
用python操作瀏覽器的三種方式
阿新 • • 發佈:2019-02-09
第一種:selenium匯入瀏覽器驅動,用get方法開啟瀏覽器,例如:
import time
from selenium import webdriver
def mac():
driver = webdriver.Firefox()
driver.implicitly_wait(5)
driver.get("http://huazhu.gag.com/mis/main.do")
第二種:通過匯入python的標準庫webbrowser開啟瀏覽器,例如:
>>> import webbrowser
>>> webbrowser.open("C:\\Program Files\\Internet Explorer\\iexplore.exe")
True
>>> webbrowser.open("C:\\Program Files\\Internet Explorer\\iexplore.exe")
True
第三種:使用Splinter模組模組
一、Splinter的安裝
Splinter的使用必修依靠Cython、lxml、selenium這三個軟體。所以,安裝前請提前安裝
Cython、lxml、selenium。以下給出連結地址:
1)http://download.csdn.net/detail/feisan/4301293
2)http://code.google.com/p/pythonxy/wiki/AdditionalPlugins#Installation_no
3)http://pypi.python.org/pypi/selenium/2.25.0#downloads
4)http://splinter.cobrateam.info/
二、Splinter的使用
這裡,我給出自動登入126郵箱的案例。難點是要找到頁面的賬戶、密碼、登入的頁面元素,這裡需要檢視126郵箱登入頁面的原始碼,才能找到相關控制元件的id.
例如:輸入密碼,密碼的文字控制元件id是pwdInput.可以使用browser.find_by_id()方法定位到密碼的文字框,
接著使用fill()方法,填寫密碼。至於模擬點選按鈕,也是要先找到按鈕控制元件的id,然後使用click()方法。
#coding=utf-8
import time
from splinter import Browser
def splinter(url):
browser = Browser()
#login 126 email websize
browser.visit(url)
#wait web element loading
time.sleep(5)
#fill in account and password
browser.find_by_id('idInput').fill('xxxxxx')
browser.find_by_id('pwdInput').fill('xxxxx')
#click the button of login
browser.find_by_id('loginBtn').click()
time.sleep(8)
#close the window of brower
browser.quit()
if __name__ == '__main__':
websize3 ='http://www.126.com'
splinter(websize3)
WebDriver簡介
selenium從2.0開始集成了webdriver的API,提供了更簡單,更簡潔的程式設計介面。selenium webdriver的目標是提供一個設計良好的面向物件的API,提供了更好的支援進行web-app測試。從這篇部落格開始,將學習使用如何使用python呼叫webdriver框架對瀏覽器進行一系列的操作
開啟瀏覽器
在selenium+python自動化測試(一)–環境搭建中,運行了一個測試指令碼,指令碼內容如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
print(driver.title)
driver.find_element_by_id("kw").send_keys("selenium")
driver.find_element_by_id("su").click()
time.sleep(3)
driver.close()
webdriver是一個Web應用程式測試自動化工具,用來驗證程式是否如預期的那樣執行。
webdriver.Chrome():建立一個Chrome瀏覽器的webdriver例項
driver.get(“http://www.baidu.com“):開啟”http://www.baidu.com“頁面
driver.find_element_by_id(“kw”).send_keys(“selenium”)
找到id為“kw”的元素,在這個頁面上為百度首頁的搜尋框,在其中輸入“selenium”
driver.find_element_by_id(“su”).click():找到id為“su”的元素並點選,在這個頁面上為百度首頁的“百度一下”按鈕
driver.close():退出瀏覽器
執行指令碼的第一步是開啟瀏覽器,使用webdriver.Chrome()開啟谷歌瀏覽器,如果要指定其他瀏覽器,比如要使用Firefox或者IE瀏覽器,更換瀏覽器名稱就可以了
driver = webdriver.Chrome() //開啟Chrome瀏覽器
driver = webdriver.Firefox() //開啟Firefox瀏覽器
driver = webdriver.Ie() //開啟IE瀏覽器
第二步操作是開啟頁面,使用driver.get(url)方法來開啟網頁連結,例如指令碼中開啟百度首頁
driver.get("http://www.baidu.com")
接下來是print(driver.title),使用driver.title獲取當前頁面的title,title就是在瀏覽器tab上顯示的內容,例如百度首頁的標題是“百度一下,你就知道”
瀏覽器前進後退
在當前頁面開啟一個新的連結後,如果想回退到前一個頁面,使用如下driver.back(),相當於點選了瀏覽器的後退按鈕
和back操作對應的是瀏覽器前進操作driver.forward(),相當於點選了瀏覽器的前進按鈕
driver.back() //回到上一個頁面
driver.forward() //切換到下一個頁面
瀏覽器執行後,如果頁面沒有最大化,可以呼叫driver.maximize_window()將瀏覽器最大化,相當於點選了頁面右上角的最大化按鈕
driver.maximize_window() //瀏覽器視窗最大化
driver.set_window_size(800, 720) //設定視窗大小為800*720
瀏覽器截圖操作,引數是截圖的圖片儲存路徑:
driver.get_screenshot_as_file("D:/data/test.png") 螢幕截圖儲存為***
driver.refresh() //重新載入頁面,頁面重新整理
在測試指令碼執行完後,一般會在最後關閉瀏覽器,有兩種方法關閉瀏覽器,close()方法用於關閉當前頁面,quit()方法關閉所有和當前測試有關的瀏覽器視窗
driver.close() //關閉當前頁面
driver.quit() //關閉所有由當前測試指令碼開啟的頁面
<h1 class="csdn_top" line-height:38px;color:#2c3033;padding:0px="" 29px;white-space:normal;"="" style="word-wrap: break-word; color: rgb(0, 0, 0); font-family: "sans serif", tahoma, verdana, helvetica; margin-top: 0px; margin-bottom: 0px; font-size: 24px;">頁面元素定位
要定位頁面元素,需要找到頁面的原始碼。
IE瀏覽器中,開啟頁面後,在頁面上點選滑鼠右鍵,會有“檢視原始碼”的選項,點選後就會進入頁面原始碼頁面,在這裡就可以找到頁面的所有元素
使用Chrome瀏覽器開啟頁面後,在瀏覽器的位址列右側有一個圖示,點選這個圖示後,會出現許多選單項,選擇更多工具裡的開發者工具,就會出現頁面的原始碼,不同版本的瀏覽器選單選項可能不同,但是都會在開發者工具裡找到頁面的原始碼
Firefox瀏覽器開啟頁面後,在右鍵選單裡也可以找到“檢視頁面原始碼”的選項。在Firefox中,可以使用瀏覽器自帶的外掛檢視定位元素,在Firefox的附加元件裡搜尋firebug進行下載,安裝firebug元件後會在瀏覽器的工具欄中多出一個小蟲子的圖示,點選這個圖示就可以開啟元件檢視頁面原始碼,開啟後如下圖所示
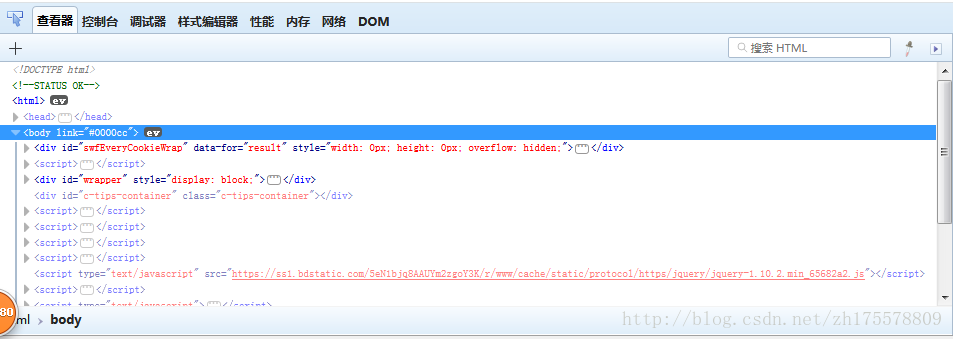
以百度首頁搜尋頁面為例,看一下webdriver定位元素的八種方式
使用id定位
在頁面原始碼中找到搜尋輸入框的元素定義
可以看到輸入框有一個有一個id的屬性,呼叫find_element_by_id()根據id屬性來找到元素,引數為屬性的值
input_search = driver.find_element_by_id("kw")
使用name定位
使用find_element_by_name()根據name屬性找到元素,引數為name屬性的值
搜尋框有一個name=”wd”的屬性,使用name查詢搜尋輸入框元素
input_search = driver.find_element_by_name("wd")
使用className定位
使用find_element_by_class_name()根據className屬性找到元素,引數為className屬性的值
搜尋框有一個class=”s_ipt”的屬性,使用className查詢元素
input_search = driver.find_element_by_class_name("s_ipt")
使用tagName定位
使用find_element_by_tag_name()根據tagName屬性找到元素,引數為元素標籤的名稱
每個頁面的元素都有一個tag,搜尋框的標籤為input,有時候一個頁面裡有許多相同的標籤,所以用這種方法找到的元素一般都不準確,除非這個元素使用的標籤在這個頁面裡是唯一的。一般不會使用這種方式來定位元素
input_search = driver.find_element_by_class_name("input")
使用link_text定位
頁面上都會有一些文字連結,點選連結後會開啟一個新的頁面,這些可以點選的連結可以使用find_element_by_link_text來定位,百度首頁上方有如下幾個元素

例如要定位“新聞”,找到元素的程式碼,有一個href的屬性,這是點選後開啟的頁面
新聞
使用link_text查詢元素,引數為元素的文字資訊
news = driver.find_element_by_link_text("新聞")
使用partial_link_text定位
這種方式類似於link_text的定位方式,如果一個元素的文字過長,不需要使用文字的所有資訊,可以使用其中的部分文字就可以定位
使用partial_link_text查詢百度首頁的“新聞”元素,引數為文字資訊,可以使用全部的文字,也可以使用部分文字
news = driver.find_element_by_link_text("新聞") //使用全部文字
news = driver.find_element_by_link_text("新") //使用部分文字
使用css selector定位
使用css屬性定位元素有多種方法,可以使用元素的id、name、className,也可以使用元素的其他屬性,如果一個元素沒有上述的幾種屬性或者定位不到時,可以使用css來定位
還是使用百度搜索框的例項來說明css定位的用法
css使用元素的id定位
css屬性使用id定位時,使用#號表示元素的id
input_search = driver.find_element_by_css_selector("#kw") //使用元素的id定位
css使用元素的class定位
css屬性使用class定位時,使用.號表示元素的class
input_search = driver.find_element_by_css_selector(".s_ipt") //使用元素的class定位
css使用元素的tag定位
css屬性使用tagName定位時,直接使用元素的標籤
input_search = driver.find_element_by_css_selector("input") //使用元素的tagName定位
css使用元素的其他屬性
除了上述3種屬性,css屬性可以使用元素的其他屬性定位,格式如下
input_search = driver.find_element_by_css_selector("[maxlength='255']")
使用元素的maxlength屬性定位
input_search = driver.find_element_by_css_selector("[autocomplete='off']")
使用元素的autocomplete屬性定位
可以在引數中加入元素的標籤名稱
input_search = driver.find_element_by_css_selector("input#kw") //使用元素的id定位
input_search = driver.find_element_by_css_selector("input.s_ipt") //使用元素的class定位
driver.find_element_by_css_selector("input[maxlength='255']") //使用元素的maxlength屬性定位
input_search = driver.find_element_by_css_selector("input[autocomplete='off']") //使用元素的autocomplete屬性定位
css的層級定位
當一個元素使用自身的屬性不容易定位時,可以通過它的父元素來找到它,如果父元素也不好定位,可以再通過上元素來定位,以此類推,一直找到容易定位的父元素為止,通過層級定位到需要查詢的元素
通過Firefox的firebug元件檢視百度首頁的原始碼
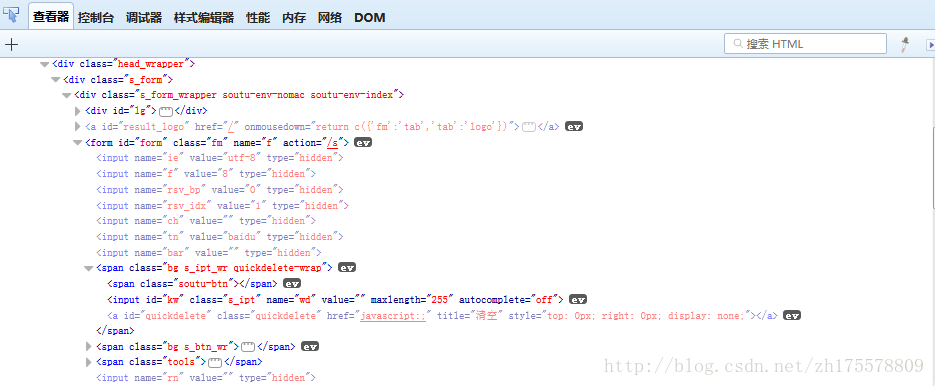
通過層級來定位搜尋框
input_search = driver.find_element_by_css_selector("form#form>span:nth-child(1)>input")
input_search = driver.find_element_by_css_selector("form.fm>span:nth-child(1)>input")
搜尋框的父元素為span標籤,span的父元素為form,form有id和class屬性,可以通過這兩個屬性來定位,找到form元素後,form下有多個span標籤,所以要使用span:nth-child(1),表示form下的第一個span標籤,這種用法很容易理解,表示第幾個孩子,最後是span下的input標籤,span下只有一個input,所以就可以定位到搜尋框
css邏輯運算
用一個屬性來定位元素時,如果有其他元素的屬性和此元素重複,可以組合多個屬性來功共同定位
組合多個屬性定位元素定位百度搜索框
input_search = driver.find_element_by_css_selector("input[id='kw'][name='wd']")
在元素內定義的屬性,都可以使用css來定位,使用其他幾種方式無法定位到元素時,可以使用css,夠強大!
使用xpath定位
import time
from selenium import webdriver
def mac():
driver = webdriver.Firefox()
driver.implicitly_wait(5)
driver.get("http://huazhu.gag.com/mis/main.do")
第二種:通過匯入python的標準庫webbrowser開啟瀏覽器,例如:
>>> import webbrowser
>>> webbrowser.open("C:\\Program Files\\Internet Explorer\\iexplore.exe")
True
>>> webbrowser.open("C:\\Program Files\\Internet Explorer\\iexplore.exe")
True
第三種:使用Splinter模組模組
一、Splinter的安裝
Splinter的使用必修依靠Cython、lxml、selenium這三個軟體。所以,安裝前請提前安裝
Cython、lxml、selenium。以下給出連結地址:
1)http://download.csdn.net/detail/feisan/4301293
2)http://code.google.com/p/pythonxy/wiki/AdditionalPlugins#Installation_no
3)http://pypi.python.org/pypi/selenium/2.25.0#downloads
4)http://splinter.cobrateam.info/
二、Splinter的使用
這裡,我給出自動登入126郵箱的案例。難點是要找到頁面的賬戶、密碼、登入的頁面元素,這裡需要檢視126郵箱登入頁面的原始碼,才能找到相關控制元件的id.
例如:輸入密碼,密碼的文字控制元件id是pwdInput.可以使用browser.find_by_id()方法定位到密碼的文字框,
接著使用fill()方法,填寫密碼。至於模擬點選按鈕,也是要先找到按鈕控制元件的id,然後使用click()方法。
#coding=utf-8
import time
from splinter import Browser
def splinter(url):
browser = Browser()
#login 126 email websize
browser.visit(url)
#wait web element loading
time.sleep(5)
#fill in account and password
browser.find_by_id('idInput').fill('xxxxxx')
browser.find_by_id('pwdInput').fill('xxxxx')
#click the button of login
browser.find_by_id('loginBtn').click()
time.sleep(8)
#close the window of brower
browser.quit()
if __name__ == '__main__':
websize3 ='http://www.126.com'
splinter(websize3)
WebDriver簡介
selenium從2.0開始集成了webdriver的API,提供了更簡單,更簡潔的程式設計介面。selenium webdriver的目標是提供一個設計良好的面向物件的API,提供了更好的支援進行web-app測試。從這篇部落格開始,將學習使用如何使用python呼叫webdriver框架對瀏覽器進行一系列的操作
開啟瀏覽器
在selenium+python自動化測試(一)–環境搭建中,運行了一個測試指令碼,指令碼內容如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
print(driver.title)
driver.find_element_by_id("kw").send_keys("selenium")
driver.find_element_by_id("su").click()
time.sleep(3)
driver.close()
webdriver是一個Web應用程式測試自動化工具,用來驗證程式是否如預期的那樣執行。
webdriver.Chrome():建立一個Chrome瀏覽器的webdriver例項
driver.get(“http://www.baidu.com“):開啟”http://www.baidu.com“頁面
driver.find_element_by_id(“kw”).send_keys(“selenium”)
找到id為“kw”的元素,在這個頁面上為百度首頁的搜尋框,在其中輸入“selenium”
driver.find_element_by_id(“su”).click():找到id為“su”的元素並點選,在這個頁面上為百度首頁的“百度一下”按鈕
driver.close():退出瀏覽器
執行指令碼的第一步是開啟瀏覽器,使用webdriver.Chrome()開啟谷歌瀏覽器,如果要指定其他瀏覽器,比如要使用Firefox或者IE瀏覽器,更換瀏覽器名稱就可以了
driver = webdriver.Chrome() //開啟Chrome瀏覽器
driver = webdriver.Firefox() //開啟Firefox瀏覽器
driver = webdriver.Ie() //開啟IE瀏覽器
第二步操作是開啟頁面,使用driver.get(url)方法來開啟網頁連結,例如指令碼中開啟百度首頁
driver.get("http://www.baidu.com")
接下來是print(driver.title),使用driver.title獲取當前頁面的title,title就是在瀏覽器tab上顯示的內容,例如百度首頁的標題是“百度一下,你就知道”
瀏覽器前進後退
在當前頁面開啟一個新的連結後,如果想回退到前一個頁面,使用如下driver.back(),相當於點選了瀏覽器的後退按鈕
和back操作對應的是瀏覽器前進操作driver.forward(),相當於點選了瀏覽器的前進按鈕
driver.back() //回到上一個頁面
driver.forward() //切換到下一個頁面
瀏覽器執行後,如果頁面沒有最大化,可以呼叫driver.maximize_window()將瀏覽器最大化,相當於點選了頁面右上角的最大化按鈕
driver.maximize_window() //瀏覽器視窗最大化
driver.set_window_size(800, 720) //設定視窗大小為800*720
瀏覽器截圖操作,引數是截圖的圖片儲存路徑:
driver.get_screenshot_as_file("D:/data/test.png") 螢幕截圖儲存為***
driver.refresh() //重新載入頁面,頁面重新整理
在測試指令碼執行完後,一般會在最後關閉瀏覽器,有兩種方法關閉瀏覽器,close()方法用於關閉當前頁面,quit()方法關閉所有和當前測試有關的瀏覽器視窗
driver.close() //關閉當前頁面
driver.quit() //關閉所有由當前測試指令碼開啟的頁面
<h1 class="csdn_top" line-height:38px;color:#2c3033;padding:0px="" 29px;white-space:normal;"="" style="word-wrap: break-word; color: rgb(0, 0, 0); font-family: "sans serif", tahoma, verdana, helvetica; margin-top: 0px; margin-bottom: 0px; font-size: 24px;">頁面元素定位
要定位頁面元素,需要找到頁面的原始碼。
IE瀏覽器中,開啟頁面後,在頁面上點選滑鼠右鍵,會有“檢視原始碼”的選項,點選後就會進入頁面原始碼頁面,在這裡就可以找到頁面的所有元素
使用Chrome瀏覽器開啟頁面後,在瀏覽器的位址列右側有一個圖示,點選這個圖示後,會出現許多選單項,選擇更多工具裡的開發者工具,就會出現頁面的原始碼,不同版本的瀏覽器選單選項可能不同,但是都會在開發者工具裡找到頁面的原始碼
Firefox瀏覽器開啟頁面後,在右鍵選單裡也可以找到“檢視頁面原始碼”的選項。在Firefox中,可以使用瀏覽器自帶的外掛檢視定位元素,在Firefox的附加元件裡搜尋firebug進行下載,安裝firebug元件後會在瀏覽器的工具欄中多出一個小蟲子的圖示,點選這個圖示就可以開啟元件檢視頁面原始碼,開啟後如下圖所示
以百度首頁搜尋頁面為例,看一下webdriver定位元素的八種方式
使用id定位
在頁面原始碼中找到搜尋輸入框的元素定義
可以看到輸入框有一個有一個id的屬性,呼叫find_element_by_id()根據id屬性來找到元素,引數為屬性的值
input_search = driver.find_element_by_id("kw")
使用name定位
使用find_element_by_name()根據name屬性找到元素,引數為name屬性的值
搜尋框有一個name=”wd”的屬性,使用name查詢搜尋輸入框元素
input_search = driver.find_element_by_name("wd")
使用className定位
使用find_element_by_class_name()根據className屬性找到元素,引數為className屬性的值
搜尋框有一個class=”s_ipt”的屬性,使用className查詢元素
input_search = driver.find_element_by_class_name("s_ipt")
使用tagName定位
使用find_element_by_tag_name()根據tagName屬性找到元素,引數為元素標籤的名稱
每個頁面的元素都有一個tag,搜尋框的標籤為input,有時候一個頁面裡有許多相同的標籤,所以用這種方法找到的元素一般都不準確,除非這個元素使用的標籤在這個頁面裡是唯一的。一般不會使用這種方式來定位元素
input_search = driver.find_element_by_class_name("input")
使用link_text定位
頁面上都會有一些文字連結,點選連結後會開啟一個新的頁面,這些可以點選的連結可以使用find_element_by_link_text來定位,百度首頁上方有如下幾個元素
例如要定位“新聞”,找到元素的程式碼,有一個href的屬性,這是點選後開啟的頁面
新聞
使用link_text查詢元素,引數為元素的文字資訊
news = driver.find_element_by_link_text("新聞")
使用partial_link_text定位
這種方式類似於link_text的定位方式,如果一個元素的文字過長,不需要使用文字的所有資訊,可以使用其中的部分文字就可以定位
使用partial_link_text查詢百度首頁的“新聞”元素,引數為文字資訊,可以使用全部的文字,也可以使用部分文字
news = driver.find_element_by_link_text("新聞") //使用全部文字
news = driver.find_element_by_link_text("新") //使用部分文字
使用css selector定位
使用css屬性定位元素有多種方法,可以使用元素的id、name、className,也可以使用元素的其他屬性,如果一個元素沒有上述的幾種屬性或者定位不到時,可以使用css來定位
還是使用百度搜索框的例項來說明css定位的用法
css使用元素的id定位
css屬性使用id定位時,使用#號表示元素的id
input_search = driver.find_element_by_css_selector("#kw") //使用元素的id定位
css使用元素的class定位
css屬性使用class定位時,使用.號表示元素的class
input_search = driver.find_element_by_css_selector(".s_ipt") //使用元素的class定位
css使用元素的tag定位
css屬性使用tagName定位時,直接使用元素的標籤
input_search = driver.find_element_by_css_selector("input") //使用元素的tagName定位
css使用元素的其他屬性
除了上述3種屬性,css屬性可以使用元素的其他屬性定位,格式如下
input_search = driver.find_element_by_css_selector("[maxlength='255']")
使用元素的maxlength屬性定位
input_search = driver.find_element_by_css_selector("[autocomplete='off']")
使用元素的autocomplete屬性定位
可以在引數中加入元素的標籤名稱
input_search = driver.find_element_by_css_selector("input#kw") //使用元素的id定位
input_search = driver.find_element_by_css_selector("input.s_ipt") //使用元素的class定位
driver.find_element_by_css_selector("input[maxlength='255']") //使用元素的maxlength屬性定位
input_search = driver.find_element_by_css_selector("input[autocomplete='off']") //使用元素的autocomplete屬性定位
css的層級定位
當一個元素使用自身的屬性不容易定位時,可以通過它的父元素來找到它,如果父元素也不好定位,可以再通過上元素來定位,以此類推,一直找到容易定位的父元素為止,通過層級定位到需要查詢的元素
通過Firefox的firebug元件檢視百度首頁的原始碼
通過層級來定位搜尋框
input_search = driver.find_element_by_css_selector("form#form>span:nth-child(1)>input")
input_search = driver.find_element_by_css_selector("form.fm>span:nth-child(1)>input")
搜尋框的父元素為span標籤,span的父元素為form,form有id和class屬性,可以通過這兩個屬性來定位,找到form元素後,form下有多個span標籤,所以要使用span:nth-child(1),表示form下的第一個span標籤,這種用法很容易理解,表示第幾個孩子,最後是span下的input標籤,span下只有一個input,所以就可以定位到搜尋框
css邏輯運算
用一個屬性來定位元素時,如果有其他元素的屬性和此元素重複,可以組合多個屬性來功共同定位
組合多個屬性定位元素定位百度搜索框
input_search = driver.find_element_by_css_selector("input[id='kw'][name='wd']")
在元素內定義的屬性,都可以使用css來定位,使用其他幾種方式無法定位到元素時,可以使用css,夠強大!
使用xpath定位
ASP.NET中 C#訪問資料庫用三種方式顯示資料表
第一種方式:使用DataReader從資料庫中每次提取一條資料,用迴圈遍歷表 下面是我寫的一個例子: &nbs
Python 指令碼的三種執行方式
1.互動模式下執行 Python,這種模式下,無需建立指令碼檔案,直接在 Python直譯器的互動模式下編寫對應的 Python 語句即可。 1)開啟互動模式的方式: Windows下: 在開始選單找到“命令提示符”,開啟,就進入到命令列模式: 在命令列模式輸入: python 即可進入