
機器學習中的範數規則化之(一)L0、L1與L2範數、核範數與規則項引數選擇
今天我們聊聊機器學習中出現的非常頻繁的問題:過擬合與規則化。我們先簡單的來理解下常用的L0、L1、L2和核範數規則化。最後聊下規則化項引數的選擇問題。這裡因為篇幅比較龐大,為了不嚇到大家,我將這個五個部分分成兩篇博文。知識有限,以下都是我一些淺顯的看法,如果理解存在錯誤,希望大家不吝指正。謝謝。
監督機器學習問題無非就是“minimizeyour error while regularizing your parameters”,也就是在規則化引數的同時最小化誤差。最小化誤差是為了讓我們的模型擬合我們的訓練資料,而規則化引數是防止我們的模型過分擬合我們的訓練資料。多麼簡約的哲學啊!因為引數太多,會導致我們的模型複雜度上升,容易過擬合,也就是我們的訓練誤差會很小。但訓練誤差小並不是我們的最終目標,我們的目標是希望模型的測試誤差小,也就是能準確的預測新的樣本。所以,我們需要保證模型“簡單”的基礎上最小化訓練誤差,這樣得到的引數才具有好的泛化效能(也就是測試誤差也小),而模型“簡單”就是通過規則函式來實現的。另外,規則項的使用還可以約束我們的模型的特性。這樣就可以將人對這個模型的先驗知識融入到模型的學習當中,強行地讓學習到的模型具有人想要的特性,例如稀疏、低秩、平滑等等。要知道,有時候人的先驗是非常重要的。前人的經驗會讓你少走很多彎路,這就是為什麼我們平時學習最好找個大牛帶帶的原因。一句點撥可以為我們撥開眼前烏雲,還我們一片晴空萬里,醍醐灌頂。對機器學習也是一樣,如果被我們人稍微點撥一下,它肯定能更快的學習相應的任務。只是由於人和機器的交流目前還沒有那麼直接的方法,目前這個媒介只能由規則項來擔當了。
還有幾種角度來看待規則化的。規則化符合奧卡姆剃刀(Occam's razor)原理。這名字好霸氣,razor!不過它的思想很平易近人:在所有可能選擇的模型中,我們應該選擇能夠很好地解釋已知資料並且十分簡單的模型。從貝葉斯估計的角度來看,規則化項對應於模型的先驗概率。民間還有個說法就是,規則化是結構風險最小化策略的實現,是在經驗風險上加一個正則化項(regularizer)或懲罰項(penalty term)。
一般來說,監督學習可以看做最小化下面的目標函式:
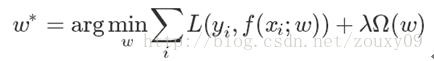
其中,第一項L(yi,f(xi;w)) 衡量我們的模型(分類或者回歸)對第i個樣本的預測值f(xi
OK,到這裡,如果你在機器學習浴血奮戰多年,你會發現,哎喲喲,機器學習的大部分帶參模型都和這個不但形似,而且神似。是的,其實大部分無非就是變換這兩項而已。對於第一項Loss函式,如果是Square loss,那就是最小二乘了;如果是Hinge Loss,那就是著名的SVM了;如果是exp-Loss,那就是牛逼的 Boosting了;如果是log-Loss,那就是Logistic Regression了;還有等等。不同的loss函式,具有不同的擬合特性,這個也得就具體問題具體分析的。但這裡,我們先不究loss函式的問題,我們把目光轉向“規則項Ω(w)”。
規則化函式Ω(w)也有很多種選擇,一般是模型複雜度的單調遞增函式,模型越複雜,規則化值就越大。比如,規則化項可以是模型引數向量的範數。然而,不同的選擇對引數w的約束不同,取得的效果也不同,但我們在論文中常見的都聚集在:零範數、一範數、二範數、跡範數、Frobenius範數和核範數等等。這麼多範數,到底它們表達啥意思?具有啥能力?什麼時候才能用?什麼時候需要用呢?不急不急,下面我們挑幾個常見的娓娓道來。
一、L0範數與L1範數
L0範數是指向量中非0的元素的個數。如果我們用L0範數來規則化一個引數矩陣W的話,就是希望W的大部分元素都是0。這太直觀了,太露骨了吧,換句話說,讓引數W是稀疏的。OK,看到了“稀疏”二字,大家都應該從當下風風火火的“壓縮感知”和“稀疏編碼”中醒悟過來,原來用的漫山遍野的“稀疏”就是通過這玩意來實現的。但你又開始懷疑了,是這樣嗎?看到的papers世界中,稀疏不是都通過L1範數來實現嗎?腦海裡是不是到處都是||W||1影子呀!幾乎是擡頭不見低頭見。沒錯,這就是這節的題目把L0和L1放在一起的原因,因為他們有著某種不尋常的關係。那我們再來看看L1範數是什麼?它為什麼可以實現稀疏?為什麼大家都用L1範數去實現稀疏,而不是L0範數呢?
L1範數是指向量中各個元素絕對值之和,也有個美稱叫“稀疏規則運算元”(Lasso regularization)。現在我們來分析下這個價值一個億的問題:為什麼L1範數會使權值稀疏?有人可能會這樣給你回答“它是L0範數的最優凸近似”。實際上,還存在一個更美的回答:任何的規則化運算元,如果他在Wi=0的地方不可微,並且可以分解為一個“求和”的形式,那麼這個規則化運算元就可以實現稀疏。這說是這麼說,W的L1範數是絕對值,|w|在w=0處是不可微,但這還是不夠直觀。這裡因為我們需要和L2範數進行對比分析。所以關於L1範數的直觀理解,請待會看看第二節。
對了,上面還有一個問題:既然L0可以實現稀疏,為什麼不用L0,而要用L1呢?個人理解一是因為L0範數很難優化求解(NP難問題),二是L1範數是L0範數的最優凸近似,而且它比L0範數要容易優化求解。所以大家才把目光和萬千寵愛轉於L1範數。

OK,來個一句話總結:L1範數和L0範數可以實現稀疏,L1因具有比L0更好的優化求解特性而被廣泛應用。
好,到這裡,我們大概知道了L1可以實現稀疏,但我們會想呀,為什麼要稀疏?讓我們的引數稀疏有什麼好處呢?這裡扯兩點:
1)特徵選擇(Feature Selection):
大家對稀疏規則化趨之若鶩的一個關鍵原因在於它能實現特徵的自動選擇。一般來說,xi的大部分元素(也就是特徵)都是和最終的輸出yi沒有關係或者不提供任何資訊的,在最小化目標函式的時候考慮xi這些額外的特徵,雖然可以獲得更小的訓練誤差,但在預測新的樣本時,這些沒用的資訊反而會被考慮,從而干擾了對正確yi的預測。稀疏規則化運算元的引入就是為了完成特徵自動選擇的光榮使命,它會學習地去掉這些沒有資訊的特徵,也就是把這些特徵對應的權重置為0。
2)可解釋性(Interpretability):
另一個青睞於稀疏的理由是,模型更容易解釋。例如患某種病的概率是y,然後我們收集到的資料x是1000維的,也就是我們需要尋找這1000種因素到底是怎麼影響患上這種病的概率的。假設我們這個是個迴歸模型:y=w1*x1+w2*x2+…+w1000*x1000+b(當然了,為了讓y限定在[0,1]的範圍,一般還得加個Logistic函式)。通過學習,如果最後學習到的w*就只有很少的非零元素,例如只有5個非零的wi,那麼我們就有理由相信,這些對應的特徵在患病分析上面提供的資訊是巨大的,決策性的。也就是說,患不患這種病只和這5個因素有關,那醫生就好分析多了。但如果1000個wi都非0,醫生面對這1000種因素,累覺不愛。
二、L2範數
除了L1範數,還有一種更受寵幸的規則化範數是L2範數: ||W||2。它也不遜於L1範數,它有兩個美稱,在迴歸裡面,有人把有它的迴歸叫“嶺迴歸”(Ridge Regression),有人也叫它“權值衰減weight decay”。這用的很多吧,因為它的強大功效是改善機器學習裡面一個非常重要的問題:過擬合。至於過擬合是什麼,上面也解釋了,就是模型訓練時候的誤差很小,但在測試的時候誤差很大,也就是我們的模型複雜到可以擬合到我們的所有訓練樣本了,但在實際預測新的樣本的時候,糟糕的一塌糊塗。通俗的講就是應試能力很強,實際應用能力很差。擅長背誦知識,卻不懂得靈活利用知識。例如下圖所示(來自Ng的course):
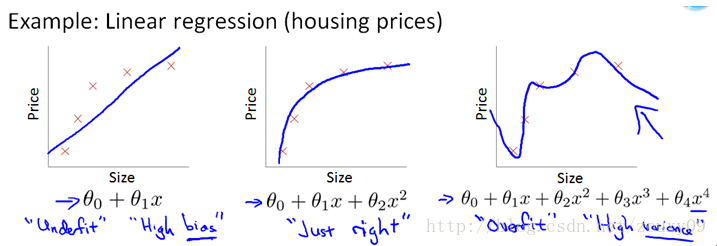
上面的圖是線性迴歸,下面的圖是Logistic迴歸,也可以說是分類的情況。從左到右分別是欠擬合(underfitting,也稱High-bias)、合適的擬合和過擬合(overfitting,也稱High variance)三種情況。可以看到,如果模型複雜(可以擬合任意的複雜函式),它可以讓我們的模型擬合所有的資料點,也就是基本上沒有誤差。對於迴歸來說,就是我們的函式曲線通過了所有的資料點,如上圖右。對分類來說,就是我們的函式曲線要把所有的資料點都分類正確,如下圖右。這兩種情況很明顯過擬合了。
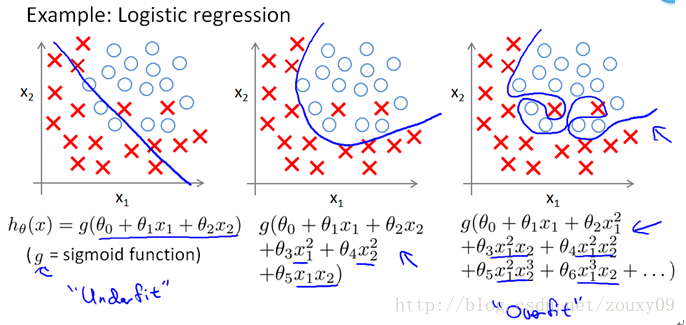
OK,那現在到我們非常關鍵的問題了,為什麼L2範數可以防止過擬合?回答這個問題之前,我們得先看看L2範數是個什麼東西。
L2範數是指向量各元素的平方和然後求平方根。我們讓L2範數的規則項||W||2最小,可以使得W的每個元素都很小,都接近於0,但與L1範數不同,它不會讓它等於0,而是接近於0,這裡是有很大的區別的哦。而越小的引數說明模型越簡單,越簡單的模型則越不容易產生過擬合現象。為什麼越小的引數說明模型越簡單?我也不懂,我的理解是:限制了引數很小,實際上就限制了多項式某些分量的影響很小(看上面線性迴歸的模型的那個擬合的圖),這樣就相當於減少引數個數。其實我也不太懂,希望大家可以指點下。
這裡也一句話總結下:通過L2範數,我們可以實現了對模型空間的限制,從而在一定程度上避免了過擬合。
L2範數的好處是什麼呢?這裡也扯上兩點:
1)學習理論的角度:
從學習理論的角度來說,L2範數可以防止過擬合,提升模型的泛化能力。
2)優化計算的角度:
從優化或者數值計算的角度來說,L2範數有助於處理 condition number不好的情況下矩陣求逆很困難的問題。哎,等等,這condition number是啥?我先google一下哈。
這裡我們也故作高雅的來聊聊優化問題。優化有兩大難題,一是:區域性最小值,二是:ill-condition病態問題。前者俺就不說了,大家都懂吧,我們要找的是全域性最小值,如果區域性最小值太多,那我們的優化演算法就很容易陷入區域性最小而不能自拔,這很明顯不是觀眾願意看到的劇情。那下面我們來聊聊ill-condition。ill-condition對應的是well-condition。那他們分別代表什麼?假設我們有個方程組AX=b,我們需要求解X。如果A或者b稍微的改變,會使得X的解發生很大的改變,那麼這個方程組系統就是ill-condition的,反之就是well-condition的。我們具體舉個例子吧:
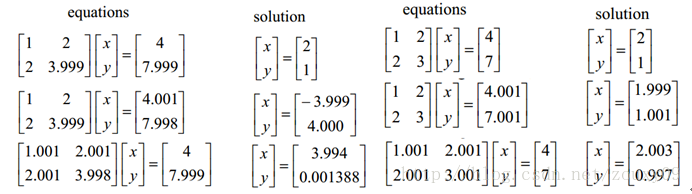
咱們先看左邊的那個。第一行假設是我們的AX=b,第二行我們稍微改變下b,得到的x和沒改變前的差別很大,看到吧。第三行我們稍微改變下係數矩陣A,可以看到結果的變化也很大。換句話來說,這個系統的解對係數矩陣A或者b太敏感了。又因為一般我們的係數矩陣A和b是從實驗資料裡面估計得到的,所以它是存在誤差的,如果我們的系統對這個誤差是可以容忍的就還好,但系統對這個誤差太敏感了,以至於我們的解的誤差更大,那這個解就太不靠譜了。所以這個方程組系統就是ill-conditioned病態的,不正常的,不穩定的,有問題的,哈哈。這清楚了吧。右邊那個就叫well-condition的系統了。
還是再囉嗦一下吧,對於一個ill-condition的系統,我的輸入稍微改變下,輸出就發生很大的改變,這不好啊,這表明我們的系統不能實用啊。你想想看,例如對於一個迴歸問題y=f(x),我們是用訓練樣本x去訓練模型f,使得y儘量輸出我們期待的值,例如0。那假如我們遇到一個樣本x’,這個樣本和訓練樣本x差別很小,面對他,系統本應該輸出和上面的y差不多的值的,例如0.00001,最後卻給我輸出了一個0.9999,這很明顯不對呀。就好像,你很熟悉的一個人臉上長了個青春痘,你就不認識他了,那你大腦就太差勁了,哈哈。所以如果一個系統是ill-conditioned病態的,我們就會對它的結果產生懷疑。那到底要相信它多少呢?我們得找個標準來衡量吧,因為有些系統的病沒那麼重,它的結果還是可以相信的,不能一刀切吧。終於回來了,上面的condition number就是拿來衡量ill-condition系統的可信度的。condition number衡量的是輸入發生微小變化的時候,輸出會發生多大的變化。也就是系統對微小變化的敏感度。condition number值小的就是well-conditioned的,大的就是ill-conditioned的。
如果方陣A是非奇異的,那麼A的conditionnumber定義為:
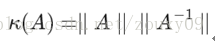
也就是矩陣A的norm乘以它的逆的norm。所以具體的值是多少,就要看你選擇的norm是什麼了。如果方陣A是奇異的,那麼A的condition number就是正無窮大了。實際上,每一個可逆方陣都存在一個condition number。但如果要計算它,我們需要先知道這個方陣的norm(範數)和Machine Epsilon(機器的精度)。為什麼要範數?範數就相當於衡量一個矩陣的大小,我們知道矩陣是沒有大小的,當上面不是要衡量一個矩陣A或者向量b變化的時候,我們的解x變化的大小嗎?所以肯定得要有一個東西來度量矩陣和向量的大小吧?對了,他就是範數,表示矩陣大小或者向量長度。OK,經過比較簡單的證明,對於AX=b,我們可以得到以下的結論:
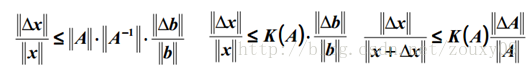
也就是我們的解x的相對變化和A或者b的相對變化是有像上面那樣的關係的,其中k(A)的值就相當於倍率,看到了嗎?相當於x變化的界。
對condition number來個一句話總結:conditionnumber是一個矩陣(或者它所描述的線性系統)的穩定性或者敏感度的度量,如果一個矩陣的condition number在1附近,那麼它就是well-conditioned的,如果遠大於1,那麼它就是ill-conditioned的,如果一個系統是ill-conditioned的,它的輸出結果就不要太相信了。
好了,對這麼一個東西,已經說了好多了。對了,我們為什麼聊到這個的了?回到第一句話:從優化或者數值計算的角度來說,L2範數有助於處理 condition number不好的情況下矩陣求逆很困難的問題。因為目標函式如果是二次的,對於線性迴歸來說,那實際上是有解析解的,求導並令導數等於零即可得到最優解為:
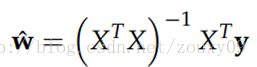
然而,如果當我們的樣本X的數目比每個樣本的維度還要小的時候,矩陣XTX將會不是滿秩的,也就是XTX會變得不可逆,所以w*就沒辦法直接計算出來了。或者更確切地說,將會有無窮多個解(因為我們方程組的個數小於未知數的個數)。也就是說,我們的資料不足以確定一個解,如果我們從所有可行解裡隨機選一個的話,很可能並不是真正好的解,總而言之,我們過擬合了。
但如果加上L2規則項,就變成了下面這種情況,就可以直接求逆了:
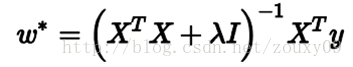
這裡面,專業點的描述是:要得到這個解,我們通常並不直接求矩陣的逆,而是通過解線性方程組的方式(例如高斯消元法)來計算。考慮沒有規則項的時候,也就是λ=0的情況,如果矩陣XTX的 condition number 很大的話,解線性方程組就會在數值上相當不穩定,而這個規則項的引入則可以改善condition number。
另外,如果使用迭代優化的演算法,condition number 太大仍然會導致問題:它會拖慢迭代的收斂速度,而規則項從優化的角度來看,實際上是將目標函式變成λ-strongly convex(λ強凸)的了。哎喲喲,這裡又出現個λ強凸,啥叫λ強凸呢?
當f滿足:
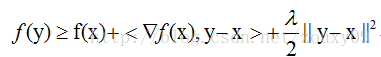
時,我們稱f為λ-stronglyconvex函式,其中引數λ>0。當λ=0時退回到普通convex 函式的定義。
在直觀的說明強凸之前,我們先看看普通的凸是怎樣的。假設我們讓f在x的地方做一階泰勒近似(一階泰勒展開忘了嗎?f(x)=f(a)+f'(a)(x-a)+o(||x-a||).):
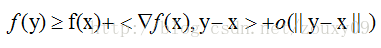
直觀來講,convex 性質是指函式曲線位於該點處的切線,也就是線性近似之上,而 strongly convex 則進一步要求位於該處的一個二次函式上方,也就是說要求函式不要太“平坦”而是可以保證有一定的“向上彎曲”的趨勢。專業點說,就是convex 可以保證函式在任意一點都處於它的一階泰勒函式之上,而strongly convex可以保證函式在任意一點都存在一個非常漂亮的二次下界quadratic lower bound。當然這是一個很強的假設,但是同時也是非常重要的假設。可能還不好理解,那我們畫個圖來形象的理解下。
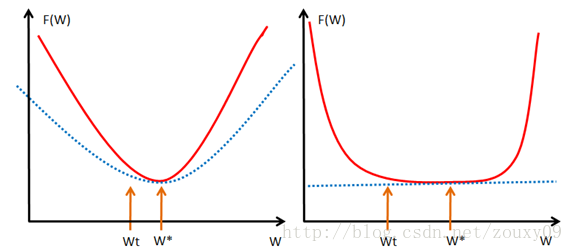
大家一看到上面這個圖就全明白了吧。不用我囉嗦了吧。還是囉嗦一下吧。我們取我們的最優解w*的地方。如果我們的函式f(w),見左圖,也就是紅色那個函式,都會位於藍色虛線的那根二次函式之上,這樣就算wt和w*離的比較近的時候,f(wt)和f(w*)的值差別還是挺大的,也就是會保證在我們的最優解w*附近的時候,還存在較大的梯度值,這樣我們才可以在比較少的迭代次數內達到w*。但對於右圖,紅色的函式f(w)只約束在一個線性的藍色虛線之上,假設是如右圖的很不幸的情況(非常平坦),那在wt還離我們的最優點w*很遠的時候,我們的近似梯度(f(wt)-f(w*))/(wt-w*)就已經非常小了,在wt處的近似梯度∂f/∂w就更小了,這樣通過梯度下降wt+1=wt-α*(∂f/∂w),我們得到的結果就是w的變化非常緩慢,像蝸牛一樣,非常緩慢的向我們的最優點w*爬動,那在有限的迭代時間內,它離我們的最優點還是很遠。
所以僅僅靠convex 性質並不能保證在梯度下降和有限的迭代次數的情況下得到的點w會是一個比較好的全域性最小點w*的近似點(插個話,有地方說,實際上讓迭代在接近最優的地方停止,也是一種規則化或者提高泛化效能的方法)。正如上面分析的那樣,如果f(w)在全域性最小點w*周圍是非常平坦的情況的話,我們有可能會找到一個很遠的點。但如果我們有“強凸”的話,就能對情況做一些控制,我們就可以得到一個更好的近似解。至於有多好嘛,這裡面有一個bound,這個 bound 的好壞也要取決於strongly convex性質中的常數α的大小。看到這裡,不知道大家學聰明瞭沒有。如果要獲得strongly convex怎麼做?最簡單的就是往裡面加入一項(α/2)*||w||2。
呃,講個strongly convex花了那麼多的篇幅。實際上,在梯度下降中,目標函式收斂速率的上界實際上是和矩陣XTX的 condition number有關,XTX的 condition number 越小,上界就越小,也就是收斂速度會越快。
這一個優化說了那麼多的東西。還是來個一句話總結吧:L2範數不但可以防止過擬合,還可以讓我們的優化求解變得穩定和快速。
好了,這裡兌現上面的承諾,來直觀的聊聊L1和L2的差別,為什麼一個讓絕對值最小,一個讓平方最小,會有那麼大的差別呢?我看到的有兩種幾何上直觀的解析:
1)下降速度:
我們知道,L1和L2都是規則化的方式,我們將權值引數以L1或者L2的方式放到代價函式裡面去。然後模型就會嘗試去最小化這些權值引數。而這個最小化就像一個下坡的過程,L1和L2的差別就在於這個“坡”不同,如下圖:L1就是按絕對值函式的“坡”下降的,而L2是按二次函式的“坡”下降。所以實際上在0附近,L1的下降速度比L2的下降速度要快。所以會非常快得降到0。不過我覺得這裡解釋的不太中肯,當然了也不知道是不是自己理解的問題。
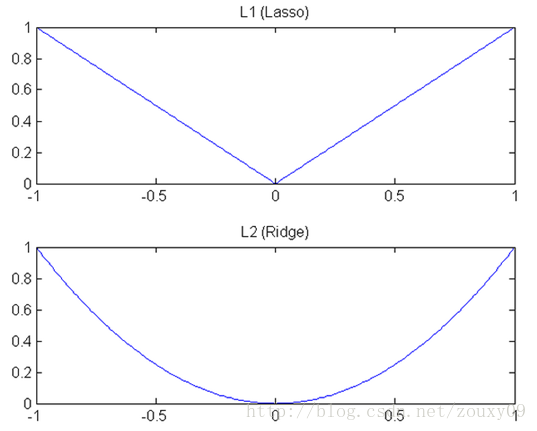
L1在江湖上人稱Lasso,L2人稱Ridge。不過這兩個名字還挺讓人迷糊的,看上面的圖片,Lasso的圖看起來就像ridge,而ridge的圖看起來就像lasso。
2)模型空間的限制:
實際上,對於L1和L2規則化的代價函式來說,我們可以寫成以下形式:
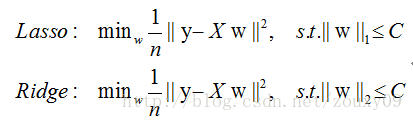
也就是說,我們將模型空間限制在w的一個L1-ball 中。為了便於視覺化,我們考慮兩維的情況,在(w1, w2)平面上可以畫出目標函式的等高線,而約束條件則成為平面上半徑為C的一個 norm ball 。等高線與 norm ball 首次相交的地方就是最優解:
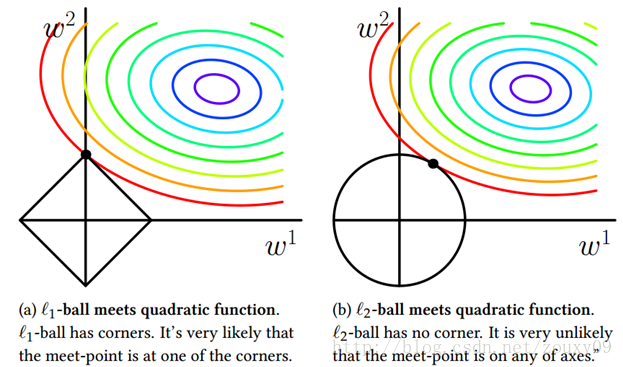
可以看到,L1-ball 與L2-ball 的不同就在於L1在和每個座標軸相交的地方都有“角”出現,而目標函式的測地線除非位置擺得非常好,大部分時候都會在角的地方相交。注意到在角的位置就會產生稀疏性,例如圖中的相交點就有w1=0,而更高維的時候(想象一下三維的L1-ball 是什麼樣的?)除了角點以外,還有很多邊的輪廓也是既有很大的概率成為第一次相交的地方,又會產生稀疏性。
相比之下,L2-ball 就沒有這樣的性質,因為沒有角,所以第一次相交的地方出現在具有稀疏性的位置的概率就變得非常小了。這就從直觀上來解釋了為什麼L1-regularization 能產生稀疏性,而L2-regularization 不行的原因了。
因此,一句話總結就是:L1會趨向於產生少量的特徵,而其他的特徵都是0,而L2會選擇更多的特徵,這些特徵都會接近於0。Lasso在特徵選擇時候非常有用,而Ridge就只是一種規則化而已。
三、核範數
核範數||W||*是指矩陣奇異值的和,英文稱呼叫Nuclear Norm。這個相對於上面火熱的L1和L2來說,可能大家就會陌生點。那它是幹嘛用的呢?霸氣登場:約束Low-Rank(低秩)。OK,OK,那我們得知道Low-Rank是啥?用來幹啥的?
我們先來回憶下線性代數裡面“秩”到底是啥?舉個簡單的例子吧:
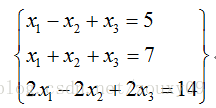
對上面的線性方程組,第一個方程和第二個方程有不同的解,而第2個方程和第3個方程的解完全相同。從這個意義上說,第3個方程是“多餘”的,因為它沒有帶來任何的資訊量,把它去掉,所得的方程組與原來的方程組同解。為了從方程組中去掉多餘的方程,自然就匯出了“矩陣的秩”這一概念。
還記得我們怎麼手工求矩陣的秩嗎?為了求矩陣A的秩,我們是通過矩陣初等變換把A化為階梯型矩陣,若該階梯型矩陣有r個非零行,那A的秩rank(A)就等於r。從物理意義上講,矩陣的秩度量的就是矩陣的行列之間的相關性。如果矩陣的各行或列是線性無關的,矩陣就是滿秩的,也就是秩等於行數。回到上面線性方程組來說吧,因為線性方程組可以用矩陣描述嘛。秩就表示了有多少個有用的方程了。上面的方程組有3個方程,實際上只有2個是有用的,一個是多餘的,所以對應的矩陣的秩就是2了。
OK。既然秩可以度量相關性,而矩陣的相關性實際上有帶有了矩陣的結構資訊。如果矩陣之間各行的相關性很強,那麼就表示這個矩陣實際可以投影到更低維的線性子空間,也就是用幾個向量就可以完全表達了,它就是低秩的。所以我們總結的一點就是:如果矩陣表達的是結構性資訊,例如影象、使用者-推薦表等等,那麼這個矩陣各行之間存在這一定的相關性,那這個矩陣一般就是低秩的。
如果X是一個m行n列的數值矩陣,rank(X)是X的秩,假如rank (X)遠小於m和n,則我們稱X是低秩矩陣。低秩矩陣每行或每列都可以用其他的行或列線性表出,可見它包含大量的冗餘資訊。利用這種冗餘資訊,可以對缺失資料進行恢復,也可以對資料進行特徵提取。
好了,低秩有了,那約束低秩只是約束rank(w)呀,和我們這節的核範數有什麼關係呢?他們的關係和L0與L1的關係一樣。因為rank()是非凸的,在優化問題裡面很難求解,那麼就需要尋找它的凸近似來近似它了。對,你沒猜錯,rank(w)的凸近似就是核範數||W||*。
好了,到這裡,我也沒什麼好說的了,因為我也是稍微翻看了下這個東西,所以也還沒有深入去看它。但我發現了這玩意還有很多很有意思的應用,下面我們舉幾個典型的吧。
1)矩陣填充(Matrix Completion):
我們首先說說矩陣填充用在哪。一個主流的應用是在推薦系統裡面。我們知道,推薦系統有一種方法是通過分析使用者的歷史記錄來給使用者推薦的。例如我們在看一部電影的時候,如果喜歡看,就會給它打個分,例如3顆星。然後系統,例如Netflix等知名網站就會分析這些資料,看看到底每部影片的題材到底是怎樣的?針對每個人,喜歡怎樣的電影,然後會給對應的使用者推薦相似題材的電影。但有一個問題是:我們的網站上面有非常多的使用者,也有非常多的影片,不是所有的使用者都看過說有的電影,不是所有看過某電影的使用者都會給它評分。假設我們用一個“使用者-影片”的矩陣來描述這些記錄,例如下圖,可以看到,會有很多空白的地方。如果這些空白的地方存在,我們是很難對這個矩陣進行分析的,所以在分析之前,一般需要先對其進行補全。也叫矩陣填充。
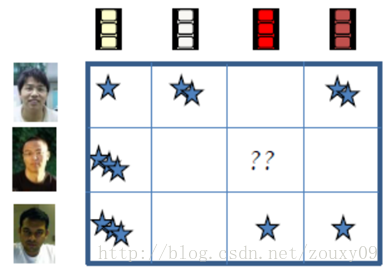
那到底怎麼填呢?如何才能無中生有呢?每個空白的地方的資訊是否蘊含在其他已有的資訊之上了呢?如果有,怎麼提取出來呢?Yeah,這就是低秩生效的地方了。這叫低秩矩陣重構問題,它可以用如下的模型表述:已知資料是一個給定的m*n矩陣A,如果其中一些元素因為某種原因丟失了,我們能否根據其他行和列的元素,將這些元素恢復?當然,如果沒有其他的參考條件,想要確定這些資料很困難。但如果我們已知A的秩rank(A)<<m且rank(A)<<n,那麼我們可以通過矩陣各行(列)之間的線性相關將丟失的元素求出。你會問,這種假定我們要恢復的矩陣是低秩的,合理嗎?實際上是十分合理的,比如一個使用者對某電影評分是其他使用者對這部電影評分的線性組合。所以,通過低秩重構就可以預測使用者對其未評價過的視訊的喜好程度。從而對矩陣進行填充。
2)魯棒PCA:
主成分分析,這種方法可以有效的找出資料中最“主要"的元素和結構,去除噪音和冗餘,將原有的複雜資料降維,揭示隱藏在複雜資料背後的簡單結構。我們知道,最簡單的主成分分析方法就是PCA了。從線性代數的角度看,PCA的目標就是使用另一組基去重新描述得到的資料空間。希望在這組新的基下,能儘量揭示原有的資料間的關係。這個維度即最重要的“主元"。PCA的目標就是找到這樣的“主元”,最大程度的去除冗餘和噪音的干擾。
魯棒主成分分析(Robust PCA)考慮的是這樣一個問題:一般我們的資料矩陣X會包含結構資訊,也包含噪聲。那麼我們可以將這個矩陣分解為兩個矩陣相加,一個是低秩的(由於內部有一定的結構資訊,造成各行或列間是線性相關的),另一個是稀疏的(由於含有噪聲,而噪聲是稀疏的),則魯棒主成分分析可以寫成以下的優化問題:
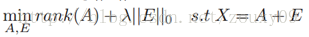
與經典PCA問題一樣,魯棒PCA本質上也是尋找資料在低維空間上的最佳投影問題。對於低秩資料觀測矩陣X,假如X受到隨機(稀疏)噪聲的影響,則X的低秩性就會破壞,使X變成滿秩的。所以我們就需要將X分解成包含其真實結構的低秩矩陣和稀疏噪聲矩陣之和。找到了低秩矩陣,實際上就找到了資料的本質低維空間。那有了PCA,為什麼還有這個Robust PCA呢?Robust在哪?因為PCA假設我們的資料的噪聲是高斯的,對於大的噪聲或者嚴重的離群點,PCA會被它影響,導致無法正常工作。而Robust PCA則不存在這個假設。它只是假設它的噪聲是稀疏的,而不管噪聲的強弱如何。
由於rank和L0範數在優化上存在非凸和非光滑特性,所以我們一般將它轉換成求解以下一個鬆弛的凸優化問題:
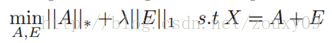
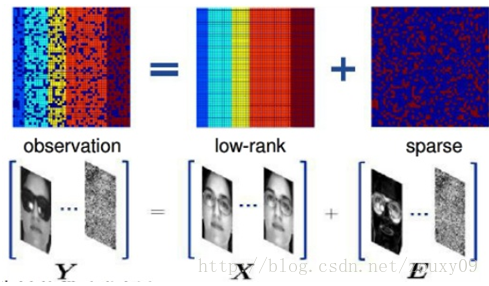
說個應用吧。考慮同一副人臉的多幅影象,如果將每一副人臉影象看成是一個行向量,並將這些向量組成一個矩陣的話,那麼可以肯定,理論上,這個矩陣應當是低秩的。但是,由於在實際操作中,每幅影象會受到一定程度的影響,例如遮擋,噪聲,光照變化,平移等。這些干擾因素的作用可以看做是一個噪聲矩陣的作用。所以我們可以把我們的同一個人臉的多個不同情況下的圖片各自拉長一列,然後擺成一個矩陣,對這個矩陣進行低秩和稀疏的分解,就可以得到乾淨的人臉影象(低秩矩陣)和噪聲的矩陣了(稀疏矩陣),例如光照,遮擋等等。至於這個的用途,你懂得。
3)背景建模:
背景建模的最簡單情形是從固定攝相機拍攝的視訊中分離背景和前景。我們將視訊影象序列的每一幀影象畫素值拉成一個列向量,那麼多個幀也就是多個列向量就組成了一個觀測矩陣。由於背景比較穩定,影象序列幀與幀之間具有極大的相似性,所以僅由背景畫素組成的矩陣具有低秩特性;同時由於前景是移動的物體,佔據畫素比例較低,故前景畫素組成的矩陣具有稀疏特性。視訊觀測矩陣就是這兩種特性矩陣的疊加,因此,可以說視訊背景建模實現的過程就是低秩矩陣恢復的過程。

4)變換不變低秩紋理(TILT):
以上章節所介紹的針對影象的低秩逼近演算法,僅僅考慮影象樣本之間畫素的相似性,卻沒有考慮到影象作為二維的畫素集合,其本身所具有的規律性。事實上,對於未加旋轉的影象,由於影象的對稱性與自相似性,我們可以將其看做是一個帶噪聲的低秩矩陣。當影象由端正發生旋轉時,影象的對稱性和規律性就會被破壞,也就是說各行畫素間的線性相關性被破壞,因此矩陣的秩就會增加。
低秩紋理對映演算法(TransformInvariant Low-rank Textures,TILT)是一種用低秩性與噪聲的稀疏性進行低秩紋理恢復的演算法。它的思想是通過幾何變換τ把D所代表的影象區域校正成正則的區域,如具有橫平豎直、對稱等特性,這些特性可以通過低秩性來進行刻畫。

低秩的應用非常多,大家有興趣的可以去找些資料深入瞭解下。
四、規則化引數的選擇
現在我們回過頭來看看我們的目標函式:
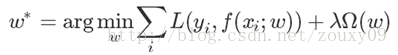
裡面除了loss和規則項兩塊外,還有一個引數λ。它也有個霸氣的名字,叫hyper-parameters(超參)。你不要看它勢單力薄的,它非常重要。它的取值很大時候會決定我們的模型的效能,事關模型生死。它主要是平衡loss和規則項這兩項的,λ越大,就表示規則項要比模型訓練誤差更重要,也就是相比於要模型擬合我們的資料,我們更希望我們的模型能滿足我們約束的Ω(w)的特性。反之亦然。舉個極端情況,例如λ=0時,就沒有後面那一項,代價函式的最小化全部取決於第一項,也就是集全力使得輸出和期待輸出差別最小,那什麼時候差別最小啊,當然是我們的函式或者曲線可以經過所有的點了,這時候誤差就接近0,也就是過擬合了。它可以複雜的代表或者記憶所有這些樣本,但對於一個新來的樣本泛化能力就不行了。畢竟新的樣本會和訓練樣本有差別的嘛。
那我們真正需要什麼呢?我們希望我們的模型既可以擬合我們的資料,又具有我們約束它的特性。只有它們兩者的完美結合,才能讓我們的模型在我們的任務上發揮強大的效能。所以如何討好它,是非常重要。在這點上,大家可能深有體會。還記得你復現了很多論文,然後復現出來的程式碼跑出來的準確率沒有論文說的那麼高,甚至還差之萬里。這時候,你就會懷疑,到底是論文的問題,還是你實現的問題?實際上,除了這兩個問題,我們還需要深入思考另一個問題:論文提出的模型是否具有hyper-parameters?論文給出了它們的實驗取值了嗎?經驗取值還是經過交叉驗證的取值?這個問題是逃不掉的,因為幾乎任何一個問題或者模型都會具有hyper-parameters,只是有時候它是隱藏著的,你看不到而已,但一旦你發現了,證明你倆有緣,那請試著去修改下它吧,有可能有“奇蹟”發生哦。
OK,回到問題本身。我們選擇引數λ的目標是什麼?我們希望模型的訓練誤差和泛化能力都很強。這時候,你有可能還反映過來,這不是說我們的泛化效能是我們的引數λ的函式嗎?那我們為什麼按優化那一套,選擇能最大化泛化效能的λ呢?Oh,sorry to tell you that,因為泛化效能並不是λ的簡單的函式!它具有很多的區域性最大值!而且它的搜尋空間很大。所以大家確定引數的時候,一是嘗試很多的經驗值,這和那些在這個領域摸爬打滾的大師是沒得比的。當然了,對於某些模型,大師們也整理了些調參經驗給我們。例如Hinton大哥的那篇A Practical Guide to Training RestrictedBoltzmann Machines等等。還有一種方法是通過分析我們的模型來選擇。怎麼做呢?就是在訓練之前,我們大概計算下這時候的loss項的值是多少?Ω(w)的值是多少?然後針對他們的比例來確定我們的λ,這種啟發式的方法會縮小我們的搜尋空間。另外一種最常見的方法就是交叉驗證Cross validation了。先把我們的訓練資料庫分成幾份,然後取一部分做訓練集,一部分做測試集,然後選擇不同的λ用這個訓練集來訓練N個模型,然後用這個測試集來測試我們的模型,取N模型裡面的測試誤差最小對應的λ來作為我們最終的λ。如果我們的模型一次訓練時間就很長了,那麼很明顯在有限的時間內,我們只能測試非常少的λ。例如假設我們的模型需要訓練1天,這在深度學習裡面是家常便飯了,然後我們有一個星期,那我們只能測試7個不同的λ。這就讓你遇到最好的λ那是上輩子積下來的福氣了。那有什麼方法呢?兩種:一是儘量測試7個比較靠譜的λ,或者說λ的搜尋空間我們儘量廣點,所以一般對λ的搜尋空間的選擇一般就是2的多少次方了,從-10到10啊什麼的。但這種方法還是不大靠譜,最好的方法還是儘量讓我們的模型訓練的時間減少。例如假設我們優化了我們的模型訓練,使得我們的訓練時間減少到2個小時。那麼一個星期我們就可以對模型訓練7*24/2=84次,也就是說,我們可以在84個λ裡面尋找最好的λ。這讓你遇見最好的λ的概率就大多了吧。這就是為什麼我們要選擇優化也就是收斂速度快的演算法,為什麼要用GPU、多核、叢集等來進行模型訓練、為什麼具有強大計算機資源的工業界能做很多學術界也做不了的事情(當然了,大資料也是一個原因)的原因了。
努力做個“調參”高手吧!祝願大家都能“調得一手好參”!
五、參考資料