
高效程式設計之hashmap你不看就會忘記的知識點
以前菜得不能看的時候看Java的招聘要求:Java基礎紮實,熟悉常用集合類,多執行緒,IO,網路程式設計,經常會疑惑,集合類不就ArrayList,HashMap會用,熟悉下API不就好了麼,知道得越多才會發覺不知道的還有好多! 一入Java深似海啊 的
的
本文使用的原始碼是jdk1.7的原始碼,hashmap每個版本都發生了改變,原始碼都不同,但原理都是一樣的,可以參考一下;
讀下文前可以先思考以下這幾個問題,帶著問題去閱讀,收穫更大;
1、平時我為什麼要用hashmap?key和value是以什麼樣的形式存在的?
2、我瞭解hashmap的內部結構和實現原理嗎?
3、hashmap構造方法的引數有哪些,有什麼用?
4、用hashmap的時候需不需要給他一個初始化大小?如果要該怎麼定義?
5、不起眼的hashcode和equals方法為什麼在hashmap中至關重要?
6、什麼是雜湊衝突?發生雜湊衝突好還是不好?不好該怎麼解決?
7、hashmap有什麼缺點?它跟hashtable有什麼效能區別?
從下面的兩張圖可以看到,hashmap是由陣列和連結串列組成的;
陣列:陣列儲存區間是連續的,佔用記憶體嚴重,故空間複雜的很大。但陣列的二分查詢時間複雜度小,為O(1);陣列的特點是:定址容易,插入和刪除困難;
連結串列:連結串列儲存區間離散,佔用記憶體比較寬鬆,故空間複雜度很小,但時間複雜度很大,達O(N)。連結串列的
雜湊表:這時候該引出雜湊表了,雜湊表定址容易,插入刪除也容易,同事還滿足了資料的查詢方便,同時不佔用太多的內容空間,使用也十分方便!簡直牛逼啊~
先盜兩張圖...因為我不會畫...
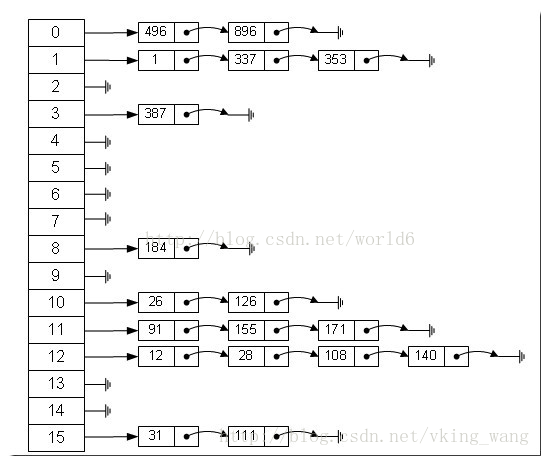
hashmap是基於Map介面實現、允許null鍵/值、非同步這個大家應該都是知道的... 這個時候應該對hashmap有個感性的認識了
那我們從API裡面來看看hashmap的構造方法,初始一下 initialCapacity 和 loadFactor 兩個名詞:
構造一個具有預設初始容量 (16) 和預設載入因子 (0.75)
的空HashMap。
(int initialCapacity)
(int initialCapacity, float loadFactor)
構造一個帶指定初始容量和載入因子的空HashMap。
initialCapacity是雜湊表的陣列的初始大小,loadFactor是載入因子;
HashMap的預設大小是16,那麼他的陣列長度就是0-15;預設載入因子是0.75;
為什麼是16呢不是其他的數字呢?為什麼預設的載入因子是0.75呢? 留個懸念哈~後面會提到的!
我們可以看到hashmap裡面存放的是一個一個的Entry物件,(下文中的entry/entry物件即為此處的Entry物件)
我們看看看看hashmap是如何定義的Entry物件;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}final K key :表示key是不能改變的 final關鍵字!
value:這沒啥好說的;
Entry<k,v> next 指向下一個節點;
int hash: 這個hash
是一個雜湊碼 是這樣得到的:int hash = hash(key.hashcode());下文會有詳細講解~
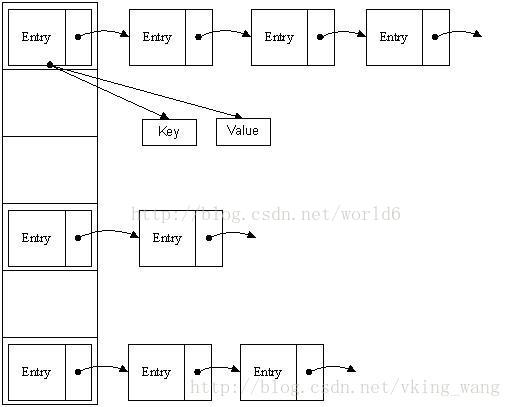
重點部分來了!
HashMap的put方法:
put方法大致的思路是:
1、對key的hashCode()做hash,然後再計算存到數組裡的下標;
2、如果沒發生衝突直接放到數組裡;
3、如果衝突了,以連結串列的形式存在對應的陣列[ i ]中 ;
4、如果衝突導致連結串列過長(大於等於TREEIFY_THRESHOLD),就把連結串列轉換成紅黑樹;
5、如果節點已經存在就替換old value(保證key的唯一性)
6、如果陣列滿了(超過load factor*current capacity),就要resize(擴容)。
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}這是jdk1.7的原始碼,1.8只是多了一個新特性,當連結串列的長度>7的時候,連結串列轉換為紅黑樹提高查詢的效率;
程式碼有註釋,我這裡再分析一次;首先通過key.hashcode()出雜湊碼,雜湊碼拿去做hash運算算出一個雜湊值,雜湊值(hash)跟陣列的長度做indexFor運算,就得到了一個entry物件要存到陣列的下標,這裡有一個要點! 就是這個hash運算的演算法設計,因為就算你拿不同的key去呼叫hashcode方法得到不同的值拿去做hash運算都會得到一個相同的值,然後把相同的雜湊值拿去做indexFor運算就會得到相同的 i ,這就發生了雜湊表的衝突~~ 發生衝突了怎麼辦呢?
這裡解釋原始碼裡的 if 中的判斷,因為hash(雜湊值)是會算出重複的(衝突嘛~),如果這個Entry物件的hash(雜湊值)和你拿進來的key算的雜湊值(hash=hash(key))是一樣的並且key也相等(==),那麼你放進來的這個entry物件是同一個物件,hashmap允許你的key為空,但是key不能相同,所以新進來的會覆蓋舊的;或者key.equals(k),如果這兩個物件通過hashmap重寫的equals方法判斷是一樣的,那也說明是同一個entry物件嘛!怎麼辦? 老辦法,新的覆蓋舊的!其他發生衝突的情況就把新加入的entry物件放到對應陣列下標位置的表頭,早進來的entry物件後移一個位置,這就形成了一個連結串列~~
好的,上面說的挺囉嗦的,下面來個1.8版本的總結,1.8跟1.7差不多~,1.8只是多了一個新特性,當連結串列的長度>=8的時候,連結串列轉換為紅黑樹提高查詢的效率;
1.8 連結串列轉紅黑樹的原始碼
static final int TREEIFY_THRESHOLD = 8;
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;新增entry物件的時候如果會時刻判斷需不需要擴容陣列
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}會把陣列的大小從16擴容到32,那麼這時的情況就是,雜湊表的陣列有第12個元素時,陣列就會擴容到32;
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
boolean oldAltHashing = useAltHashing;
useAltHashing |= sun.misc.VM.isBooted() &&
(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean rehash = oldAltHashing ^ useAltHashing;
transfer(newTable, rehash);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}new Capacity 就是那個兩倍的陣列物件,(上面的2*table.length);
transf(newTable,rehash)這個方法是把原來那個未擴容前數組裡的所有entry物件複製到現在這個新陣列中來;此時的域值 threshold 的大小就是新的陣列大小 * 0.75 ;
說完put,說get~
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
//先定位到陣列元素,再遍歷該元素處的連結串列
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}key==null,這個情況不用講了吧~
還是先算出雜湊碼的值,然後通過雜湊碼定位到陣列(table)下標,也就是常說的通過key就可以拿到value,hashmap底層都是通過key拿到entry物件,然後直接從entry物件裡拿到value的;
接著說:如果通過key找到了entry物件,進入if判斷,第一種情況:如果entry物件的雜湊碼和 傳進來key的雜湊碼是相等(都是int嘛,直接判斷是否相等)並且entry物件的key和你傳進來的key如果也相等那麼就認為是你的key跟你要找的key是同一個,那麼就直接return你要的value; 哦對了,這個Object k,是為了去接收entry物件的key(然後賦值給object的k)然後才好和你傳進來的key做比較,因為人家不知道你傳進來的是什麼型別的嘛,用object比就不會有型別轉換的錯誤;
第二種情況:如果e.hash == hash 然後你傳進來的key和entry物件的key連重寫後的equals後都一樣,那肯定就是同一個key了嘛;
不知道我這個菜鳥分析得怎麼樣,不過可以通過以下幾個問題來加深對HashMap的理解;
1. 什麼時候會使用HashMap?他有什麼特點?
是基於Map介面的實現,儲存鍵值對時,它可以接收null的鍵值,是非同步的執行緒不安全,HashMap儲存著Entry(hash, key, value, next)物件。
2. 你知道HashMap的工作原理嗎?
通過hash的方法,通過put和get儲存和獲取物件。儲存物件時,我們將key傳給put方法時,它呼叫hashCode計算hash從而得到儲存的陣列下標位置,進一步儲存,HashMap會根據當前陣列的佔用情況自動調整容量(超過域值時則resize為原來的2倍)。獲取物件時,我們將key傳給get方法,它呼叫hashCode計算hash從而得到陣列下標位置,並進一步呼叫equals()方法確定鍵值對。如果發生衝突的時候,Hashmap通過連結串列將產生碰撞衝突的元素組織起來,在Java 8中,如果一個數組中碰撞衝突的元素超過某個限制(預設是8),則使用紅黑樹來替換連結串列,從而提高速度。
3.為什麼要重寫hashcode和equals方法?
1、因為要得到雜湊碼(hash)的時候要通過key.hashcode()去得到key的雜湊碼才可以做hash運算;不論是put和get方法,都要使用equals方法,equals方法是object的一個方法,直接呼叫是比較記憶體(object.equals原始碼是用==做比較);
2、Java約定在用集合類中要重寫hashcode和equals方法; Effective java 這本書第二章有詳細的解釋為什麼要定義這樣的公約,感興趣的可以去看看;
4、 為什麼HashMap的初始大小是16?為什麼預設的載入因子是0.75?HashMap的大小超過了載入因子定義的容量,怎麼辦?
16是2的4次方,hashmap在put的時候會發生衝突,hashmap發生衝突是不可避免的,也是我們想要的,但是我們不想hashmap傻不拉幾的發生衝突,因為最壞的情況,hashmap所有的衝突都發生在同一個陣列下標的話,這個位置的連結串列過長,而其他陣列位置確實空的,這樣又hashmap還擴容不了,連結串列的查詢效率可想而知,這樣的話hashmap還有那麼牛逼嗎?把陣列的長度設計成為2的n次方,載入因子設計為0.75,會極大的優化衝突,使每個陣列的連結串列都差不多長(也不一定,概率問題);
至於為什麼? 這是資料結構相關的東西,當時是數學家設計的啊,你問我怎麼知道的? 不記得什麼時候看了篇論文還是部落格,上面是這樣說的~我真的印象很深的記得我看到過,如果你不信也沒辦法~ 反正是有這麼回事~
如果超過了負載因子,則會重新resize一個原來長度兩倍的HashMap。
5、如果兩個鍵的hashcode相同,你如何獲取物件的值?
獲取物件的值,那麼就是get方法咯,兩個key的hashcode相同說明 雜湊碼(hash)相同,
如果雜湊碼都相同了,那麼就會呼叫key.equals()去判斷在該雜湊碼得到的這個陣列下標的連結串列裡的entry物件是否有相同的物件;
如果有,那麼好,你直接拿這個entry物件的值即可;
6、用hashmap的時候需不需要給他一個初始化大小?如果要該怎麼定義?
此問題是博主自己想出來的,答案也是博主自己思考的一個結果,不一定對,提供一個思路!如果你有更好的回答,可以留言給我一起探討,謝謝啦~
最好是需要的,因為我們知道hashmap的陣列長度超過了他的域值會擴容,擴容的時候會把hashmap中所有的entry物件再計算一次他們在新陣列中的下標;可以想象一下,如果一個hashmap裡有10萬個entry物件了,如果要擴容,這10萬個entry物件的位置都要發生變化,這會有多影響系統性能?不優化一下嗎? 如何定義這個我也回答不了...因為我們只能初始化陣列的大小,並不會知道每個陣列元素的連結串列會有多長,我看同事他們建立hashmap的時候好像都沒有給引數,那麼如果這10萬條資料放到一個大小為16的hashmap裡,如果不擴容的話10萬條資料只放在陣列的11個元素中,那平均每個連結串列長度有接近1W,肯定不合理嗎,連結串列的查詢速度那麼慢,所以我們判斷必定會擴容,好!我們知道會擴容,但不知道會擴容幾次啊,這裡就是這個問題難的地方了,因為我們無法知道hashmap會擴容多少次,我們能做的就是減少他擴容的次數,同時又不讓hashmap佔太多記憶體~ 那我們就大膽的預測吧,比如有10萬條資料,我覺得至少hashmap陣列長度應該給1W吧,這樣我們就可以把hashmap的初始大小定義為2的14次方 16384,這樣陣列的長度我們就定義了1.6W,就算用了1W個,也不會擴容,也沒浪費更多的資源;如果你覺得10萬條資料可能用不到1W個數組這麼長,那你就把hashmap的初始大小定義為2的13次方,或者2的12次方;我們開始就定義一個大小總比我們不定義好(畢竟預設只有16)對吧?
7、我們可以用自定義的物件作為hashmap的key嗎?如果可以,你會自定義物件當做key嗎?如果不行說明原因。
可以使用自定義的物件作為hashmap的key,只要重寫hashcode和equals方法就可以了,原因見第三個問題的回答;
但我一般不會把自定義物件作為key,因為有Integer跟string給我用,沒必要使用自定義物件了,複雜,麻煩~
8、那你平時使用hashmap的時候一般用什麼當做key,為什麼?
Integer跟string呀,因為用他們用起來簡單啊,Entry物件的四個屬性中key是被final關鍵字修飾的,而Integer和string都是不可變的,直接使用Integer和string豈不美哉
9、hashmap並不能保證執行緒安全,如果要保證執行緒安全怎麼辦?
hashtable能保證執行緒安全,但有一種更高效的方式就是使用CocurrentHashMap來保證執行緒安全,同時效率又高;
hashtable是鎖住整個陣列,一次只能有一個執行緒去hashtable裡面拿,而CocurrentHashMap是隻鎖陣列[ i ] ,所以CocurrentHashMap的效率會比hashtable快很多,又比hashmap安全性要高,實在是居家旅行之首選~
10、那你還知道什麼類似hashmap的東西嗎?
有個安卓的大牛告訴我有 SarseArray , 安卓內部特有的一個API,因為hashmap用entry來儲存key和value,這裡entry涉及自動裝箱和拆箱,其實挺佔記憶體的;在key為Integer的場景可以使用SarseArray;(後半段來自搜尋的解釋)假設現在有這樣的情況,我們定義了一個長度為100的陣列,虛擬機器為我們開闢了100個單位的記憶體空間,但是我們只使用了很少(假設是5個)的一些單元,這樣就造成了記憶體空間的浪費。而 SparseArray 是一個優化的陣列,它的 key 是 Integer 型別而不是其他型別,是因為這個陣列是按照 key 值的大小來排序的。按照 key 值大小排序的好處是查詢的時候,可以使用二分查詢,而不是蠻力的遍歷整個陣列。這也是為什麼 SparseArray 適合替換 HashMap<Integer,<E>>,而不是任何 HashMap 的原因了。在這種情況下,原本需要100個單位記憶體空間而 SparseArray 只佔用了5個單位的記憶體(實際比5個單位要大一些,因為還有一些邏輯控制的記憶體消耗)。key 值被當成了陣列下標的功能來使用了。 安卓用SarseArray 很大一部分原因就是因為 SarseArray 比較節約記憶體;
結語:寫部落格是個自我總結的過程,其實這些知識點網上都有,隨便Google一下一把大,很多牛人都深入研究過hashmap,我寫的這些東西也都是看了上百篇別人的部落格總結下來的,因為自己在hashmap上以前花了很多時間去學習,但過一陣子遇到某個細節點的問題的時候總感覺不太記得了;這次為了寫這個部落格,花了6-7個小時,這個過程讓我加深了記憶,可能這幾年都不會忘掉這些了,下次用到hashmap的時候可以瞬間就想起這些;
首先感謝你看完了這麼長的文章,如果覺得有收穫的話,還請點一下下面的 " 頂 "按鈕,你的支援就是我寫作的動力,謝謝~