
Redis與資料庫資料同步解決方案
資料庫同步到Redis
我們大多傾向於使用這種方式,也就是將資料庫中的變化同步到Redis,這種更加可靠。Redis在這裡只是做快取。
方案1
做快取,就要遵循快取的語義規定:
讀:讀快取redis,沒有,讀mysql,並將mysql的值寫入到redis。
寫:寫mysql,成功後,更新或者失效掉快取redis中的值。
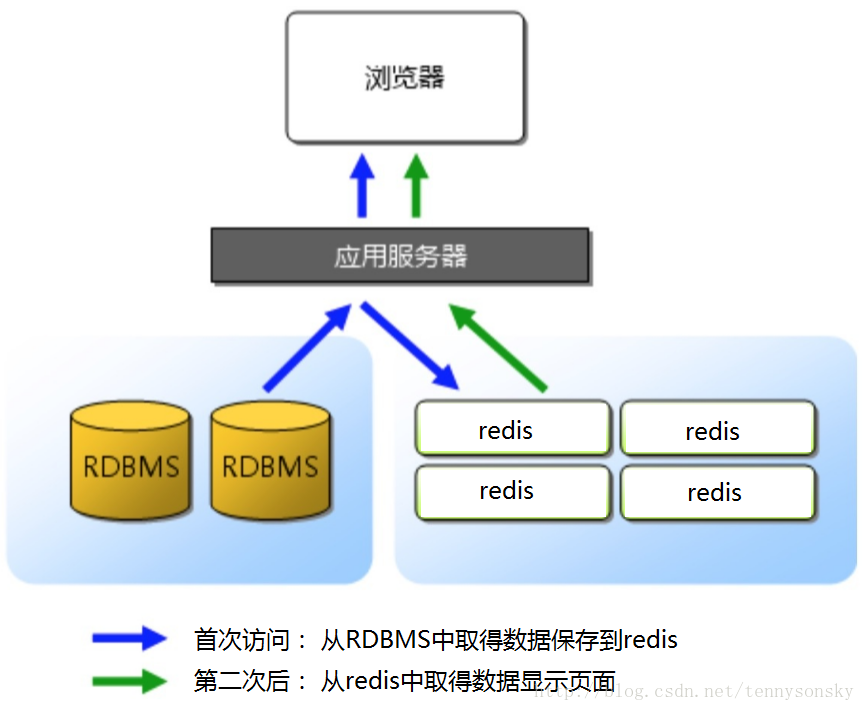
對於一致性要求高的,從資料庫中讀,比如金融,交易等資料。其他的從Redis讀。
這種方案的好處是由mysql,常規的關係型資料庫來保證持久化,一致性等,不容易出錯。
方案2
這裡還可以基於binlog使用mysql_udf_redis,將資料庫中的資料同步到Redis。
但是很明顯的,這將整體的複雜性提高了,而且本來我們在系統程式碼中能很輕易完成的功能,現在需要依賴第三方工具,而且系統的整個邊界擴大了,變得更加不穩定也不好管理了。

Redis同步到資料庫
也就是說將Redis中的資料變化同步到資料庫,那麼這裡是將Redis做為db,而真的db,資料庫只作為備份。(注意,這裡是一種不同看待事物的方式)。
這樣做的好處是:大大減小了資料庫的壓力,但是用redis做記憶體資料庫,狀態很不穩定。
雖然redis也有持久化機制,但是redis叢集宕機後的重啟,資料加熱都很耗時。
另一方面,隨著大量插入或者更新導致redis持久化操作會嚴重拖累作為記憶體KV資料庫的優勢。
方案1
將redis變更復制一份,丟到佇列中,給mysql消費。
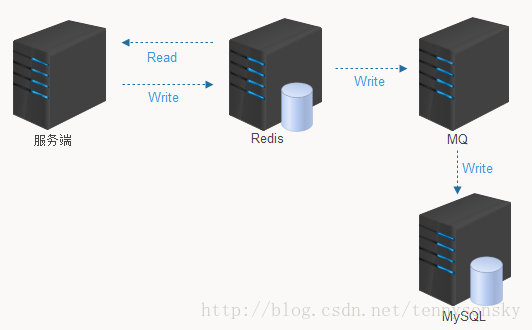
很明顯這種方案,只能保證最終一致性,而且變更資料複製,佇列維護,這些雜七雜八的東西太複雜,拋棄。
具體做法是:寫redis時,同時將資料寫到redis維護的另外一個佇列中,但這樣又要增加記憶體消耗了。
其實還有一種方式是使用redis的pipeline通知機制,但是redis是不保證的一定通知到的(得到被通知方的ack)。
方案2
定時重新整理redis中的最新資料到mysql。
很明顯的,無論定時任務的間距有多小,都會留下時間縫隙,如果發生宕機,故障等都會造成資料的不一致性。
雖然可以通過:比較redis和資料庫中的資料,同步那些需要同步的變化資料,但是會加大計算量和程式的複雜度。
