
阿里雲容器Kubernetes監控(一)
簡介
容器通過集裝箱式的編譯、打包、部署,大大提高了應用的迭代速度。對於架構師而言,容器帶來的是分鐘級的部署、秒級的伸縮與恢復、一個量級的迭代速度提升、50%左右的基礎成本節省。但是對於落地實施容器的開發者而言。80%的工作處理的是容器前和容器後的問題,容器前指的是如何本地開發、整合、測試並部署到容器環境;而容器後指的是如何對部署到容器環境後的監控、運維、告警與調優。今天我們主要來探討的是如何在容器的環境中進行資源維度的監控。
先談容器與監控
關於容器的監控方案有非常多的種類,大家耳熟能詳的一些元件包括:prometheus、Telegraf、InfluxDB、Cadvisor、Heapster等等。但是從原理上來講無外乎分為推模式採集與拉模式採集。推模式採集是指通過部署相應的agent,將監控的指標推送到server再進行資料聚合和報警的方式,例如Telegraf就是這種模式的代表。拉模式採集是指通過中心化的server使用API或者指令碼等方式從容器直接拉取資源利用率的方式,而prometheus則是這種方式的集大成者。和傳統應用監控相比,容器監控面臨更大的挑戰:首先由於容器更多的是在資源池中排程,傳統的靜態配置化的監控agent就變得非常麻煩,如果只在宿主機部署監控agent則會造成缺乏必要資訊來識別監控物件;其次容器的生命週期與傳統應用相比而言會更加短暫,而由容器抽象的上層概念例如swarm mode中的service或者kubernetes中的ReplicaSet、Deployment等等則沒有太好的辦法從採集的資料中進行反向的抽象,造成單純的容器監控資料無法有效的進行監控資料的聚合和告警,一旦應用的釋出可能會導致原有的監控與報警規則無法生效;最後容器的監控需要更多的維度,資源維度、邏輯資源的維度、應用的維度等等。
如何在容器服務上進行資源監控
其實容器之所以難以監控的主要原因在於無法將邏輯的概念和物理概念無法在監控資料、生命週期上面實現統一。阿里雲容器服務Kubernetes與雲監控進行了深度整合,用應用分組來抽象邏輯概念,今天我們來看下如何進行Kuberbetes的資源監控和告警。
首先Kubernetes節點從職能上分為Worker和Master兩種不同的節點。Master節點上面通常會部署管控型別的應用,整體的資源要求以強魯棒性為主;而Worker節點更多的承擔實際的Pod排程,整體的資源以排程能力為主。當你建立一個Kubernetes叢集時,容器服務會為你自動建立兩個資源分組,一個是Master組,一個是Worker組。Master組中包含了Master節點以及與其相關的負載均衡器。Worker組包含了所有的工作節點。
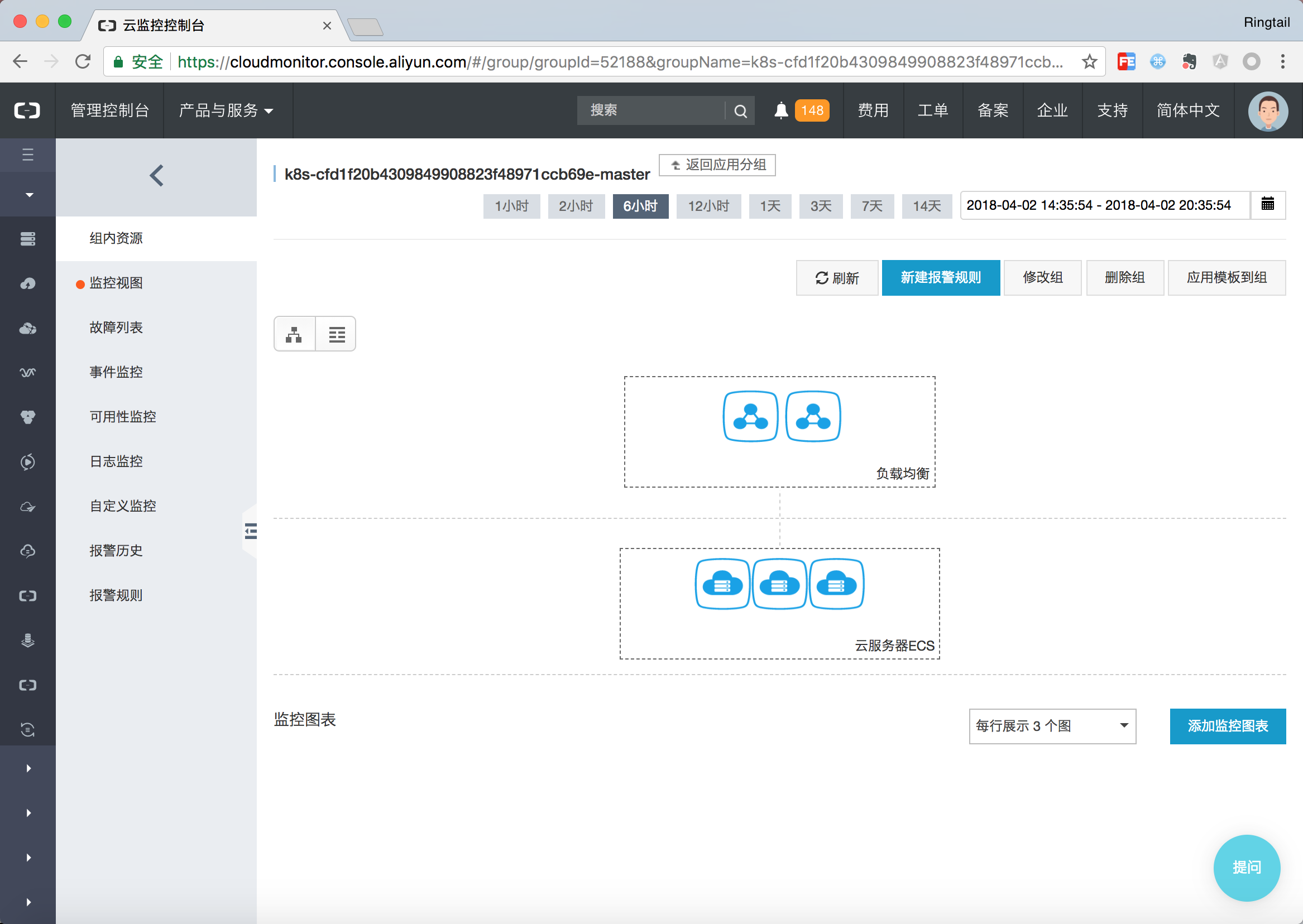
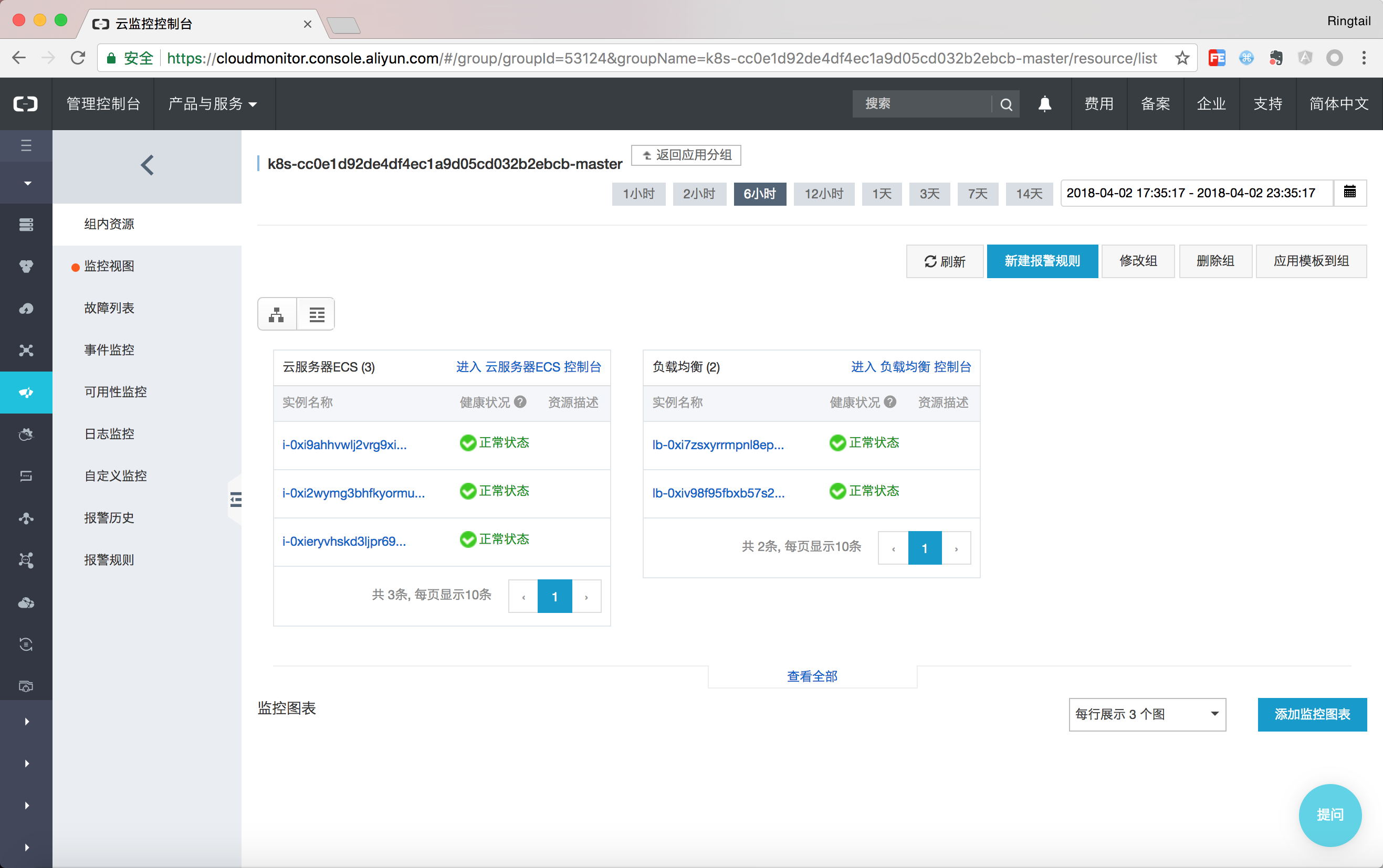
可以通過點選列表檢視顯示當前資源分組中的資源,例如本例中Master分組包含了三個Master節點以及2個SLB。另外任何在資源組下的資源的報警規則都會被自動繼承,因此在拓撲總覽頁面即可看到所有資源的健康狀態。
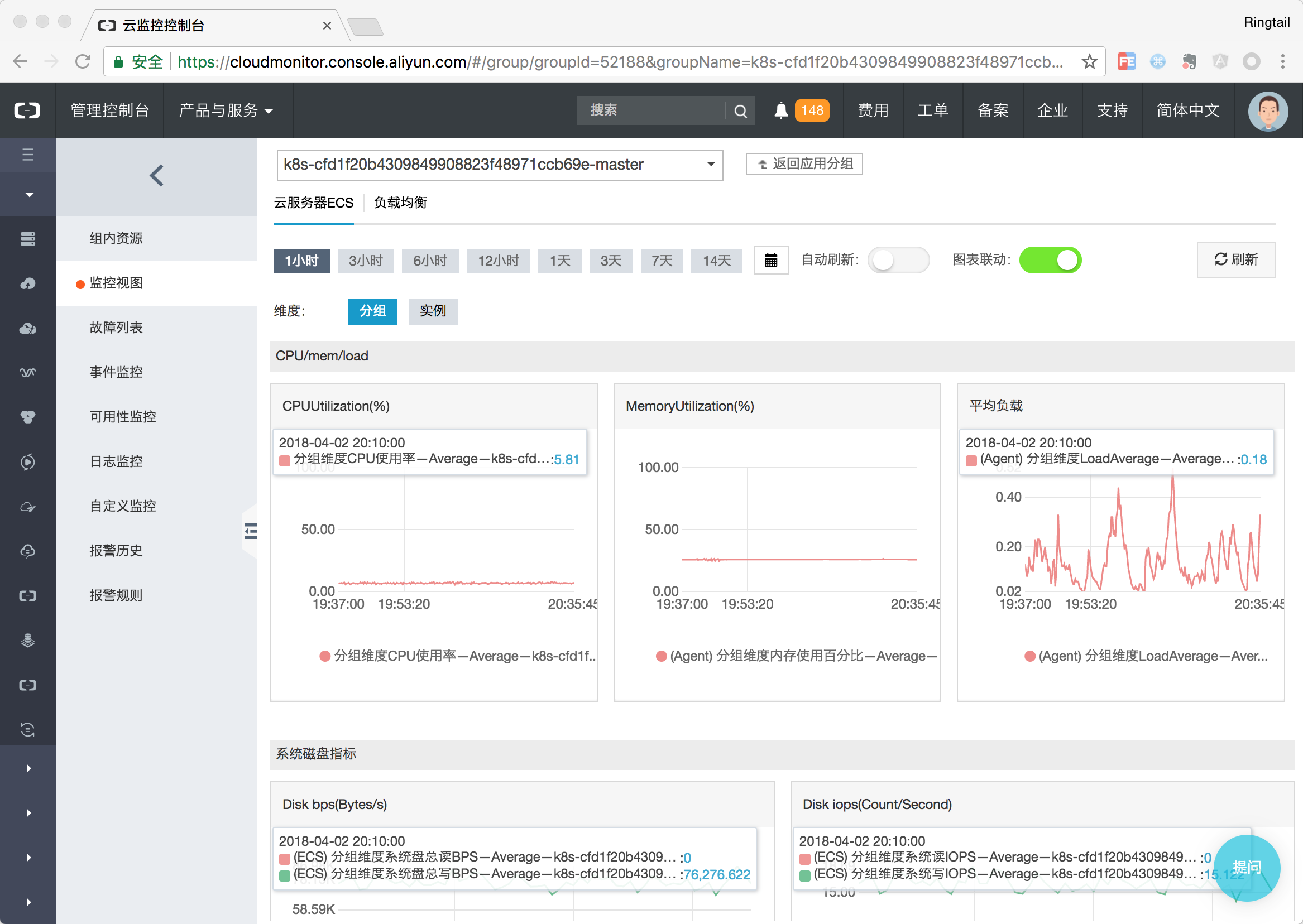
在監控檢視中可以詳細的在組級別以及例項級別檢視詳細的監控資料
對於Mater節點而言,其上執行的各種元件的健康狀態是更加重要的,因此在Master分組中設定了所有節點的核心元件的健康檢查,健康檢查狀態出現問題時即可通過釘釘、郵件、簡訊的方式在第一件獲取到Kubernetes的叢集狀態。
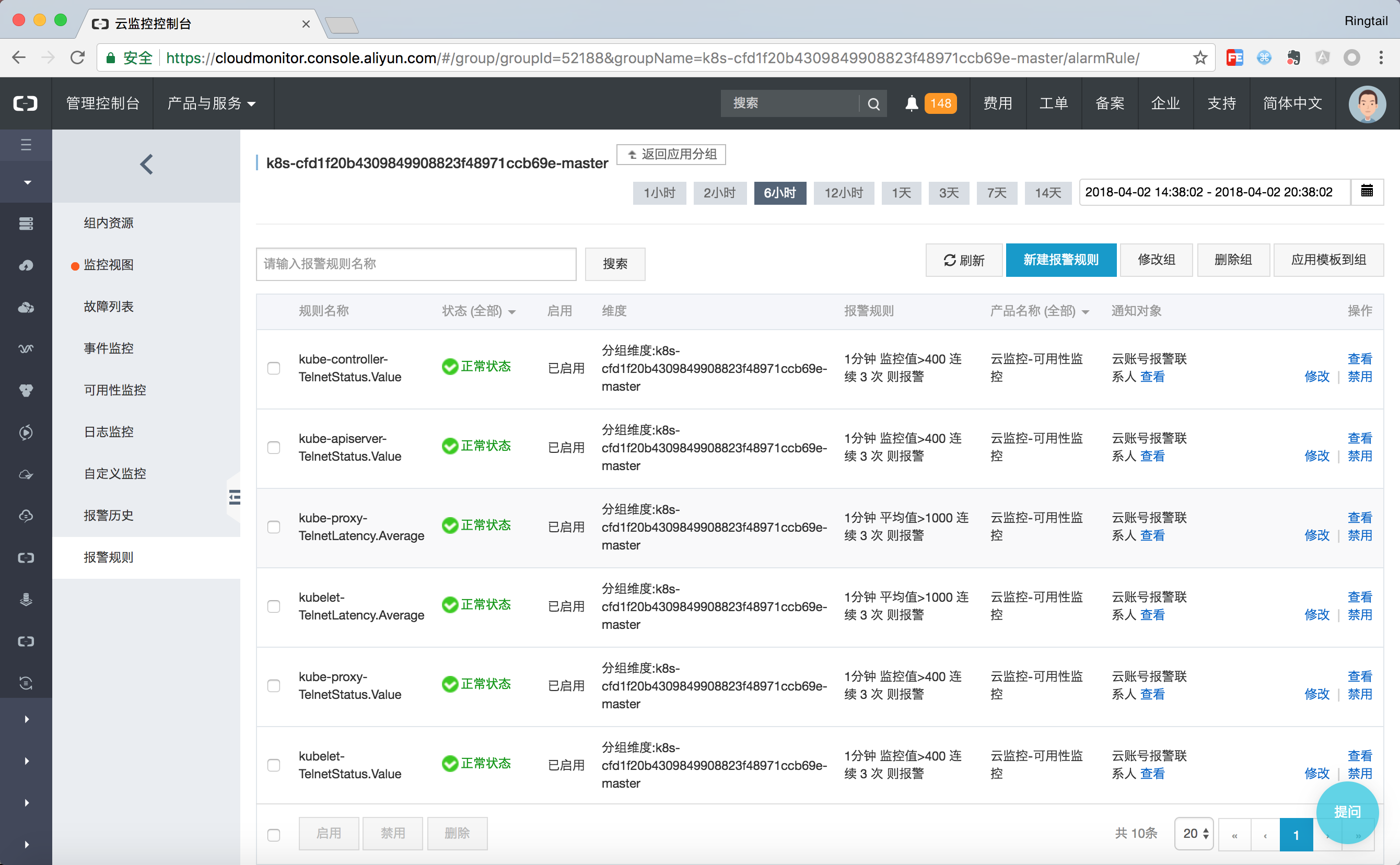
對於版本在1.8.4及以上的老叢集而言,可以通過升級監控服務的方式快速建立資源報警分組。對於資源組中的資源可以通過新建報警規則的方式設定自定義的報警,而報警規則會自動應用到資源組中,且在叢集自動伸縮等場景也會自動新增。
最後
本片文章我們講解了如何如何通過資源分組進行監控與告警,針對kubernetes的pod、service的監控也即將在4月份進行釋出,盡請期待。
閱讀更多幹貨好文,請關注掃描以下二維碼:
