必須是Alive的方式採用進行資源的排程,如果不是ALIVE的狀態會直接返回,也就是Standby Master不會進行Application的資源呼叫!
4)使用Random.shuffle把Master中保留的叢集中所有Worker的資訊隨機打亂;
5)接下來要判斷所有Worker中哪些是ALIVE級別的Worker,ALIVE才能夠參與資源的分配工作;
6)當SparkSubmit指定Driver在Cluster模式的情況下,此時Driver會加入waitingDrivers等待列表中,在每個DriverInfo的DriverDescription中有要啟動Driver時候對Worker的記憶體及Cores的要求等內容才能launch driver,如果記憶體和cores沒有,worker不會launch driver:如果是client模式,不會有等待提交driver,因為application提交driver就啟動了。下面引數中如果有supervise,則driver掛掉後可以自動重啟,前提是driver是在叢集中的,重啟次數好像是5次。在符合資源要求的情況下然後採用隨機打亂後的一個Worker來啟動Driver,Master發指令給Worker,讓遠端的Worker啟動Driver;
7) 先啟動Driver才會發生後續的一切的資源排程的模式;
8)Spark預設為應用程式啟動Executor的方式是FIFO的方式,也就是所有提交的應用程式都是放在排程的等待佇列中的,先進先出,只有滿足了前面應用程式的資源分配的基礎上才能夠滿足下一個應用程式資源的分配;
9)為應用程式具體分配Executor之前要判斷應用程式是否還需要分配Core,如果不需要則不會為應用程式分配Executor;
10)具體分配Executor之前要對要求Worker必須是ALIVE的狀態且必須滿足Application對每個Executor的記憶體和Cores的要求,並且在此基礎上進行排序產生計算資源由大到小的usableWorkers資料結構;
11)為應用程式分配Executors有兩種方式,第一種方式是儘可能在叢集的所有Worker上分配Executor,因為這樣是更好的響應併發處理能力的,更好的利用機器的併發資源,這種方式往往會帶來潛在的更好的資料本地性;
12)具體在叢集上分配Cores的時候會盡可能的滿足我們的要求,所以下面求了一個最小值;
13)如果是每個Worker下面只能夠為當前的應用程式分配一個Executor的話,每次是分配一個Core!
14)準備具體要為當前應用程式分配的Executor資訊後,Master要通過遠端通訊發指令給Worker來具體啟動ExecutorBackend程序;
15)緊接著給我們應用程式的Driver傳送一個ExecutorAdded的資訊;
14. Worker原理
15. Hive本質
- Hive是分散式資料倉庫,同時又是查詢引擎,所以SparkSQL取代的只是Hives的查詢引擎,在企業實際生產環境下,Hive+SparkSQL是目前最為經典的資料分析組合。
- Hive本身就是一個簡單單機版本的軟體,主要負責:
A) 把HQL翻譯成Mapper(s)-Reducer-Mapper(s)的程式碼,並且可能產生很多MapReduce的JOB。
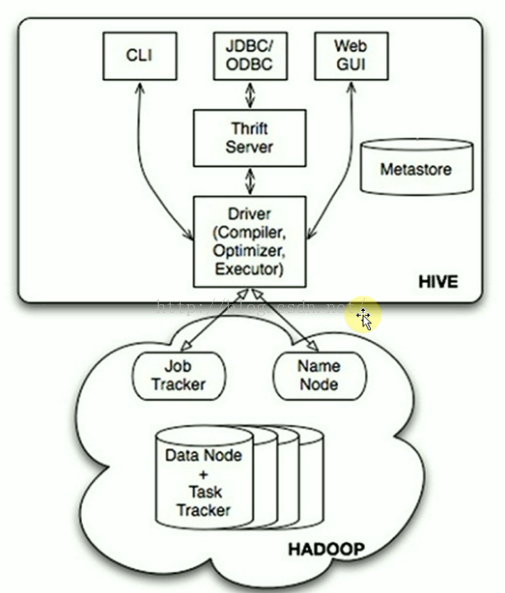
B)把生成的MapReduce程式碼及相關資源打包成jar併發布到Hadoop叢集中執行(這一切都是自動的) - Hive本身的架構如下所示:
- 可以通過CLI(命令終端)、JDBC/ODBC、Web GUI訪問Hive。JavaEE或.net程式可以通過Hive處理,再把處理的結果展示給使用者。也可以直接通過Web頁面操作Hive。
※ Hive本身只是一個單機版本的的軟體,怎麼訪問HDFS的呢?
=> 在Hive用Table的方式插入資料、檢索資料等,這就需要知道資料放在HDFS的什麼地方以及什麼地方屬於什麼資料,Metastore就是儲存這些元資料資訊的。Hive通過訪問元資料資訊再去訪問HDFS上的資料。
可以看出HDFS不是一個真實的檔案系統,是虛擬的,是邏輯上的,HDFS只是一套軟體而已,它是管理不同機器上的資料的,所以需要NameNode去管理元資料。DataNode去管理資料。
Hive通過Metastore和NameNode打交道。
16. SparkSQL和DataFrame
SparkSQL之所以是除了SparkCore外最大的和最受關注的元件,原因是:
A)處理一切儲存介質和各種格式的資料(同時可以方便地擴充套件SparkSQL的功能來支援更多型別的資料,例如Kudo,Kudo在儲存和計算效率間取得了完美的平衡),包括實時資料處理。
B)SparkSQL把資料倉庫的計算能力推向了新的高度。不僅有無敵的計算速度(SparkSQL比Shark快了至少一個數量級,而Shark比Hive快了至少一個數量級。尤其是在Tungsten成熟以後會更加無可匹敵)。更為重要的是把資料倉庫的計算複雜度推向了歷史上全新的高度(SparkSQL後續推出的DataFrame可以讓資料倉庫直接使用機器學習圖計算等複雜的演算法庫來對資料倉庫進行深度資料價值挖掘),Hive只是進行資料多維度查詢。SparkSQL可以進行機器學習、圖計算,所以是里程碑式的技術。
C)SparkSQ(DataFrame、DataSet)不僅是資料倉庫的引擎,也是資料探勘的引擎,更為重要的是SparkSQL是資料科學計算和分析引擎!!!
D) 後來的DataFrame讓Spark(SQL)一舉成為大資料計算引擎的技術實現霸主(尤其是在Tungsten的強力支援下)
傳統資料庫僅剩的應用場景:實時事務性分析。
E)Hive+SparkSQL+DataFrame是目前至少在中國所有的大資料專案至少90%無法逃脫該技術組合,
Hive負責廉價的資料倉庫儲存;SparkSQL負責高速計算;DataFrame負責複雜的資料探勘;DataFrame是一個新的API
①以DataFrame形式讀取本地hdfs檔案
//叢集模式
// val ss = SparkSession.builder
// .master("spark://Master:7077")
// .appName("Spark SQL basic example")
// .config("spark.some.config.option", "some-value")
// .getOrCreate()
//本地模式
val ss = SparkSession.builder
.master("local")
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
val df = ss.read.json("hdfs://Master:9000/library/examples/src/main/resources/people.json")
df.show()
df.printSchema()②以DataFrame形式讀取本地text檔案
```
val ss = SparkSession.builder
.master("local")
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
// txt檔案內容
// 1 spark 7
// 2 hadoop 13
val personRDD = ss.sparkContext.textFile("/root/Software/SparkCode/test.txt")
//隱式轉換 For implicit conversions from RDDs to DataFrames
import ss.implicits._
val df = personRDD.map(_.split((" "))).map(p =>Person(p(0).toInt,p(1).trim,p(2).toInt)).toDF()
df.show()
df.printSchema()
df.createOrReplaceTempView("people")
val personList = ss.sql("select * from people where age between 10 and 14")
.collect().map(item => Person(item.getAs("id"), item.getAs("name"), item.getAs("age")))
personList.foreach(println)16. Parquet
1)Parquet是列式儲存格式的一種檔案型別,列式儲存有以下的核心優勢:
a)可以跳過不符合條件的資料,只讀取需要的資料,降低IO資料量。
b)壓縮編碼可以降低磁碟儲存空間。由於同一列的資料型別是一樣的,可以使用更高效的壓縮編碼(例如RunLength Encoding和Delta Encoding)進一步節約儲存空間。
c)只讀取需要的列,支援向量運算,能夠獲取更好的掃描效能。
期待的方式:DataSource -> Kafka -> Spark Streaming -> Parquet -> Spark SQL(ML、GraphX等)-> Parquet -> 其它各種Data Mining等